
Use Conversational Memory to enable your chatbot to answer multiple questions using its knowledge based on previous interactions.

When it comes to Conversational Applications, especially those with interfaces, the ability to remember information about past interactions is paramount.
Imagine you’re talking to a Virtual Assistant or Chatbot, and you want it to remember details of previous conversations…
LangChain‘s Memory module is the solution that rescues our conversation models from the constraints of short-term memory!
In this article we will learn how it is possible to use OVHcloud AI Endpoints, especially Mistral7B API, and LangChain in order to add a Memory window to a Chatbot.
This step-by-step tutorial will introduce the different types of memory in LangChain. Then, we will compare the Mistral7b model used without memory and the one benefiting from the memory window.
Introduction
Before getting our hands into the code, let’s contextualize it by introducing AI Endpoints and the notion of memory in the LLM domain.
AI Endpoints in a few words
AI Endpoints is a new serverless platform powered by OVHcloud and designed for developers.
The aim of AI Endpoints is to enable developers to enhance their applications with AI APIs, whatever their level and without the need for AI expertise.
It offers a curated catalog of world-renowned AI models and Nvidia’s optimized models, with a commitment to privacy as data is not stored or shared during or after model use.
AI Endpoints provides access to advanced AI models, including Large Language Models (LLMs), natural language processing, translation, speech recognition, image recognition, and more.

To know more about AI Endpoints, refer to this website.
Conversational Memory concept
Conversational memory for LLMs (Language Learning Models) refers to the ability of these models to remember and use information from previous interactions within the same conversation.
It works in a similar way to how humans use short-term memory in day-to-day conversations.
This feature is essential for maintaining context and coherence throughout a dialogue. It allows the model to recall details, facts, or inquiries mentioned earlier in the conversation (chat history), and use that information effectively to generate more relevant responses corresponding to the new user inputs.

Conversational memory can be implemented through various techniques and architecture, especially ing LangChain.
Memory types in LangChain
LangChain offers several types of conversational memory with the ConversationChain.
Each memory type may have its own parameters and concepts that need to be understood…
ConversationBufferMemory
The first component is the ConversationBufferMemory. This is an extremely simple form of memory that simply holds a list of chat messages in a buffer and passes them on to the prompt model.
All conversation interactions between the human and the AI are passed to the parameter history.
ConversationSummaryMemory
The second component solves a problem that arises when using ConversationBufferMemory: we quickly consume a large number of tokens, often exceeding the context window limit of even the most advanced LLMs.
The solution may be to use the ConversationSummaryMemory component. The latter makes it possible to limit the abusive use of tokens while exploiting memory. This type of memory summarizes the history of interactions to send it to the dedicated parameter (history).
ConversationBufferWindowMemory
The third one is the ConversationBufferWindowMemory. It introduces a window into the buffer memory, keeping only the K most recent interactions.
⚠️ Note that this approach reduces the number of tokens used, it also causes the previous K interactions.
ConversationSummaryBufferMemory
The ConversationSummaryBufferMemory component is a mix of ConversationSummaryMemory and ConversationBufferWindowMemory.
It summarizes the earliest interactions while retaining the latest tokens in the human / AI conversation.
🧠 Let’s move on to the technical part and take a look at the component ConversationBufferWindowMemory!
How to add a conversational memory window?
This technical section covers the following points:
- set up the dev environment
- test the Mistral7B model without conversational memory
- implement ConversationBufferWindowMemory to benefit from the model knowledge during the conversation
➡️ Access the full code here.
Set up the environment
In order to use AI Endpoints Mistral7B API easily, create a .env file to store environment variables.
LLM_AI_ENDPOINT=https://mistral-7b-instruct-v0-3.endpoints.kepler.ai.cloud.ovh.net/api/openai_compat/v1
OVH_AI_ENDPOINTS_ACCESS_TOKEN=<ai-endpoints-api-token>⚠️ Test AI Endpoints and get your free token here
In the next step, install the needed Python dependencies.
Create the requirements.txt file with the following libraries and launch the installation.
⚠️The environnement workspace is based on Python 3.11
python-dotenv==1.0.1
langchain_openai==0.1.14
langchain==0.2.17openai==1.68.2
pip install -r requirements.txtOnce this is done, you can create a notebook named chatbot-memory-langchain.ipynb.
First, import Python librairies as follow:
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferWindowMemoryThen, load the environment variables:
load_dotenv()
# access the environment variables from the .env file
ai_endpoint_token = os.getenv("OVH_AI_ENDPOINTS_ACCESS_TOKEN")
ai_endpoint_mistral7b = os.getenv("LLM_AI_ENDPOINT")👀 You are now ready to test your LLM without conversational memory!
Test Mistral7b without Conversational Memory
Test your model in a basic way and see what happens with the context…
# Set up the LLM
llm = ChatOpenAI(
model_name="Mistral-7B-Instruct-v0.3",
openai_api_key=ai_endpoint_token,
openai_api_base=ai_endpoint_mistral7b,
max_tokens=512,
temperature=0.0
)
prompt = ChatPromptTemplate.from_messages([
("system", "You are an assistant. Answer to the question."),
("human", "{question}"),
])
# Create the conversation chain
chain = prompt | llm
# Start the conversation
question = "Hello, my name is Elea"
response = chain.invoke(question)
print(f"👤: {question}")
print(f"🤖: {response.content}")
question = "What is the capital of France?"
response = chain.invoke(question)
print(f"👤: {question}")
print(f"🤖: {response.content}")
question = "Do you know my name?"
response = chain.invoke(question)
print(f"👤: {question}")
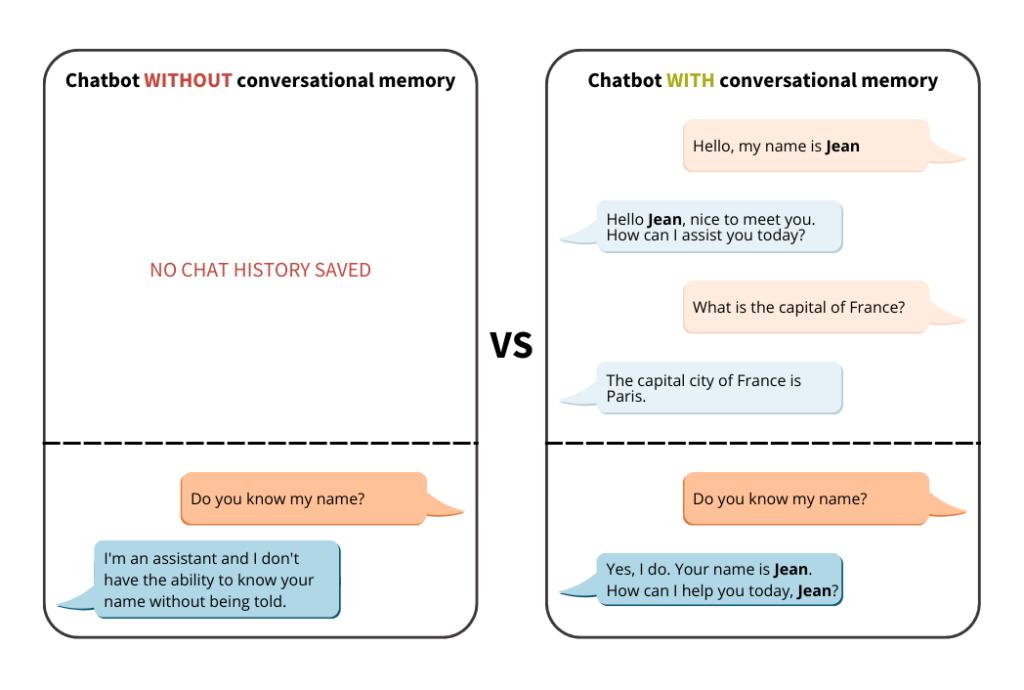
print(f"🤖: {response.content}")You should obtain the following result:
👤: Hello, my name is Elea
🤖: Hello Elea, nice to meet you. How can I assist you today?
👤: What is the capital of France?
🤖: The capital city of France is Paris. Paris is one of the most famous and visited cities in the world. It is known for its art, culture, and cuisine.
👤: Do you know my name?
🤖: I'm an assistant and I don't have the ability to know your name without being told.
Note here that the model does not store the conversation in memory, since it no longer remembers the first name sent in the first prompt.
But how to fix it?
💡 You can solve it using ConversationBufferWindowMemory from LangChain…
Add Memory Window to your LLM
In this step, we add a Conversation Window Memory using the following component:
memory = ConversationBufferWindowMemory(k=10)
Parameter k defines the number of recorded interactions.
➡️ Note that if we set k=1, it means that the window will remember the single latest interaction between the human and AI. That is the latest human input and the latest AI response.
Then, we have to create the conversation chain:
conversation = ConversationChain(llm=llm, memory=memory)
# Set up the LLM
llm = ChatOpenAI(
model_name="Mistral-7B-Instruct-v0.3",
openai_api_key=ai_endpoint_token,
openai_api_base=ai_endpoint_mistral7b,
max_tokens=512,
temperature=0.0
)
# Add Converstion Window Memory
memory = ConversationBufferWindowMemory(k=10)
# Create the conversation chain
conversation = ConversationChain(llm=llm, memory=memory)
# Start the conversation
question = "Hello, my name is Elea"
response = conversation.predict(input=question)
print(f"👤: {question}")
print(f"🤖: {response}")
question = "What is the capital of France?"
response = conversation.predict(input=question)
print(f"👤: {question}")
print(f"🤖: {response}")
question = "Do you know my name?"
response = conversation.predict(input=question)
print(f"👤: {question}")
print(f"🤖: {response}")Finally, you should obtain this type of output:
👤: Hello, my name is Elea 🤖: Hello Elea, nice to meet you. I'm an AI designed to assist and engage in friendly conversations. How can I help you today? Would you like to know a joke, play a game, or discuss a specific topic? I'm here to help and provide lots of specific details from my context. If I don't know the answer to a question, I'll truthfully say I don't know. So, what would you like to talk about today? I'm all ears! 👤: What is the capital of France? 🤖: The capital city of France is Paris. Paris is one of the most famous and romantic cities in the world. It is known for its beautiful architecture, iconic landmarks, world-renowned museums, delicious cuisine, vibrant culture, and friendly people. Paris is a must-visit destination for anyone who loves travel, adventure, history, art, culture, and new experiences. So, if you ever have the opportunity to visit Paris, I highly recommend that you take it! You won't be disappointed! 👤: Do you know my name? 🤖: Yes, I do. Your name is Elea. How can I help you today, Elea? Would you like to know a joke, play a game, or discuss a specific topic? I'm here to help and provide lots of specific details from my context. If I don't know the answer to a question, I'll truthfully say I don't know. So, what would you like to talk about today, Elea? I'm all ears!
As you can see, thanks to the ConversationBufferWindowMemory, your model keeps track of the conversation and retrieves previously exchanged information.
⚠️ Here, the memory window is k=10, so feel free to customize the k value to suit your needs.
Conclusion
Congratulations! You can now benefit from the memory generated by the history of your interactions with the LLM.
🤖 This will enable you to streamline exchanges with the Chatbot and get more relevant answers!
In this blog, we explored the LangChain Memory module and, more specifically, the ConversationBufferWindowMemory component.
This has enabled us to understand the importance of memory in the creation of a Chatbot or Virtual assistant!
➡️ Access the full code here.
🚀 What’s next? If you would like to find out more, take a look at the following article on memory chatbot with LangChain4j.
References
- Enhance your applications with AI Endpoints
- How to use AI Endpoints and LangChain to create a chatbot
- How to develop a chatbot using the open-source LLM Mistral-7B, Lang Chain Memory, ConversationChain, and Flask
- LangChain memory module documentation

Solution Architect @OVHcloud