
Introduction
In the previous post we have discuss how important remote storage are for Prometheus. We have also covered several attention points. In the following post we are covering remote write storage and how to bench them.
Context
After you have identify one (or more) remote storage who might suit your must bench it. However it is not as straight forward as it seems. Let's review what we will need for this experiment:
- A (scalable) remote storage, in our case one which is remote write
- One or more data generator
Introducing Hachimon
Benchmarking is always fun but you know what is even more fun? Gamification! With my team mates we have created a short benchmark plan which we have called the Hachimon path:
To walk the Hachimon path we've built an infrastructure where only the central piece, the remote storage, changes. Doing so help us compare results.
The write path is stress by one or more Prometheus clusters which will scrap many time the same node_exporter under a different set of labels. Doing so allow us to emulate an infrastructure bigger than it is. To increase the cardinality we can tweak node_exporter configuration to expose more or less series. By deploying one or more Prometheus clusters we can both stress the deduplication feature of the backend and workaround the hardware limitation of a given prometheus.
This approach is very similar to the one of Victoriametrics which has inspired us. Kudos!
By the time we have reach the end of our tests the infrastucture we have built looks like the following:
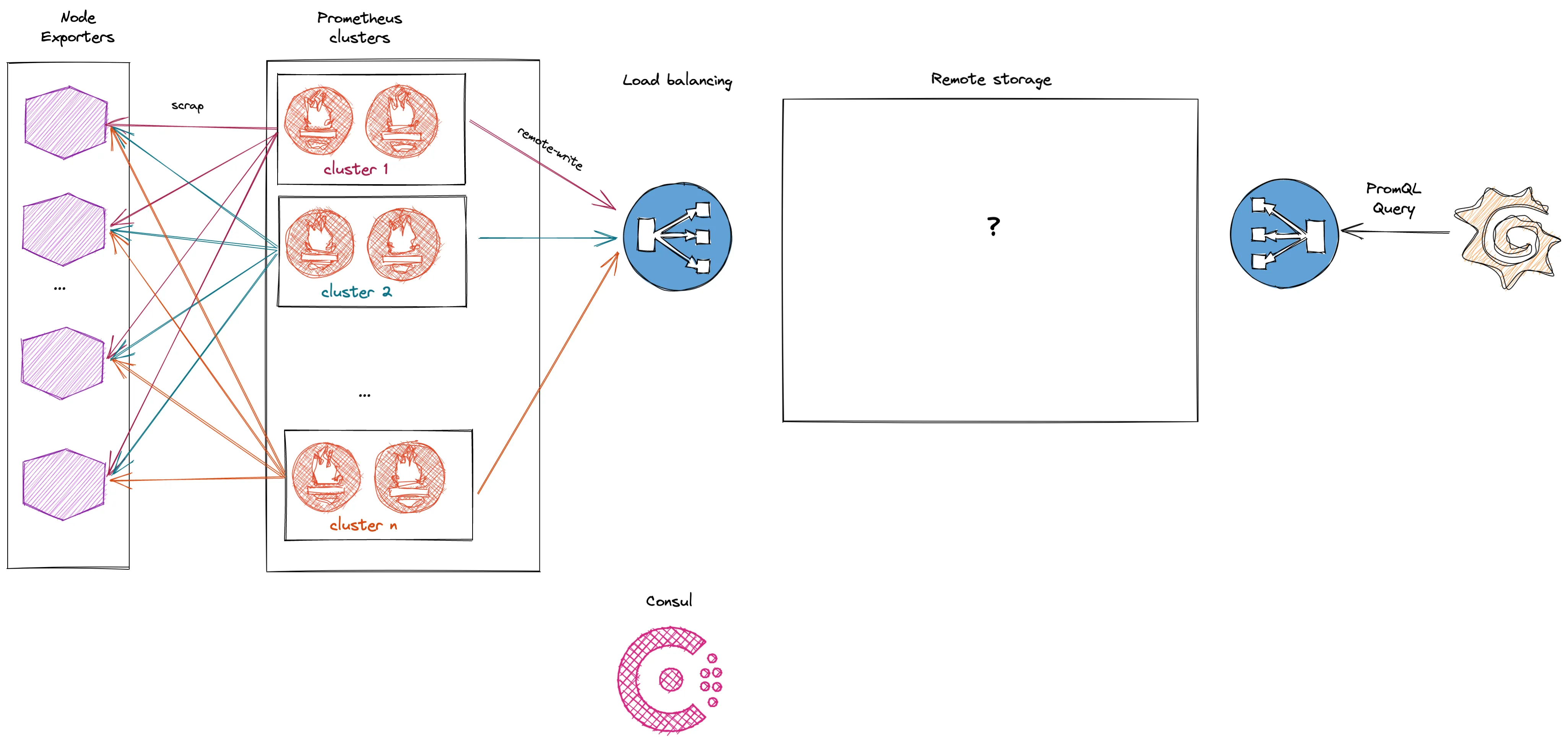
This is the infrastucture we have used to bench both the read and the write path of the remote storages. There is load balancing on both side, multiple pairs of Prometheus to put more or less pressure on the write path and the deduplication. Finally, the data comes from little instances exposing node_exporter metrics.
Expectation
Thanks to this benchmarking plan we have been able to differentiate the remote storage on a performance perspective. We've been able to get a first understanding about how each remote storage works, how to tune them and what can you done and what you cannot with them. It seems to us that it is equally important to have ease to operate a solution and good performance. But most importantly we learnt a lot of thing while having fun.
Conclusion
This benchmarking plan's s obviously flawned in many ways:
- it's expensive as you need to spawn more than necessary to assess a particular point of your remote storage.
- it's hard to reproduce 100% the same setup, even with the same configuration and software version you will have a similar result but not exactly the same.
- you're not always benchmarking what you think you are. We have spent couple of time troubleshoot performance issue which where in Prometheus or haproxy configuration.
- it focus mainly on the write path without stress from the read path which is not realistic.
The two next posts of this series continue to focus on benchmarking. The first one focus on the read performance.
The second one focus on how we should have benchmarked our solution from the beginning.
Stay tuned