
You are probably already familiar with our managed Kubernetes offer, and the comfort provided by not having to manage administration.
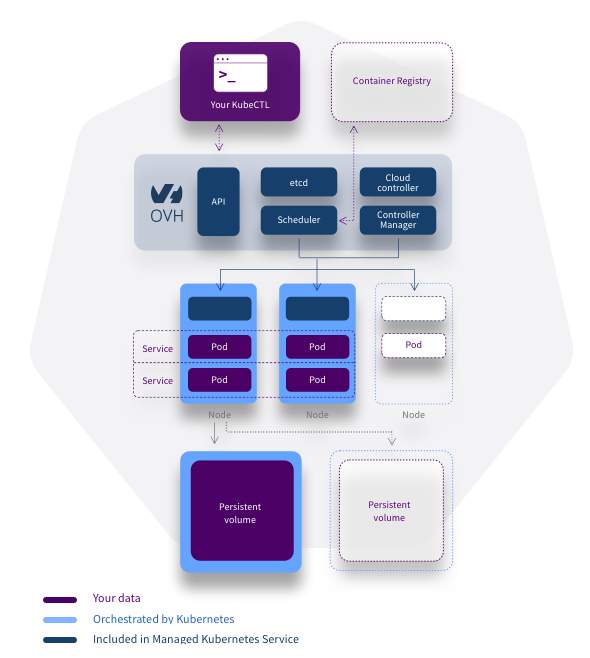
But what is your backup and restore strategy?
It is important to be aware that in the event of failure of your infrastructure other than those related to the engine, you are responsible for your backups and restores.
What scenarios exist for a Kubernetes cluster?
You have the choice, and there is no universal answer to this question, because everything will depend on your strategy and your organization.
In the event of a functional or technical failure, your strategy may be to rebuild everything from your sources, on a freshly created Kubernetes cluster.
This rollback strategy will be even more effective if your organization practices the DevOps principle of “Shift Left”, which implies that your developers are responsible for deployments via a policy based on infra-as-code.
There are potentially a few downsides to this backup/restore method.
Indeed, the life cycle of your resources can cause a difference between the definition of these and their real assignments in the cluster.
The role of Kubernetes is to be able to manage your resources, and transform them as needed depending on the load or third-party events.
Take the example of a Kubernetes API update, your resources will be automatically updated with the new version, but the initial definition of your resource will become obsolete without your intervention.
Another example, if among the Kubernetes ecosystem you use tools such as kyverno or OPA Gatekeeper, you will have discrepancies between the definition of your resources and their deployment, which will complicate the restoration.
Alternatively, you can assign this restore task to people within the Ops role in your organization.
In this case, the approach will be rather “system”, that is to say decorrelated from the business, the restoration strategy will be the restoration to a state at time T of the technical environment, often resulting from an image capture, called a snapshot.
To achieve this result, various tools are now recognized for backing up and restoring your Kubernetes cluster. Some examples:
– Trilio
– Velero
– Stash
Our managed Kubernetes offer today does not offer an integrated backup solution, because, as we have seen, there are too many strategies and organizations.

A few months ago, the company Trilio came to offer us, via a Pull Request (PR) on our public documentation space, a very complete tutorial on the installation of their Triliovault for Kubernetes product on our managed Kubernetes offer.
After some technical discussions on implementation and formatting, we were pleased to add this tutorial to our official documentation:

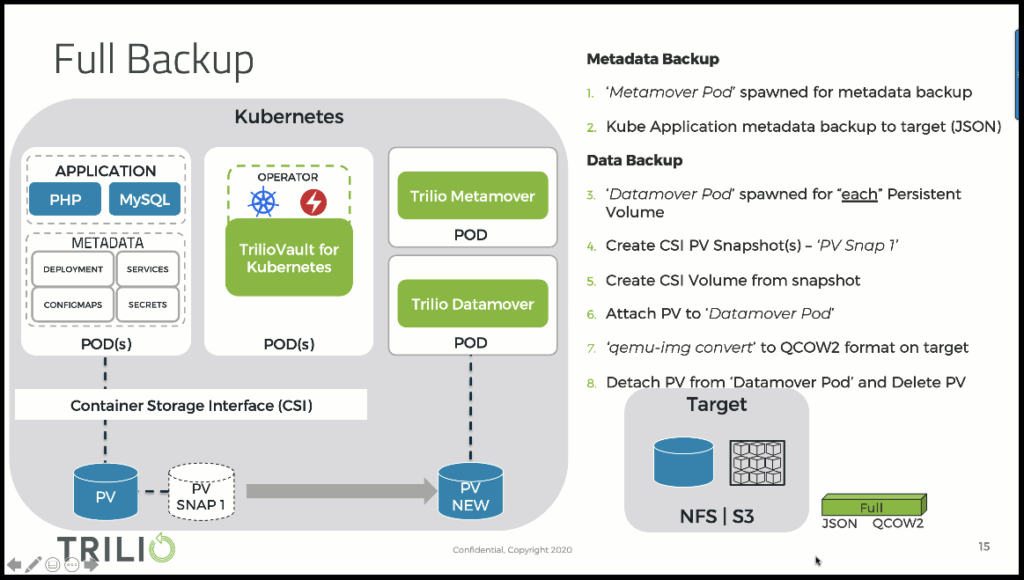
To summarize very succinctly what Triliovault for Kubernetes offers us, here is a simple diagram.
See the complete Trilio documentation
The tool backs up resources first and makes snapshots of physical volumes. The backed up data is stored in an Object Storage such as S3.
Saved resources can be filtered, by namespaces, services, etc.
The administration of the tool is done either by applying manifest files or via a web console.
If we look at Trilio’s offer, we see that the Triliovault for Kubernetes tool adapts to many cloud platforms: OpenShift/OKD, Rancher (RKE1/RKE2), K3S, EKS, AKS, GKE, TKG, MKE, Digital Ocean and of course OVHcloud.
Ref: Compatibility matrix
We greatly appreciated working together on this PR, as it was done without any commercial or strategic agreements.
For our part, we are committed to offering the best Kubernetes service to our customers, and Trilio to ensuring that this environment is secure.
A fine example of complementarity technologies and alignment of objectives.
The story does not end there, then, because in a week at the time of writing this article, we have the opportunity to meet “in the flesh” at Valencia Spain, on the occasion of the Kubecon Europe 2022.
If you are therefore interested in our respective offers and would like to see a demo, this is the perfect opportunity!
Developer Evangelist at OVH, Spaniard lost in Brittany, speaker, coder, dreamer and all-around geek.His job is all around the technical communities: developers, devops, ops... He writes blog posts, prepares tutorials, organizes events, speaks at conferences and meetups...