
Featured articles
Articles handpicked by our editorial team.
Latest articles

What’s new with the OVHcloud Developer Advocate team - July 2026
Tech bitesStéphane Philippart
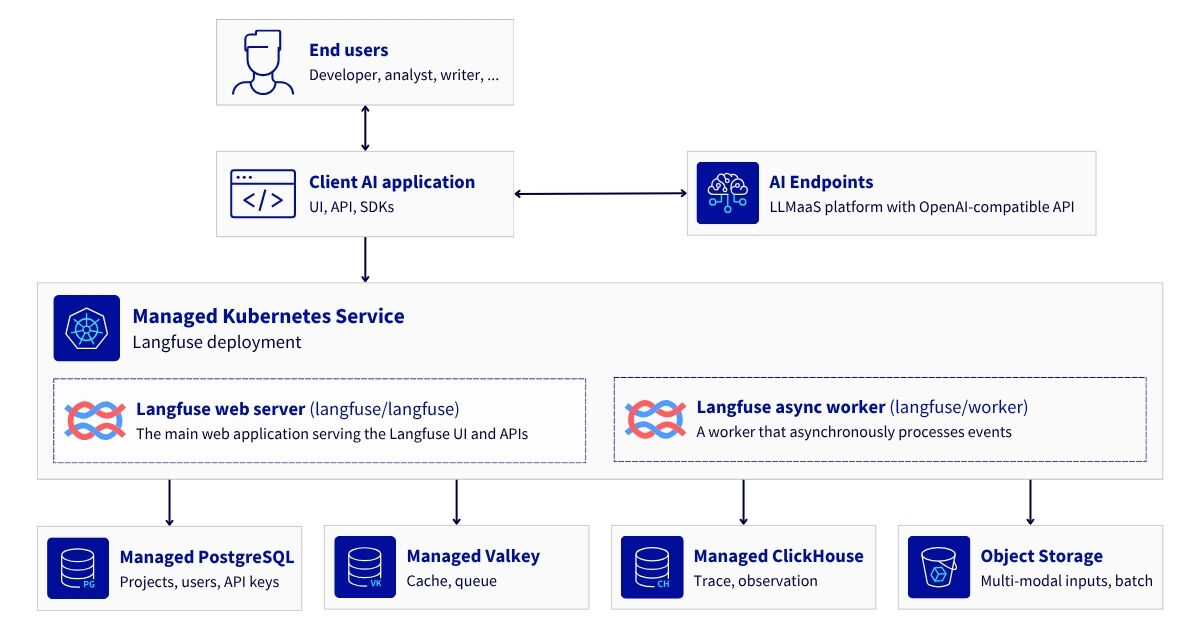
Reference Architecture: Deploy Langfuse on OVHcloud MKS for LLM observability and AI cost tracking
EngineeringEléa Petton23/07/2026

Platform Engineering for AI: Does Your Kubernetes Platform Scale?
Accelerating with OVHcloudMaxime Lehmann 20/07/2026
CVE-2026-53359 (Januscape) patch campaign: Lessons learned from handling a KVM flaw on tens of thousands of machines
Product NewsJulien Levrard20/07/2026

What’s new in VMware Cloud Foundation (VCF 9.x)
EngineeringRémy Vandepoel, Hugo Allabert19/07/2026

Navigating OVHcloud File Storage with Manila CSI (RWX) on Kubernetes clusters (MKS)
EngineeringAurélie Vache16/07/2026

The architecture of blockchain explained: how proof of stake works
EngineeringElena Luoto, Omar Abi issa, Adnan Patka12/07/2026

OVHcloud announces 2025 Startup Program award winners at London Summit
Startup ProgramCezary Skarzynski07/07/2026

Object Storage: 10 years on, from scalability to resilience
EngineeringRémy Vandepoel07/07/2026