
Extend the impact of any video by embarking on the development of a transcription and translation solution for your multimedia content.

Today, media and social networks are omnipresent in our professional and personal lives: videos, tweets, posts, forums and Twitch lives… These different types of media enable companies and content creators to promote their activities and build community loyalty.
But have you ever wondered about the role of language when creating your content? Using just one language can be a hindrance to your business!
Transcribing and translating your videos could be the solution! Adapt your videos into different languages and make the content accessible to a wider audience, increasing its reach and impact.
💡 How can we achieve this?
By automatically subtitling and dubbing voices using AI APIs! With AI Endpoints, you will benefit from APIs based on several Speech AI models: ASR (Automatic Speech Recognition), NMT (Neural Machine Translation) and TTS (Text To Speech).
Objective
Whatever your level in AI, whether you’re a beginner or an expert, this tutorial will enable you to create your own powerful Video Translator in just a few lines of code.
The aim of this article is to show you how to make the most of Speech AI’s APIs, with no prior knowledge required!
⚡️ How to?
By connecting the Speech AI API endpoints using easy-to-implement features, and developing a web-app using the Gradio framework.
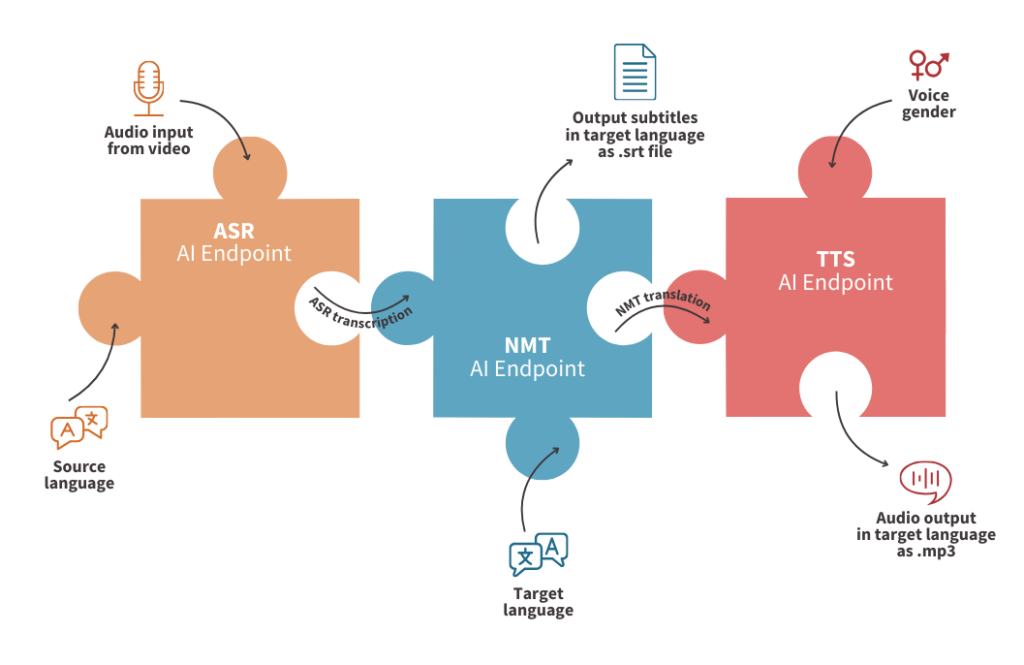
🚀 At the end?
We will have a web app that lets you upload a video in French, transcribe it and then subtitle it in English.
But that’s not all… They will also be able to dub the voice of a video into another language!
👀 Before we start coding, let’s take a look at the different concepts…
Concept
To better understand the technologies that revolve around the Video Translator, let’s start by examining the models and notions of ASR, NMT, TTS…
AI Endpoints in a few words
AI Endpoints is a new serverless platform powered by OVHcloud and designed for developers.
The aim of AI Endpoints is to enable developers to enhance their applications with AI APIs, whatever their level and without the need for AI expertise.
It offers a curated catalog of world-renowned AI models and Nvidia’s optimized models, with a commitment to privacy as data is not stored or shared during or after model use.
AI Endpoints provides access to advanced AI models, including Large Language Models (LLMs), natural language processing, translation, speech recognition, image recognition, and more.

To know more about AI Endpoints, refer to this website.
AI Endpoints proposes several ASR APIs in different languages… But what means ASR?
Transcribe video using ASR
Automatic Speech Recognition (ASR) technology, also known as Speech-To-Text, is the process of converting spoken language into written text.
This process consists of several stages, including preparing the speech signal, extracting features, creating acoustic models, developing language models, and utilizing speech recognition engines.
With AI Endpoints, we simplify the use of ASR technology through our ready-to-use inference APIs. Learn how to use our APIs by following this link.
These APIs can be used to transcribe audio from video into text, which can then be sent to NMT model in order to translate it into an other language.
Translate thanks to NMT
NMT, for Neural Machine Translation, is a subfield of Machine Translation (MT) that uses Artificial Neural Networks (ANNs) to predict or generate translations from one language to another.
If you want to learn more, the best way is to try it out for yourself! You can do so by following this link.
In this particular application, the NMT models will translate into an other language the results of the ASR (Automatic Speech Recognition) endpoint.
Then, there are two options:
- generate subtitles .srt file based on the NMT translation
- apply voice dubbing thanks to speech synthesis
🤯 Would you like to use speech synthesis ? Challenge accepted, that’s what TTS is for.
Allow voice dubbing with TTS
TTS stands for Text-To-Speech, which is a type of technology that converts written text into spoken words.
This technology uses Artificial Intelligence algorithms to interpret and generate human-like speech from text input.
It is commonly used in various applications such as voice assistants, audiobooks, language learning platforms, and accessibility tools for individuals with visual or reading impairments.
With AI Endpoints, TTS is easy to use thanks to the turnkey inference APIs. Test it for free here.
🤖 Are you ready to start coding the Video Translator? Let’s go!
Technical implementation of the Audio Virtual Assistant
This technical section covers the following points:
- send your video (.mp4) and extract audio as .wav file
- use ASR endpoint to transcribe audio into text
- translate ASR transcription into the target language using NMT endpoint
- create .srt file to add video subtitles
- use TTS endpoint to convert NMT translation into spoken words
- implement voice dubbing function to merge generated audio with input video
Finally, create a web app with Gradio to make it easy to use!
➡️ Access the full code here.
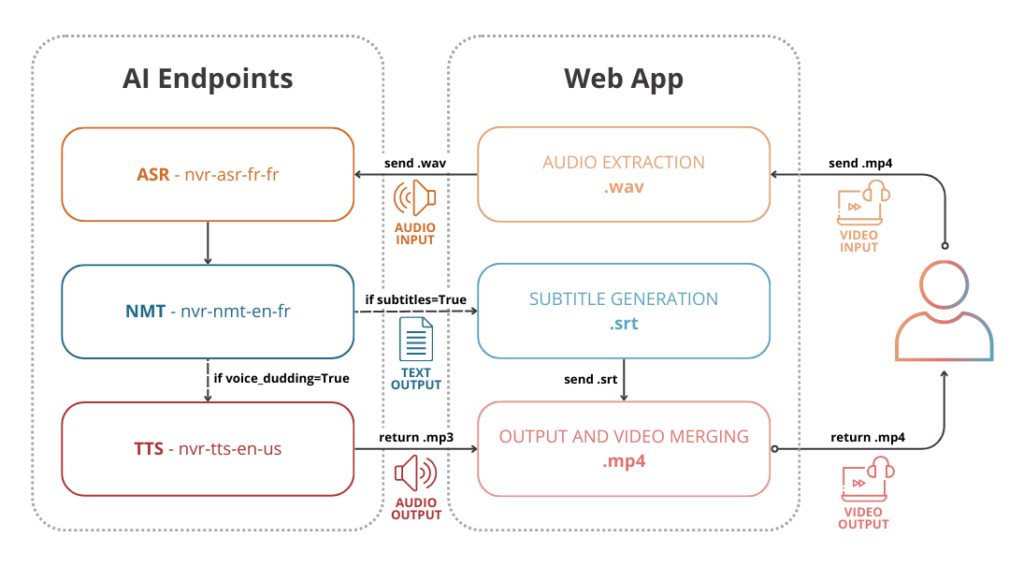
In order to build the Video Translator, start by setting up the environment.
Set up the environment
In order to use AI Endpoints APIs easily, create a .env file to store environment variables.
ASR_GRPC_ENDPOINT=nvr-asr-fr-fr.endpoints-grpc.kepler.ai.cloud.ovh.net:443
NMT_GRPC_ENDPOINT=nvr-nmt-en-fr.endpoints-grpc.kepler.ai.cloud.ovh.net:443
TTS_GRPC_ENDPOINT=nvr-tts-en-us.endpoints-grpc.kepler.ai.cloud.ovh.net:443
OVH_AI_ENDPOINTS_ACCESS_TOKEN=<ai-endpoints-api-token>⚠️ Test AI Endpoints and get your free token here
In the next step, install the needed Python dependencies.
If the library ffmpeg is not already installed, launch the following command:
sudo apt install ffmpegCreate the requirements.txt file with the following libraries and launch the installation.
⚠️The environnement workspace is based on Python 3.11
nvidia-riva-client==2.15.0
gradio==4.16.0
moviepy==1.0.3
librosa==0.10.1
pysrt==1.1.2
pip install -r requirements.txtOnce this is done, you have to create a five Python files:
asr.py– transcribe audio into textnmt.py– translate the transcription into an other languagetts.py– synthesize the text into speechutils.py– extract audio from video, connect ASR, NMT and TTS functions together and merge the result with the input videomain.py– create the Gradio app to make it easy to use
⚠️ Note that only a few functions will be covered in this article! To create the entire app, refer to the GitHub repo, which contains all the code ⚠️
Transcribe the audio part of the video in writing
First, create the Automatic Speech Recognition (ASR) function in order to obtain the video transcription into French.
💡 How it works?
The asr_transcription function allows you to transcribe the audio part of the video into text and to get the beginning and the end of each sentence thanks to the enable_word_time_offsets parameter.
def asr_transcription(audio_input):
# connect with asr server
asr_service = riva.client.ASRService(
riva.client.Auth(
uri=os.environ.get('ASR_GRPC_ENDPOINT'),
use_ssl=True,
metadata_args=[["authorization", f"bearer {ai_endpoint_token}"]]
)
)
# set up config
asr_config = riva.client.RecognitionConfig(
language_code="fr-FR",
max_alternatives=1,
enable_automatic_punctuation=True,
enable_word_time_offsets=True,
audio_channel_count = 1,
)
# open and read audio file
with open(audio_input, 'rb') as fh:
audio = fh.read()
riva.client.add_audio_file_specs_to_config(asr_config, audio)
# return response
resp = asr_service.offline_recognize(audio, asr_config)
output_asr = []
# extract sentence information
for s in range(len(resp.results)):
output_sentence = []
sentence = resp.results[s].alternatives[0].transcript
output_sentence.append(sentence)
for w in range(len(resp.results[s].alternatives[0].words)):
start_sentence = resp.results[s].alternatives[0].words[0].start_time
end_sentence = resp.results[s].alternatives[0].words[w].end_time
# add start time and stop time of the sentence
output_sentence.append(start_sentence)
output_sentence.append(end_sentence)
# final asr transcription and time sequences
output_asr.append(output_sentence)
# return response
return output_asr🎉 Congratulations! Your ASR function is ready to use.
⏳ But that’s just the beginning! Now you have to build the translation part….
Translate French text into English
Then, build the Neural Machine Translation (NMT) function to transform theFrench transcription into English.
➡️ In practice?
The nmt_translation function allows you to translate the different sentences in English. Don’t forget to keep the start and end times for each sentence!
def nmt_translation(output_asr):
# connect with nmt server
nmt_service = riva.client.NeuralMachineTranslationClient(
riva.client.Auth(
uri=os.environ.get('NMT_GRPC_ENDPOINT'),
use_ssl=True,
metadata_args=[["authorization", f"bearer {ai_endpoint_token}"]]
)
)
# set up config
model_name = 'fr_en_24x6'
output_nmt = []
for s in range(len(output_asr)):
output_nmt.append(output_asr[s])
text_translation = nmt_service.translate([output_asr[s][0]], model_name, "fr", "en")
output_nmt[s][0]=text_translation.translations[0].text
# return response
return output_nmt⚡️ You’re almost there! Now all you have to do is build the TTS function.
Synthesize the translated text into spoken words
Finally, create the Text To Speech (TTS) function to synthesize the French text into audio.
👀 How to?
Firstly, create the tts_transcription function, dedicated to audio generation and silences management based on ASR and NMT results.
def tts_transcription(output_nmt, video_input, video_title, voice_type):
# connect with tts server
tts_service = riva.client.SpeechSynthesisService(
riva.client.Auth(
uri=os.environ.get('TTS_GRPC_ENDPOINT'),
use_ssl=True,
metadata_args=[["authorization", f"bearer {ai_endpoint_token}"]]
)
)
# set up tts config
sample_rate_hz = 16000
req = {
"language_code" : "en-US",
"encoding" : riva.client.AudioEncoding.LINEAR_PCM ,
"sample_rate_hz" : sample_rate_hz,
"voice_name" : f"English-US.{voice_type}"
}
output_audio = 0
output_audio_file = f"{outputs_path}/audios/{video_title}.wav"
for i in range(len(output_nmt)):
# add silence between audio sample
if i==0:
duration_silence = output_nmt[i][1]
else:
duration_silence = output_nmt[i][1] - output_nmt[i-1][2]
silent_segment = AudioSegment.silent(duration = duration_silence)
output_audio += silent_segment
# create tts transcription
req["text"] = output_nmt[i][0]
resp = tts_service.synthesize(**req)
sound_segment = AudioSegment(
resp.audio,
sample_width=2,
frame_rate=16000,
channels=1,
)
output_audio += sound_segment
# export new audio as wav file
output_audio.export(output_audio_file, format="wav")
# add new voice on video
voice_dubbing = add_audio_on_video(output_audio_file, video_input, video_title)
return voice_dubbingSecondly, build the add_audio_on_video function in order to merge the new audio on the video.
def add_audio_on_video(translated_audio, video_input, video_title):
videoclip = VideoFileClip(video_input)
audioclip = AudioFileClip(translated_audio)
new_audioclip = CompositeAudioClip([audioclip])
new_videoclip = f"{outputs_path}/videos/{video_title}.mp4"
videoclip.audio = new_audioclip
videoclip.write_videofile(new_videoclip)
return new_videoclip🤖 Congratulations! Now you’re ready to put the puzzle pieces together with the utils.py file.
Combine the results of the various functions
This is the most important step! Connect the functions output to return the final video…
🚀 What to do?
1. Create the main.py to implement the Gradio app
➡️ Access to the code here.
2. Build utils.py file to connect the results to each other
➡️ Refer to this Python file.
😎 Well done! You can now use your web app to translate any video from French to English.
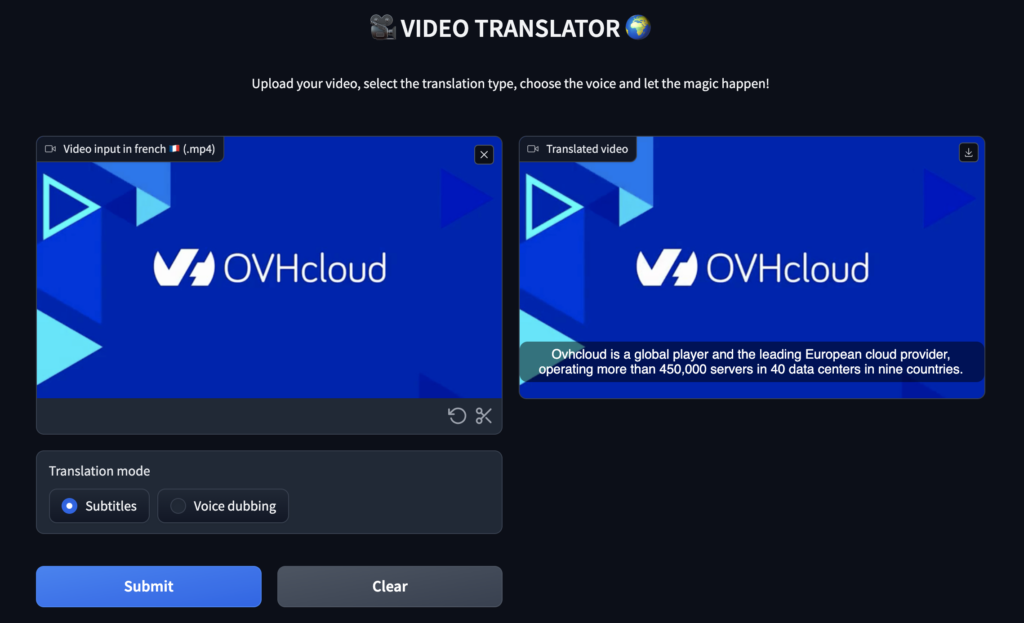
🚀 That’s it! Now get the most out of your tool by launching it locally.
Launch Video Translator web app locally
In this last step , you can start this Gradio app locally by launching the following command:
python3 main.pyBenefit from the full power of your tool as follow!
☁️ It’s also possible to make your interface accessible to everyone…
Go further
If you want to go further and deploy your web app in the cloud, refer to the following articles and tutorials.
- Deploy a custom Docker image for Data Science project
- AI Deploy – Tutorial – Build & use a custom Docker image
- AI Deploy – Tutorial – Deploy a Gradio app for sketch recognition
Conclusion of the Audio Virtual Assistant
Congratulations 🎉! You have learned how to build your own Video Translator in thanks to AI Endpoints.
You’ve also seen how easy it is to use AI Endpoints to create innovative turnkey solutions.
➡️ Access the full code here.
🚀 What’s next? Implement an Audio Virtual Assistant in less than 100 lines of code!
References
- Enhance your applications with AI Endpoints
- Create your own Audio Summarizer assistant with AI Endpoints!
- Build a powerful Audio Virtual Assistant in less than 100 lines of code with AI Endpoints!

Solution Architect @OVHcloud