
One of the largely touted benefits of the Cloud, is that users can get on-demand access to compute resources, and be charged only for the time they have used them. GPU is one of these resources, and given its cost, the on-demand and pay-as-you-go consumption model is particularly relevant.

Let’ say, for an AI-based application, you want to use GPU to make some experiment, design a prototype or start your business: You get the GPU resources as you need them, and pay only for what you have used. The technology you need is readily accessible, thus shortening your time-to-market, while you don’t have any upfront investment.
In this light, this post will review the different ways at your disposal, to consume GPU-powered services in our Public Cloud, and highlight how to leverage them in the context of building data-intensive, AI-based application.
GPU(s) are a great fit for AI workloads
As its name states it, Graphical Processing Unit’s straightforward goal is to efficiently manipulate computer graphics and image processing. GPUs are equipped with many cores, provide high throughput, thus have much better ability than CPUs to efficiently perform parallel computing tasks and process thousands of operations at once. These capabilities can apply to many use cases ranging from gaming to high performance computing, but more notably to AI.
In short, thanks to its ability to process multiple computations simultaneously, GPUs have greatly answered the needs for Data scientists: for instance when training a Deep Learning model in conjunction with large data sets, doing it with a GPU can be completed in a few hours, while it could last for weeks with a CPU.

GPU-based instances: Our T2 instances
The first way to use GPU in our Public Cloud is our GPU instances. What you get is a Virtual Machine, that you can provision on-demand, manage through APIs, and whose CPU resources (vCore, RAM) are dedicated to you. But most of all, you get GPU resources, from one to four Nvidia Tesla cards, delivered directly to the instance via PCI Passthrough: As there is no virtualization layer, your AI-application workloads can directly access the GPU, get the whole available computing power and benefit from outstanding performance.
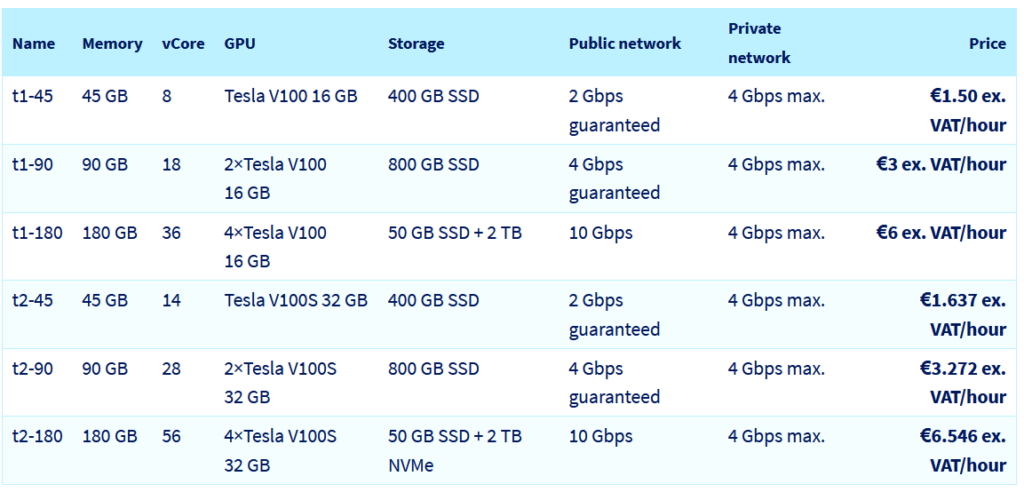
For running GPU instances, you can now provision our T2 instances (for Tesla 2nd generation) from your control panel or through APIs. In terms of specifications, those T2 instances are built with the Nvidia Tesla v100s GPU card, which provide 32GB for RAM per card (vs 16GB of RAM for T1) and have more CPUs core than T1, as shown in the table below.
And, of course T2 instances do follow our SMART approach:
- Simple pricing to understand
- Multi-local: available in Gravelines, Beauharnois and Limburg datacenters
- Accessible: well… check the price of p3.2xlarge to make your own idea
- Reversible: just take your data back and delete your instance
- Transparent: no ingress, no egress so it’s highly predictable
A few tips
- You can easily deploy GPU-accelerated containers on top of our T2 instances, with the Nvidia GPU Cloud (NGC) catalog.
- Make the most of the pay-as-you-go. Just delete your T2 instance when don’t need it anymore, as you’re charged per hour of usage.
- A way to look at our T2 instances is to consider them as an alternative and complementary to your GPU server without the upfront cost.
But wait, how about using GPU power with ease, with no drivers to install, no linux to update, with automation and AI framework and notebooks ?
Glad you asked !
AI Training: Train your models with GPU(s)
While you get the freedom, to install whichever distribution, AI framework and tools on top of our GPU instances, doing so requires system administration and ops skills that data scientists may not have, but most of all this is not where they do provide the greatest value.
With our objective to provide ready to use solutions for building AI-applications, we are proposing AI Training which enables you to train your models in just a few clicks, or in the command line interface. AI Training is a managed service that orchestrates the GPU resources (our T2) for training your model, hence freeing your data scientists from infrastructure and maintenance operations.
The beauty of this service is that you pay only for the execution of the training job you have specified. Check the video demo to see how AI Training fit into setting up an AI pipeline.
Steps to launch a job with AI training:
- Select your datacenter region, as of today Gravelines and Beauharnois
- Enter your Docker image, basically the model you want to train. The image can come from public or private registry
- Add data set against which your job will be trained. You need to create a Object Storage container to add a data set for your job.
- Enter the Docker command
- Configure your job (you can add up to 4 GPU for your job, but you can as well use CPU). The price per hour is displayed, but billing granularity is per minute
- Launch the job through the control panel or through command
Once the job is finished, save your trained model and delete the job. You are charged for the number of minutes you have used AI Training to perform your job.
AI Notebooks: Code live on top of GPU(s)
AI Notebooks is the latest of our AI services in our Public Cloud. It enables data scientists and developers to deploy, within 15 minutes, a ready to use notebook providing the required GPU resources (it supports CPU as well) for live coding and for creating their own models. AI Notebooks proposes Jupyter or VS Code notebook, the two most popular open-source live code editors, and supports natively the widely-used frameworks such as TensorFlow, PyTorch, Scikit-learn, MXNet and Hugging Face.
In short, AI Notebooks simplifies the life of your data scientists and improves their productivity, as they can focus on developing models with the tools they are already familiar with. Similarly to the Public Cloud services we reviewed in this post, AI Notebooks is a pay as you go solution. Based on how many GPU resources your AI Notebooks is running on, you will be charged for the number of minutes you have used your notebook.
Wrapping up
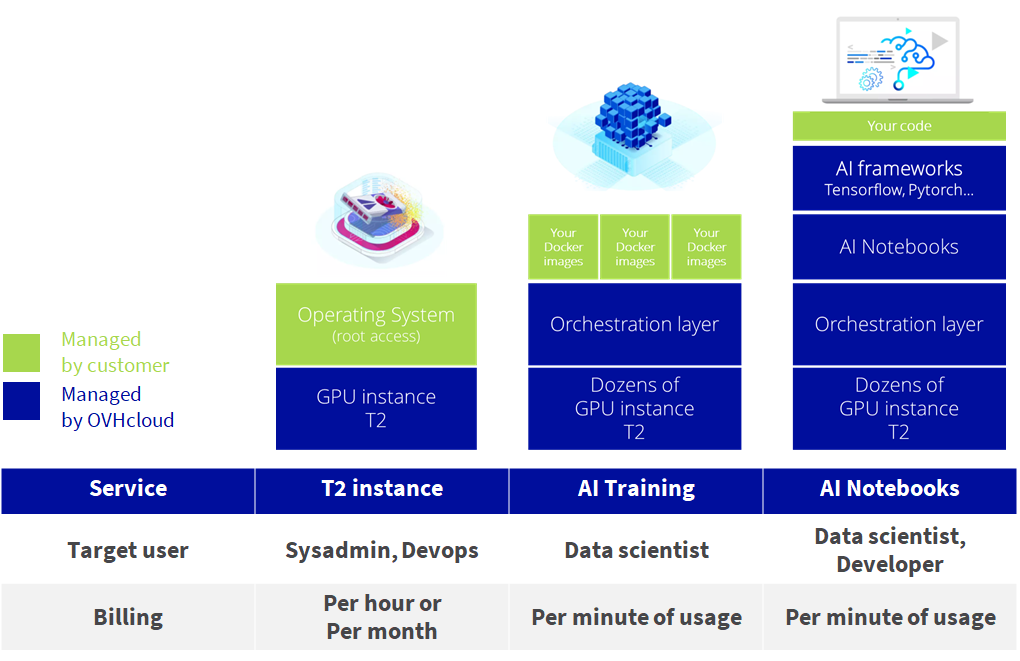
This review was written with the goal of providing a high-level understanding of the GPU-based services we do offer on our Public Cloud. While GPU instances, AI Training and AI Notebooks do have in common the fact that they are built upon our T2 instances, leveraging Nvidia Tesla v100s, the way we have designed and packaged those services makes them very different in terms of use case, target users and way of consuming the GPU resources. You can as a takeaway from this post check the summary table below:

Product Marketing Leader Public Cloud. Helping organizations adopt cloud native technologies