
A tutorial to create and build your own Speech-To-Text Application with Python.
At the end of this third article, your Speech-To-Text Application will offer many new features such as speaker differentiation, summarization, video subtitles generation, audio trimming, and others!
Final code of the app is available in our dedicated GitHub repository.
Overview of our final Speech to Text Application
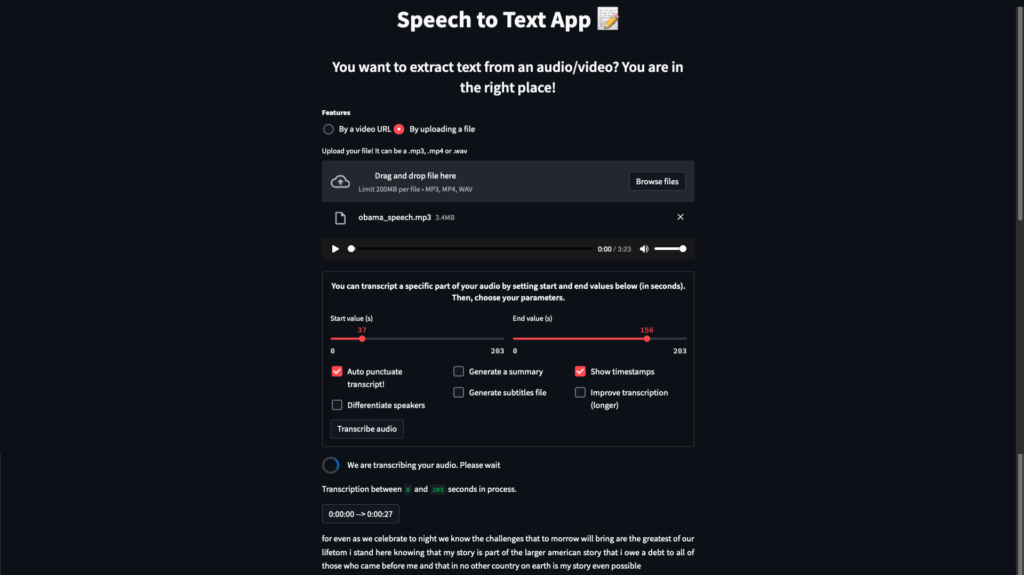
Overview of our final Speech-To-Text application
Objective
In the previous article, we have created a form where the user can select the options he wants to interact with.
Now that this form is created, it’s time to deploy the features!
This article is organized as follows:
- Trim an audio
- Puntuate the transcript
- Differentiate speakers with diarization
- Display the transcript correctly
- Rename speakers
- Create subtitles for videos (.SRT)
- Update old code
⚠️ Since this article uses code already explained in the previous notebook tutorials, we will not re-explained its usefulness here. We therefore recommend that you read the notebooks first.
Trim an audio ✂️
The first option we are going to add add is to be able to trim an audio file.
Indeed, if the user’s audio file is several minutes long, it is possible that the user only wants to transcribe a part of it to save some time. This is where the sliders of our form become useful. They allow the user to change default start & end values, which determine which part of the audio file is transcribed.
For example, if the user’s file is 10 minutes long, the user can use the sliders to indicate that he only wants to transcribe the [00:30 -> 02:30] part, instead of the full audio file.
⚠️ With this functionality, we must check the values set by the user! Indeed, imagine that the user selects an end value which is lower than the start one (ex : transcript would starts from start=40s to end=20s), this would be problematic.
This is why you need to add the following function to your code, to rectify the potential errors:
def correct_values(start, end, audio_length):
"""
Start or/and end value(s) can be in conflict, so we check these values
:param start: int value (s) given by st.slider() (fixed by user)
:param end: int value (s) given by st.slider() (fixed by user)
:param audio_length: audio duration (s)
:return: approved values
"""
# Start & end Values need to be checked
if start >= audio_length or start >= end:
start = 0
st.write("Start value has been set to 0s because of conflicts with other values")
if end > audio_length or end == 0:
end = audio_length
st.write("End value has been set to maximum value because of conflicts with other values")
return start, endIf one of the values has been changed, we immediately inform the user with a st.write().
We will call this function in the transcription() function, that we will rewrite at the end of this tutorial.
Split a text
If you have read the notebooks, you probably remember that some models (punctuation & summarization) have input size limitations.
Let’s reuse the split_text() function, used in the notebooks, which will allow to send our whole transcript to these models by small text blocks, limited to a max_size number of characters:
def split_text(my_text, max_size):
"""
Split a text
Maximum sequence length for this model is max_size.
If the transcript is longer, it needs to be split by the nearest possible value to max_size.
To avoid cutting words, we will cut on "." characters, and " " if there is not "."
:return: split text
"""
cut2 = max_size
# First, we get indexes of "."
my_split_text_list = []
nearest_index = 0
length = len(my_text)
# We split the transcript in text blocks of size <= max_size.
if cut2 == length:
my_split_text_list.append(my_text)
else:
while cut2 <= length:
cut1 = nearest_index
cut2 = nearest_index + max_size
# Find the best index to split
dots_indexes = [index for index, char in enumerate(my_text[cut1:cut2]) if
char == "."]
if dots_indexes != []:
nearest_index = max(dots_indexes) + 1 + cut1
else:
spaces_indexes = [index for index, char in enumerate(my_text[cut1:cut2]) if
char == " "]
if spaces_indexes != []:
nearest_index = max(spaces_indexes) + 1 + cut1
else:
nearest_index = cut2 + cut1
my_split_text_list.append(my_text[cut1: nearest_index])
return my_split_text_listPunctuate the transcript
Now, we need to add the function that allows us to send a transcript to the punctuation model in order to punctuate it:
def add_punctuation(t5_model, t5_tokenizer, transcript):
"""
Punctuate a transcript
transcript: string limited to 512 characters
:return: Punctuated and improved (corrected) transcript
"""
input_text = "fix: { " + transcript + " } </s>"
input_ids = t5_tokenizer.encode(input_text, return_tensors="pt", max_length=10000, truncation=True,
add_special_tokens=True)
outputs = t5_model.generate(
input_ids=input_ids,
max_length=256,
num_beams=4,
repetition_penalty=1.0,
length_penalty=1.0,
early_stopping=True
)
transcript = t5_tokenizer.decode(outputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)
return transcriptThe punctuation feature is now ready. We will call these functions later.
For the summarization model, you don’t have to do anything else either.
Differentiate speakers with diarization
Now, let’s reuse all the diarization functions studied in the notebook tutorials, so we can differentiate speakers during a conversation.
Convert mp3/mp4 files to .wav
Remember pyannote’s diarization only accepts .wav files as input.
def convert_file_to_wav(aud_seg, filename):
"""
Convert a mp3/mp4 in a wav format
Needs to be modified if you want to convert a format which contains less or more than 3 letters
:param aud_seg: pydub.AudioSegment
:param filename: name of the file
:return: name of the converted file
"""
filename = "../data/my_wav_file_" + filename[:-3] + "wav"
aud_seg.export(filename, format="wav")
newaudio = AudioSegment.from_file(filename)
return newaudio, filenameGet diarization of an audio file
The following function allows you to diarize an andio file.
def get_diarization(dia_pipeline, filename):
"""
Diarize an audio (find numbers of speakers, when they speak, ...)
:param dia_pipeline: Pyannote's library (diarization pipeline)
:param filename: name of a wav audio file
:return: str list containing audio's diarization time intervals
"""
# Get diarization of the audio
diarization = dia_pipeline({'audio': filename})
listmapping = diarization.labels()
listnewmapping = []
# Rename default speakers' names (Default is A, B, ...), we want Speaker0, Speaker1, ...
number_of_speakers = len(listmapping)
for i in range(number_of_speakers):
listnewmapping.append("Speaker" + str(i))
mapping_dict = dict(zip(listmapping, listnewmapping))
diarization.rename_labels(mapping_dict, copy=False)
# copy set to False so we don't create a new annotation, we replace the actual on
return diarization, number_of_speakersConvert diarization results to timedelta objects
This conversion makes it easy to manipulate the results.
def convert_str_diarlist_to_timedelta(diarization_result):
"""
Extract from Diarization result the given speakers with their respective speaking times and transform them in pandas timedelta objects
:param diarization_result: result of diarization
:return: list with timedelta intervals and their respective speaker
"""
# get speaking intervals from diarization
segments = diarization_result.for_json()["content"]
diarization_timestamps = []
for sample in segments:
# Convert segment in a pd.Timedelta object
new_seg = [pd.Timedelta(seconds=round(sample["segment"]["start"], 2)),
pd.Timedelta(seconds=round(sample["segment"]["end"], 2)), sample["label"]]
# Start and end = speaking duration
# label = who is speaking
diarization_timestamps.append(new_seg)
return diarization_timestampsMerge the diarization segments that follow each other and that mention the same speaker
This will reduce the number of audio segments we need to create, and will give less sequenced, less small transcripts, which will be more pleasant for the user.
def merge_speaker_times(diarization_timestamps, max_space, srt_token):
"""
Merge near times for each detected speaker (Same speaker during 1-2s and 3-4s -> Same speaker during 1-4s)
:param diarization_timestamps: diarization list
:param max_space: Maximum temporal distance between two silences
:param srt_token: Enable/Disable generate srt file (choice fixed by user)
:return: list with timedelta intervals and their respective speaker
"""
if not srt_token:
threshold = pd.Timedelta(seconds=max_space/1000)
index = 0
length = len(diarization_timestamps) - 1
while index < length:
if diarization_timestamps[index + 1][2] == diarization_timestamps[index][2] and \
diarization_timestamps[index + 1][1] - threshold <= diarization_timestamps[index][0]:
diarization_timestamps[index][1] = diarization_timestamps[index + 1][1]
del diarization_timestamps[index + 1]
length -= 1
else:
index += 1
return diarization_timestampsExtend timestamps given by the diarization to avoid word cutting
Imagine we have a segment like [00:01:20 –> 00:01:25], followed by [00:01:27 –> 00:01:30].
Maybe diarization is not working fine and there is some sound missing in the segments (means missing sound is between 00:01:25 and 00:01:27). The transcription model will then have difficulty understanding what is being said in these segments.
➡️ Solution consists in fixing the end of the first segment and the start of the second one to 00:01:26, the middle of these values.
def extending_timestamps(new_diarization_timestamps):
"""
Extend timestamps between each diarization timestamp if possible, so we avoid word cutting
:param new_diarization_timestamps: list
:return: list with merged times
"""
for i in range(1, len(new_diarization_timestamps)):
if new_diarization_timestamps[i][0] - new_diarization_timestamps[i - 1][1] <= timedelta(milliseconds=3000) and new_diarization_timestamps[i][0] - new_diarization_timestamps[i - 1][1] >= timedelta(milliseconds=100):
middle = (new_diarization_timestamps[i][0] - new_diarization_timestamps[i - 1][1]) / 2
new_diarization_timestamps[i][0] -= middle
new_diarization_timestamps[i - 1][1] += middle
# Converting list so we have a milliseconds format
for elt in new_diarization_timestamps:
elt[0] = elt[0].total_seconds() * 1000
elt[1] = elt[1].total_seconds() * 1000
return new_diarization_timestampsCreate & Optimize the subtitles
Some people tend to speak naturally very quickly. Also, conversations can sometimes be heated. In both of these cases, there is a good chance that the transcribed text is very dense, and not suitable for displaying subtitles (too much text displayed does not allow to see the video anymore).
We will therefore define the following function. Its role will be to split a speech segment in 2, if the length of the text is judged too long.
def optimize_subtitles(transcription, srt_index, sub_start, sub_end, srt_text):
"""
Optimize the subtitles (avoid a too long reading when many words are said in a short time)
:param transcription: transcript generated for an audio chunk
:param srt_index: Numeric counter that identifies each sequential subtitle
:param sub_start: beginning of the transcript
:param sub_end: end of the transcript
:param srt_text: generated .srt transcript
"""
transcription_length = len(transcription)
# Length of the transcript should be limited to about 42 characters per line to avoid this problem
if transcription_length > 42:
# Split the timestamp and its transcript in two parts
# Get the middle timestamp
diff = (timedelta(milliseconds=sub_end) - timedelta(milliseconds=sub_start)) / 2
middle_timestamp = str(timedelta(milliseconds=sub_start) + diff).split(".")[0]
# Get the closest middle index to a space (we don't divide transcription_length/2 to avoid cutting a word)
space_indexes = [pos for pos, char in enumerate(transcription) if char == " "]
nearest_index = min(space_indexes, key=lambda x: abs(x - transcription_length / 2))
# First transcript part
first_transcript = transcription[:nearest_index]
# Second transcript part
second_transcript = transcription[nearest_index + 1:]
# Add both transcript parts to the srt_text
srt_text += str(srt_index) + "\n" + str(timedelta(milliseconds=sub_start)).split(".")[0] + " --> " + middle_timestamp + "\n" + first_transcript + "\n\n"
srt_index += 1
srt_text += str(srt_index) + "\n" + middle_timestamp + " --> " + str(timedelta(milliseconds=sub_end)).split(".")[0] + "\n" + second_transcript + "\n\n"
srt_index += 1
else:
# Add transcript without operations
srt_text += str(srt_index) + "\n" + str(timedelta(milliseconds=sub_start)).split(".")[0] + " --> " + str(timedelta(milliseconds=sub_end)).split(".")[0] + "\n" + transcription + "\n\n"
return srt_text, srt_indexGlobal function which performs the whole diarization action
This function just calls all the previous diarization functions to perform it
def diarization_treatment(filename, dia_pipeline, max_space, srt_token):
"""
Launch the whole diarization process to get speakers time intervals as pandas timedelta objects
:param filename: name of the audio file
:param dia_pipeline: Diarization Model (Differentiate speakers)
:param max_space: Maximum temporal distance between two silences
:param srt_token: Enable/Disable generate srt file (choice fixed by user)
:return: speakers time intervals list and number of different detected speakers
"""
# initialization
diarization_timestamps = []
# whole diarization process
diarization, number_of_speakers = get_diarization(dia_pipeline, filename)
if len(diarization) > 0:
diarization_timestamps = convert_str_diarlist_to_timedelta(diarization)
diarization_timestamps = merge_speaker_times(diarization_timestamps, max_space, srt_token)
diarization_timestamps = extending_timestamps(diarization_timestamps)
return diarization_timestamps, number_of_speakersLaunch diarization mode
Previously, we were systematically running the transcription_non_diarization() function, which is based on the silence detection method.
But now that the user has the option to select the diarization option in the form, it is time to write our transcription_diarization() function.
The only difference between the two is that we replace the silences treatment by the treatment of the results of diarization.
def transcription_diarization(filename, diarization_timestamps, stt_model, stt_tokenizer, diarization_token, srt_token,
summarize_token, timestamps_token, myaudio, start, save_result, txt_text, srt_text):
"""
Performs transcription with the diarization mode
:param filename: name of the audio file
:param diarization_timestamps: timestamps of each audio part (ex 10 to 50 secs)
:param stt_model: Speech to text model
:param stt_tokenizer: Speech to text model's tokenizer
:param diarization_token: Differentiate or not the speakers (choice fixed by user)
:param srt_token: Enable/Disable generate srt file (choice fixed by user)
:param summarize_token: Summarize or not the transcript (choice fixed by user)
:param timestamps_token: Display and save or not the timestamps (choice fixed by user)
:param myaudio: AudioSegment file
:param start: int value (s) given by st.slider() (fixed by user)
:param save_result: whole process
:param txt_text: generated .txt transcript
:param srt_text: generated .srt transcript
:return: results of transcribing action
"""
# Numeric counter that identifies each sequential subtitle
srt_index = 1
# Handle a rare case : Only the case if only one "list" in the list (it makes a classic list) not a list of list
if not isinstance(diarization_timestamps[0], list):
diarization_timestamps = [diarization_timestamps]
# Transcribe each audio chunk (from timestamp to timestamp) and display transcript
for index, elt in enumerate(diarization_timestamps):
sub_start = elt[0]
sub_end = elt[1]
transcription = transcribe_audio_part(filename, stt_model, stt_tokenizer, myaudio, sub_start, sub_end,
index)
# Initial audio has been split with start & end values
# It begins to 0s, but the timestamps need to be adjust with +start*1000 values to adapt the gap
if transcription != "":
save_result, txt_text, srt_text, srt_index = display_transcription(diarization_token, summarize_token,
srt_token, timestamps_token,
transcription, save_result, txt_text,
srt_text,
srt_index, sub_start + start * 1000,
sub_end + start * 1000, elt)
return save_result, txt_text, srt_textThe display_transcription() function returns 3 values for the moment, contrary to what we have just indicated in the transcription_diarization() function. Don’t worry, we will fix the display_transcription() function in a few moments.
You will also need the function below. It will allow the user to validate his access token to the diarization model and access the home page of our app. Indeed, we are going to create another page by default, which will invite the user to enter his token, if he wishes.
def confirm_token_change(hf_token, page_index):
"""
A function that saves the hugging face token entered by the user.
It also updates the page index variable so we can indicate we now want to display the home page instead of the token page
:param hf_token: user's token
:param page_index: number that represents the home page index (mentioned in the main.py file)
"""
update_session_state("my_HF_token", hf_token)
update_session_state("page_index", page_index)Display the transcript correctly
Once the transcript is obtained, we must display it correctly, depending on the options the user has selected.
For example, if the user has activated diarization, we need to write the identified speaker before each transcript, like the following result:
Speaker1 : “I would like a cup of tea”
This is different from a classic silences detection method, which only writes the transcript, without any names!
There is the same case with the timestamps. We must know if we need to display them or not. We then have 4 different cases:
- diarization with timestamps, named DIA_TS
- diarization without timestamps, named DIA
- non_diarization with timestamps, named NODIA_TS
- non_diarization without timestamps, named NODIA
To display the correct elements according to the chosen mode, let’s modify the display_transcription() function.
Replace the old one by the following code:
def display_transcription(diarization_token, summarize_token, srt_token, timestamps_token, transcription, save_result, txt_text, srt_text, srt_index, sub_start, sub_end, elt=None):
"""
Display results
:param diarization_token: Differentiate or not the speakers (choice fixed by user)
:param summarize_token: Summarize or not the transcript (choice fixed by user)
:param srt_token: Enable/Disable generate srt file (choice fixed by user)
:param timestamps_token: Display and save or not the timestamps (choice fixed by user)
:param transcription: transcript of the considered audio
:param save_result: whole process
:param txt_text: generated .txt transcript
:param srt_text: generated .srt transcript
:param srt_index : numeric counter that identifies each sequential subtitle
:param sub_start: start value (s) of the considered audio part to transcribe
:param sub_end: end value (s) of the considered audio part to transcribe
:param elt: timestamp (diarization case only, otherwise elt = None)
"""
# Display will be different depending on the mode (dia, no dia, dia_ts, nodia_ts)
# diarization mode
if diarization_token:
if summarize_token:
update_session_state("summary", transcription + " ", concatenate_token=True)
if not timestamps_token:
temp_transcription = elt[2] + " : " + transcription
st.write(temp_transcription + "\n\n")
save_result.append([int(elt[2][-1]), elt[2], " : " + transcription])
elif timestamps_token:
temp_timestamps = str(timedelta(milliseconds=sub_start)).split(".")[0] + " --> " + \
str(timedelta(milliseconds=sub_end)).split(".")[0] + "\n"
temp_transcription = elt[2] + " : " + transcription
temp_list = [temp_timestamps, int(elt[2][-1]), elt[2], " : " + transcription, int(sub_start / 1000)]
save_result.append(temp_list)
st.button(temp_timestamps, on_click=click_timestamp_btn, args=(sub_start,))
st.write(temp_transcription + "\n\n")
if srt_token:
srt_text, srt_index = optimize_subtitles(transcription, srt_index, sub_start, sub_end, srt_text)
# Non diarization case
else:
if not timestamps_token:
save_result.append([transcription])
st.write(transcription + "\n\n")
else:
temp_timestamps = str(timedelta(milliseconds=sub_start)).split(".")[0] + " --> " + \
str(timedelta(milliseconds=sub_end)).split(".")[0] + "\n"
temp_list = [temp_timestamps, transcription, int(sub_start / 1000)]
save_result.append(temp_list)
st.button(temp_timestamps, on_click=click_timestamp_btn, args=(sub_start,))
st.write(transcription + "\n\n")
if srt_token:
srt_text, srt_index = optimize_subtitles(transcription, srt_index, sub_start, sub_end, srt_text)
txt_text += transcription + " " # So x seconds sentences are separated
return save_result, txt_text, srt_text, srt_indexWe also need to add the following function which allow us to create our txt_text variable from the st.session.state[‘process’] variable in a diarization case. This is necessary because, in addition to displaying the spoken sentence which means the transcript part, we must display the identity of the speaker, and eventually the timestamps, which are all stored in the session state variable.
def create_txt_text_from_process(punctuation_token=False, t5_model=None, t5_tokenizer=None):
"""
If we are in a diarization case (differentiate speakers), we create txt_text from st.session.state['process']
There is a lot of information in the process variable, but we only extract the identity of the speaker and
the sentence spoken, as in a non-diarization case.
:param punctuation_token: Punctuate or not the transcript (choice fixed by user)
:param t5_model: T5 Model (Auto punctuation model)
:param t5_tokenizer: T5’s Tokenizer (Auto punctuation model's tokenizer)
:return: Final transcript (without timestamps)
"""
txt_text = ""
# The information to be extracted is different according to the chosen mode
if punctuation_token:
with st.spinner("Transcription is finished! Let us punctuate your audio"):
if st.session_state["chosen_mode"] == "DIA":
for elt in st.session_state["process"]:
# [2:] don't want ": text" but only the "text"
text_to_punctuate = elt[2][2:]
if len(text_to_punctuate) >= 512:
text_to_punctutate_list = split_text(text_to_punctuate, 512)
punctuated_text = ""
for split_text_to_punctuate in text_to_punctutate_list:
punctuated_text += add_punctuation(t5_model, t5_tokenizer, split_text_to_punctuate)
else:
punctuated_text = add_punctuation(t5_model, t5_tokenizer, text_to_punctuate)
txt_text += elt[1] + " : " + punctuated_text + '\n\n'
elif st.session_state["chosen_mode"] == "DIA_TS":
for elt in st.session_state["process"]:
text_to_punctuate = elt[3][2:]
if len(text_to_punctuate) >= 512:
text_to_punctutate_list = split_text(text_to_punctuate, 512)
punctuated_text = ""
for split_text_to_punctuate in text_to_punctutate_list:
punctuated_text += add_punctuation(t5_model, t5_tokenizer, split_text_to_punctuate)
else:
punctuated_text = add_punctuation(t5_model, t5_tokenizer, text_to_punctuate)
txt_text += elt[2] + " : " + punctuated_text + '\n\n'
else:
if st.session_state["chosen_mode"] == "DIA":
for elt in st.session_state["process"]:
txt_text += elt[1] + elt[2] + '\n\n'
elif st.session_state["chosen_mode"] == "DIA_TS":
for elt in st.session_state["process"]:
txt_text += elt[2] + elt[3] + '\n\n'
return txt_textAlso for the purpose of correct display, we need to update the display_results() function so that it adapts the display to the selected mode among DIA_TS, DIA, NODIA_TS, NODIA. This will also avoid ‘List index out of range’ errors, as the process variable does not contain the same number of elements depending on the mode used.
# Update the following function code
def display_results():
# Add a button to return to the main page
st.button("Load an other file", on_click=update_session_state, args=("page_index", 0,))
# Display results
st.audio(st.session_state['audio_file'], start_time=st.session_state["start_time"])
# Display results of transcript by steps
if st.session_state["process"] != []:
if st.session_state["chosen_mode"] == "NODIA": # Non diarization, non timestamps case
for elt in (st.session_state['process']):
st.write(elt[0])
elif st.session_state["chosen_mode"] == "DIA": # Diarization without timestamps case
for elt in (st.session_state['process']):
st.write(elt[1] + elt[2])
elif st.session_state["chosen_mode"] == "NODIA_TS": # Non diarization with timestamps case
for elt in (st.session_state['process']):
st.button(elt[0], on_click=update_session_state, args=("start_time", elt[2],))
st.write(elt[1])
elif st.session_state["chosen_mode"] == "DIA_TS": # Diarization with timestamps case
for elt in (st.session_state['process']):
st.button(elt[0], on_click=update_session_state, args=("start_time", elt[4],))
st.write(elt[2] + elt[3])
# Display final text
st.subheader("Final text is")
st.write(st.session_state["txt_transcript"])
# Display Summary
if st.session_state["summary"] != "":
with st.expander("Summary"):
st.write(st.session_state["summary"])
# Display the buttons in a list to avoid having empty columns (explained in the transcription() function)
col1, col2, col3, col4 = st.columns(4)
col_list = [col1, col2, col3, col4]
col_index = 0
for elt in st.session_state["btn_token_list"]:
if elt[0]:
mycol = col_list[col_index]
if elt[1] == "useless_txt_token":
# Download your transcription.txt
with mycol:
st.download_button("Download as TXT", st.session_state["txt_transcript"],
file_name="my_transcription.txt")
elif elt[1] == "srt_token":
# Download your transcription.srt
with mycol:
st.download_button("Download as SRT", st.session_state["srt_txt"], file_name="my_transcription.srt")
elif elt[1] == "dia_token":
with mycol:
# Rename the speakers detected in your audio
st.button("Rename Speakers", on_click=update_session_state, args=("page_index", 2,))
elif elt[1] == "summarize_token":
with mycol:
st.download_button("Download Summary", st.session_state["summary"], file_name="my_summary.txt")
col_index += 1We then display 4 buttons that allow you to interact with the implemented functions (download the transcript in .txt format, in .srt, download the summary, and rename the speakers.
These buttons are placed in 4 columns which allows them to be displayed in one line. The problem is that these options are sometimes enabled and sometimes not. If we assign a button to a column, we risk having an empty column among the four columns, which would not be aesthetically pleasing.
This is where the token_list comes in! This is a list of list which contains in each of its indexes a list, having for first element the value of the token, and in second its denomination. For example, we can find in the token_list the following list: [True, “dia_token”], which means that diarization option has been selected.
From this, we can assign a button to a column only if it contains an token set to True. If the token is set to False, we will retry to use this column for the next token. This avoids creating an empty column.
Rename Speakers
Of course, it would be interesting to have the possibility to rename the detected speakers in the audio file. Indeed, having Speaker0, Speaker1, … is fine but it could be so much better with real names! Guess what? We are going to do this!
First, we will create a list where we will add each speaker with his ‘ID’ (ex: Speaker1 has 1 as his ID).
Unfortunately, the diarization does not sort out the interlocutors. For example, the first one detected might be Speaker3, followed by Speaker0, then Speaker2. This is why it is important to sort this list, for example by placing the lowest ID as the first element of our list. This will allow not to exchange names between speakers.
Once this is done, we need to find a way for the user to interact with this list and modify the names contained in it.
➡️ We are going to create a third page that will be dedicated to this functionality. On this page, we will display each name contained in the list in a st.text_area() widget. The user will be able to see how many people have been detected in his audio and the automatic names (Speaker0, Speaker1, …) that have been assigned to them, as the screen below shows:

The user is able to modify this text area. Indeed, he can replace each name with the oneche wants but he must respect the one name per line format. When he has finished, he can save his modifications by clicking a “Save changes” button, which calls the callback function click_confirm_rename_btn() that we will define just after. We also display a “Cancel” button that will redirect the user to the results page.
All this process is realized by the rename_speakers_window() function. Add it to your code:
def rename_speakers_window():
"""
Load a new page which allows the user to rename the different speakers from the diarization process
For example he can switch from "Speaker1 : "I wouldn't say that"" to "Mat : "I wouldn't say that""
"""
st.subheader("Here you can rename the speakers as you want")
number_of_speakers = st.session_state["number_of_speakers"]
if number_of_speakers > 0:
# Handle displayed text according to the number_of_speakers
if number_of_speakers == 1:
st.write(str(number_of_speakers) + " speaker has been detected in your audio")
else:
st.write(str(number_of_speakers) + " speakers have been detected in your audio")
# Saving the Speaker Name and its ID in a list, example : [1, 'Speaker1']
list_of_speakers = []
for elt in st.session_state["process"]:
if st.session_state["chosen_mode"] == "DIA_TS":
if [elt[1], elt[2]] not in list_of_speakers:
list_of_speakers.append([elt[1], elt[2]])
elif st.session_state["chosen_mode"] == "DIA":
if [elt[0], elt[1]] not in list_of_speakers:
list_of_speakers.append([elt[0], elt[1]])
# Sorting (by ID)
list_of_speakers.sort() # [[1, 'Speaker1'], [0, 'Speaker0']] => [[0, 'Speaker0'], [1, 'Speaker1']]
# Display saved names so the user can modify them
initial_names = ""
for elt in list_of_speakers:
initial_names += elt[1] + "\n"
names_input = st.text_area("Just replace the names without changing the format (one per line)",
value=initial_names)
# Display Options (Cancel / Save)
col1, col2 = st.columns(2)
with col1:
# Cancel changes by clicking a button - callback function to return to the results page
st.button("Cancel", on_click=update_session_state, args=("page_index", 1,))
with col2:
# Confirm changes by clicking a button - callback function to apply changes and return to the results page
st.button("Save changes", on_click=click_confirm_rename_btn, args=(names_input, number_of_speakers, ))
# Don't have anyone to rename
else:
st.error("0 speakers have been detected. Seem there is an issue with diarization")
with st.spinner("Redirecting to transcription page"):
time.sleep(4)
# return to the results page
update_session_state("page_index", 1)Now, write the callback function that is called when the “Save changes” button is clicked. It allows to save the new speaker’s names in the process session state variable and to recreate the displayed text with the new names given by the user thanks to the previously defined function create_txt_text_from_process(). Finally, it redirects the user to the results page.
def click_confirm_rename_btn(names_input, number_of_speakers):
"""
If the users decides to rename speakers and confirms his choices, we apply the modifications to our transcript
Then we return to the results page of the app
:param names_input: string
:param number_of_speakers: Number of detected speakers in the audio file
"""
try:
names_input = names_input.split("\n")[:number_of_speakers]
for elt in st.session_state["process"]:
elt[2] = names_input[elt[1]]
txt_text = create_txt_text_from_process()
update_session_state("txt_transcript", txt_text)
update_session_state("page_index", 1)
except TypeError: # list indices must be integers or slices, not str (happened to me one time when writing non sense names)
st.error("Please respect the 1 name per line format")
with st.spinner("We are relaunching the page"):
time.sleep(3)
update_session_state("page_index", 1)Create subtitles for videos (.SRT)
Idea is very simple here, process is the same as before. We just have in this case to shorten the timestamps by adjusting the min_space and the max_space values, so we have a good video-subtitles synchronization.
Indeed, remember that subtitles must correspond to small time windows to have small synchronized transcripts. Otherwise, there will be too much text. That’s why we set the min_space to 1s and the max_space to 8s instead of the classic min: 25s and max: 45s values.
def silence_mode_init(srt_token):
"""
Fix min_space and max_space values
If the user wants a srt file, we need to have tiny timestamps
:param srt_token: Enable/Disable generate srt file option (choice fixed by user)
:return: min_space and max_space values
"""
if srt_token:
# We need short intervals if we want a short text
min_space = 1000 # 1 sec
max_space = 8000 # 8 secs
else:
min_space = 25000 # 25 secs
max_space = 45000 # 45secs
return min_space, max_spaceUpdate old code
As we have a lot new parameters (diarization_token, timestamps_token, summarize_token, …) in our display_transcription() function, we need to update our transcription_non_diarization() function so it can interact with these new parameters and display the transcript correctly.
def transcription_non_diarization(filename, myaudio, start, end, diarization_token, timestamps_token, srt_token,
summarize_token, stt_model, stt_tokenizer, min_space, max_space, save_result,
txt_text, srt_text):
"""
Performs transcribing action with the non-diarization mode
:param filename: name of the audio file
:param myaudio: AudioSegment file
:param start: int value (s) given by st.slider() (fixed by user)
:param end: int value (s) given by st.slider() (fixed by user)
:param diarization_token: Differentiate or not the speakers (choice fixed by user)
:param timestamps_token: Display and save or not the timestamps (choice fixed by user)
:param srt_token: Enable/Disable generate srt file (choice fixed by user)
:param summarize_token: Summarize or not the transcript (choice fixed by user)
:param stt_model: Speech to text model
:param stt_tokenizer: Speech to text model's tokenizer
:param min_space: Minimum temporal distance between two silences
:param max_space: Maximum temporal distance between two silences
:param save_result: whole process
:param txt_text: generated .txt transcript
:param srt_text: generated .srt transcript
:return: results of transcribing action
"""
# Numeric counter identifying each sequential subtitle
srt_index = 1
# get silences
silence_list = detect_silences(myaudio)
if silence_list != []:
silence_list = get_middle_silence_time(silence_list)
silence_list = silences_distribution(silence_list, min_space, max_space, start, end, srt_token)
else:
silence_list = generate_regular_split_till_end(silence_list, int(end), min_space, max_space)
# Transcribe each audio chunk (from timestamp to timestamp) and display transcript
for i in range(0, len(silence_list) - 1):
sub_start = silence_list[i]
sub_end = silence_list[i + 1]
transcription = transcribe_audio_part(filename, stt_model, stt_tokenizer, myaudio, sub_start, sub_end, i)
# Initial audio has been split with start & end values
# It begins to 0s, but the timestamps need to be adjust with +start*1000 values to adapt the gap
if transcription != "":
save_result, txt_text, srt_text, srt_index = display_transcription(diarization_token, summarize_token,
srt_token, timestamps_token,
transcription, save_result,
txt_text,
srt_text,
srt_index, sub_start + start * 1000,
sub_end + start * 1000)
return save_result, txt_text, srt_textAlso, you need to add these new parameters to the transcript_from_url() and transcript_from_files() functions.
def transcript_from_url(stt_tokenizer, stt_model, t5_tokenizer, t5_model, summarizer, dia_pipeline):
"""
Displays a text input area, where the user can enter a YouTube URL link. If the link seems correct, we try to
extract the audio from the video, and then transcribe it.
:param stt_tokenizer: Speech to text model's tokenizer
:param stt_model: Speech to text model
:param t5_tokenizer: Auto punctuation model's tokenizer
:param t5_model: Auto punctuation model
:param summarizer: Summarizer model
:param dia_pipeline: Diarization Model (Differentiate speakers)
"""
url = st.text_input("Enter the YouTube video URL then press Enter to confirm!")
# If link seems correct, we try to transcribe
if "youtu" in url:
filename = extract_audio_from_yt_video(url)
if filename is not None:
transcription(stt_tokenizer, stt_model, t5_tokenizer, t5_model, summarizer, dia_pipeline, filename)
else:
st.error("We were unable to extract the audio. Please verify your link, retry or choose another video")def transcript_from_file(stt_tokenizer, stt_model, t5_tokenizer, t5_model, summarizer, dia_pipeline):
"""
Displays a file uploader area, where the user can import his own file (mp3, mp4 or wav). If the file format seems
correct, we transcribe the audio.
"""
# File uploader widget with a callback function, so the page reloads if the users uploads a new audio file
uploaded_file = st.file_uploader("Upload your file! It can be a .mp3, .mp4 or .wav", type=["mp3", "mp4", "wav"],
on_change=update_session_state, args=("page_index", 0,))
if uploaded_file is not None:
# get name and launch transcription function
filename = uploaded_file.name
transcription(stt_tokenizer, stt_model, t5_tokenizer, t5_model, summarizer, dia_pipeline, filename, uploaded_file)Everything is almost ready, you can finally update the transcription() function so it can call all the new methods we have defined:
def transcription(stt_tokenizer, stt_model, t5_tokenizer, t5_model, summarizer, dia_pipeline, filename,
uploaded_file=None):
"""
Mini-main function
Display options, transcribe an audio file and save results.
:param stt_tokenizer: Speech to text model's tokenizer
:param stt_model: Speech to text model
:param t5_tokenizer: Auto punctuation model's tokenizer
:param t5_model: Auto punctuation model
:param summarizer: Summarizer model
:param dia_pipeline: Diarization Model (Differentiate speakers)
:param filename: name of the audio file
:param uploaded_file: file / name of the audio file which allows the code to reach the file
"""
# If the audio comes from the Youtube extraction mode, the audio is downloaded so the uploaded_file is
# the same as the filename. We need to change the uploaded_file which is currently set to None
if uploaded_file is None:
uploaded_file = filename
# Get audio length of the file(s)
myaudio = AudioSegment.from_file(uploaded_file)
audio_length = myaudio.duration_seconds
# Save Audio (so we can display it on another page ("DISPLAY RESULTS"), otherwise it is lost)
update_session_state("audio_file", uploaded_file)
# Display audio file
st.audio(uploaded_file)
# Is transcription possible
if audio_length > 0:
# We display options and user shares his wishes
transcript_btn, start, end, diarization_token, punctuation_token, timestamps_token, srt_token, summarize_token, choose_better_model = load_options(
int(audio_length), dia_pipeline)
# If end value hasn't been changed, we fix it to the max value so we don't cut some ms of the audio because
# end value is returned by a st.slider which return end value as a int (ex: return 12 sec instead of end=12.9s)
if end == int(audio_length):
end = audio_length
# Switching model for the better one
if choose_better_model:
with st.spinner("We are loading the better model. Please wait..."):
try:
stt_tokenizer = pickle.load(open("models/STT_tokenizer2_wav2vec2-large-960h-lv60-self.sav", 'rb'))
except FileNotFoundError:
stt_tokenizer = Wav2Vec2Tokenizer.from_pretrained("facebook/wav2vec2-large-960h-lv60-self")
try:
stt_model = pickle.load(open("models/STT_model2_wav2vec2-large-960h-lv60-self.sav", 'rb'))
except FileNotFoundError:
stt_model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60-self")
# Validate options and launch the transcription process thanks to the form's button
if transcript_btn:
# Check if start & end values are correct
start, end = correct_values(start, end, audio_length)
# If start a/o end value(s) has/have changed, we trim/cut the audio according to the new start/end values.
if start != 0 or end != audio_length:
myaudio = myaudio[start * 1000:end * 1000] # Works in milliseconds (*1000)
# Transcribe process is running
with st.spinner("We are transcribing your audio. Please wait"):
# Initialize variables
txt_text, srt_text, save_result = init_transcription(start, int(end))
min_space, max_space = silence_mode_init(srt_token)
# Differentiate speakers mode
if diarization_token:
# Save mode chosen by user, to display expected results
if not timestamps_token:
update_session_state("chosen_mode", "DIA")
elif timestamps_token:
update_session_state("chosen_mode", "DIA_TS")
# Convert mp3/mp4 to wav (Differentiate speakers mode only accepts wav files)
if filename.endswith((".mp3", ".mp4")):
myaudio, filename = convert_file_to_wav(myaudio, filename)
else:
filename = "../data/" + filename
myaudio.export(filename, format="wav")
# Differentiate speakers process
diarization_timestamps, number_of_speakers = diarization_treatment(filename, dia_pipeline,
max_space, srt_token)
# Saving the number of detected speakers
update_session_state("number_of_speakers", number_of_speakers)
# Transcribe process with Diarization Mode
save_result, txt_text, srt_text = transcription_diarization(filename, diarization_timestamps,
stt_model,
stt_tokenizer,
diarization_token,
srt_token, summarize_token,
timestamps_token, myaudio, start,
save_result,
txt_text, srt_text)
# Non Diarization Mode
else:
# Save mode chosen by user, to display expected results
if not timestamps_token:
update_session_state("chosen_mode", "NODIA")
if timestamps_token:
update_session_state("chosen_mode", "NODIA_TS")
filename = "../data/" + filename
# Transcribe process with non Diarization Mode
save_result, txt_text, srt_text = transcription_non_diarization(filename, myaudio, start, end,
diarization_token, timestamps_token,
srt_token, summarize_token,
stt_model, stt_tokenizer,
min_space, max_space,
save_result, txt_text, srt_text)
# Save results so it is not lost when we interact with a button
update_session_state("process", save_result)
update_session_state("srt_txt", srt_text)
# Get final text (with or without punctuation token)
# Diariation Mode
if diarization_token:
# Create txt text from the process
txt_text = create_txt_text_from_process(punctuation_token, t5_model, t5_tokenizer)
# Non diarization Mode
else:
if punctuation_token:
# Need to split the text by 512 text blocks size since the model has a limited input
with st.spinner("Transcription is finished! Let us punctuate your audio"):
my_split_text_list = split_text(txt_text, 512)
txt_text = ""
# punctuate each text block
for my_split_text in my_split_text_list:
txt_text += add_punctuation(t5_model, t5_tokenizer, my_split_text)
# Clean folder's files
clean_directory("../data")
# Display the final transcript
if txt_text != "":
st.subheader("Final text is")
# Save txt_text and display it
update_session_state("txt_transcript", txt_text)
st.markdown(txt_text, unsafe_allow_html=True)
# Summarize the transcript
if summarize_token:
with st.spinner("We are summarizing your audio"):
# Display summary in a st.expander widget to don't write too much text on the page
with st.expander("Summary"):
# Need to split the text by 1024 text blocks size since the model has a limited input
if diarization_token:
# in diarization mode, the text to summarize is contained in the "summary" the session state variable
my_split_text_list = split_text(st.session_state["summary"], 1024)
else:
# in non-diarization mode, it is contained in the txt_text variable
my_split_text_list = split_text(txt_text, 1024)
summary = ""
# Summarize each text block
for my_split_text in my_split_text_list:
summary += summarizer(my_split_text)[0]['summary_text']
# Removing multiple spaces and double spaces around punctuation mark " . "
summary = re.sub(' +', ' ', summary)
summary = re.sub(r'\s+([?.!"])', r'\1', summary)
# Display summary and save it
st.write(summary)
update_session_state("summary", summary)
# Display buttons to interact with results
# We have 4 possible buttons depending on the user's choices. But we can't set 4 columns for 4
# buttons. Indeed, if the user displays only 3 buttons, it is possible that one of the column
# 1, 2 or 3 is empty which would be ugly. We want the activated options to be in the first columns
# so that the empty columns are not noticed. To do that, let's create a btn_token_list
btn_token_list = [[diarization_token, "dia_token"], [True, "useless_txt_token"],
[srt_token, "srt_token"], [summarize_token, "summarize_token"]]
# Save this list to be able to reach it on the other pages of the app
update_session_state("btn_token_list", btn_token_list)
# Create 4 columns
col1, col2, col3, col4 = st.columns(4)
# Create a column list
col_list = [col1, col2, col3, col4]
# Check value of each token, if True, we put the respective button of the token in a column
col_index = 0
for elt in btn_token_list:
if elt[0]:
mycol = col_list[col_index]
if elt[1] == "useless_txt_token":
# Download your transcript.txt
with mycol:
st.download_button("Download as TXT", txt_text, file_name="my_transcription.txt",
on_click=update_session_state, args=("page_index", 1,))
elif elt[1] == "srt_token":
# Download your transcript.srt
with mycol:
update_session_state("srt_token", srt_token)
st.download_button("Download as SRT", srt_text, file_name="my_transcription.srt",
on_click=update_session_state, args=("page_index", 1,))
elif elt[1] == "dia_token":
with mycol:
# Rename the speakers detected in your audio
st.button("Rename Speakers", on_click=update_session_state, args=("page_index", 2,))
elif elt[1] == "summarize_token":
with mycol:
# Download the summary of your transcript.txt
st.download_button("Download Summary", st.session_state["summary"],
file_name="my_summary.txt",
on_click=update_session_state, args=("page_index", 1,))
col_index += 1
else:
st.write("Transcription impossible, a problem occurred with your audio or your parameters, "
"we apologize :(")
else:
st.error("Seems your audio is 0 s long, please change your file")
time.sleep(3)
st.stop()Finally, update the main code of the python file, which allows to navigate between the different pages of our application (token, home, results and rename pages):
from app import *
if __name__ == '__main__':
config()
if st.session_state['page_index'] == -1:
# Specify token page (mandatory to use the diarization option)
st.warning('You must specify a token to use the diarization model. Otherwise, the app will be launched without this model. You can learn how to create your token here: https://huggingface.co/pyannote/speaker-diarization')
text_input = st.text_input("Enter your Hugging Face token:", placeholder="ACCESS_TOKEN_GOES_HERE", type="password")
# Confirm or continue without the option
col1, col2 = st.columns(2)
# save changes button
with col1:
confirm_btn = st.button("I have changed my token", on_click=confirm_token_change, args=(text_input, 0), disabled=st.session_state["disable"])
# if text is changed, button is clickable
if text_input != "ACCESS_TOKEN_GOES_HERE":
st.session_state["disable"] = False
# Continue without a token (there will be no diarization option)
with col2:
dont_mind_btn = st.button("Continue without this option", on_click=update_session_state, args=("page_index", 0))
if st.session_state['page_index'] == 0:
# Home page
choice = st.radio("Features", ["By a video URL", "By uploading a file"])
stt_tokenizer, stt_model, t5_tokenizer, t5_model, summarizer, dia_pipeline = load_models()
if choice == "By a video URL":
transcript_from_url(stt_tokenizer, stt_model, t5_tokenizer, t5_model, summarizer, dia_pipeline)
elif choice == "By uploading a file":
transcript_from_file(stt_tokenizer, stt_model, t5_tokenizer, t5_model, summarizer, dia_pipeline)
elif st.session_state['page_index'] == 1:
# Results page
display_results()
elif st.session_state['page_index'] == 2:
# Rename speakers page
rename_speakers_window()The idea is the following:
The user arrives at the token page (whose index is -1). He is invited to enter his diarization access token into a text_input() widget. These instructions are given to him by a st.warning(). He can then choose to enter his token and click the confirm_btn, which will then be clickable. But he can also choose not to use this option by clicking on the dont_mind button. In both cases, the variabel page_index will be updated to 0, and the application will then display the home page that will allow the user to transcribe his files.
In this logic, you will understand that the session variable page_index must no longer be initialized to 0 (index of the home page), but to -1, in order to load the token page. For that, modify its initialization in the config() function:
# Modify the page_index initialization in the config() function
def config():
# ....
if 'page_index' not in st.session_state:
st.session_state['page_index'] = -1 Conclusion
Congratulations! Your Speech to Text Application is now full of features. Now it’s time to have fun with!
You can transcribe audio files, videos, with or without punctuation. You can also generate synchronized subtitles. You have also discovered how to differentiate speakers thanks to diarization, in order to follow a conversation more easily.
➡️ To significantly reduce the initialization time of the app and the execution time of the transcribing, we recommend that you deploy your speech to text app on powerful GPU ressources with AI Deploy. To learn how to do it, please refer to this documentation.

I am anengineering student who has been working at OVHcloud for a few months. I am familiar with several computer languages, but within my studies, I specialized in artificial intelligence and Python is therefore my main working tool.
It is a growing field that allows me to discover and understand things, to create but also as you see to explain them :)!