
Do you dream of being able to summarize hours of meetings in a matter of seconds? Don’t go away, we’ll explain it all here!
Introduction
Are you looking for a way to efficiently summarize your meetings, broadcasts, and podcasts for quick reference or to provide to others? Look no further!
In this blog post, you will be able to create an Audio Summarizer assistant that can not only transcribe but also summarize all your audios.
Thanks to AI Endpoints, it’s never been easier to create a virtual assistant that can help you stay on top of your meetings and keep track of important information.
This article will explore how AI APIs can be useful to create an advanced virtual assistant to transcribe and summarize any audio file thanks to ASR (Automatic Speech Recognition) technologies and famous LLMs (Large Language Models).
Objectives
Whether you’re a professional, a student or just want to make the most of your time, this step-by-step guide will show you how to create an Audio Summarizer assistant that will help you summarize your meetings, shows and podcasts, allowing you to concentrate on what really matters!
How to?
By connecting your AI Endpoints like puzzles!
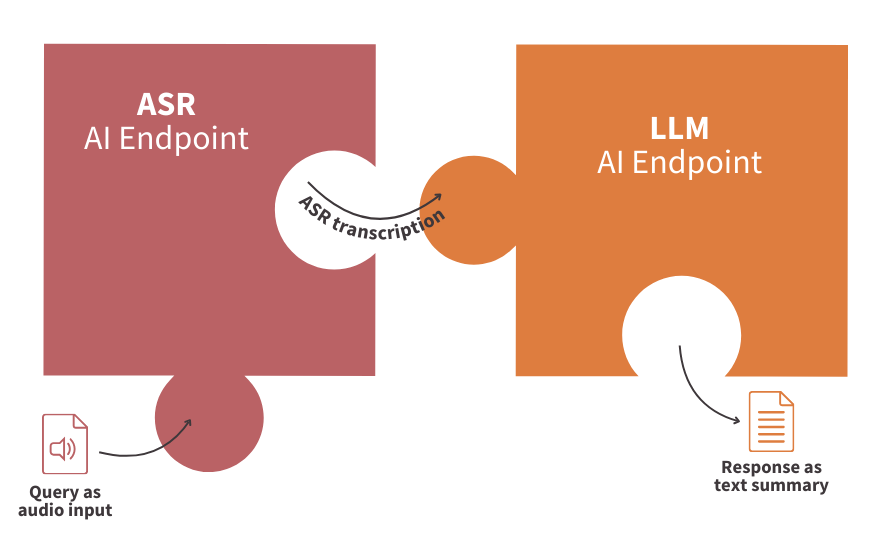
👀 But first of all, a few definitions are needed to fully understand the technical implementation that follows.
Concept
In order to better understand the technologies that revolve around the Audio Summarizer, let’s start by looking at the tools and notions of ASR, LLM, …
AI Endpoints in a few words
AI Endpoints is a new serverless platform powered by OVHcloud and designed for developers.
The aim of AI Endpoints is to enable developers to enhance their applications with AI APIs, whatever their level and without the need for AI expertise.
It offers a curated catalog of world-renowned AI models and Nvidia’s optimized models, with a commitment to privacy as data is not stored or shared during or after model use.
AI Endpoints provides access to advanced AI models, including Large Language Models (LLMs), natural language processing, translation, speech recognition, image recognition, and more.

To know more about AI Endpoints, refer to this website.
AI Endpoints proposes several ASR APIs in different languages… But what means ASR?
It all starts with ASR
Automatic Speech Recognition (ASR) is a technology that converts spoken language into written text.
It is a complex process that involves several stages, including speech signal preprocessing, feature extraction, acoustic modeling, language modeling, and speech recognition engine.
AI Endpoints makes it easy, with ready-to-use inference APIs. Discover how to use them here.
In this context, ASR will be used to transcribe long audios into text in order to summarize it with LLMs.
Making summary with LLM
The famous LLMs, for Large Language Models are responsible for generating human-like text.
They use complex algorithms to predict patterns in human language, understand context, and provide relevant responses. With LLM, virtual assistants can engage in meaningful and dynamic conversations with users.
To find out more, what better way than to test it yourself? Follow this link.
For the current use case, the LLM prompt will precise to generate a summary of the input text based on the result of the ASR endpoint.
🤖 Do you want to start coding the Audio Summarizer? 3, 2, 1, get ready, go!
Technical implementation of the Audio Summarizer
In this technical part, the following points will be discussed:
- the use of the ASR API inside Python code
- the integration of the Mixtral8x22B LLM
- the creation of a web app with Gradio
➡️ Access the full code here.
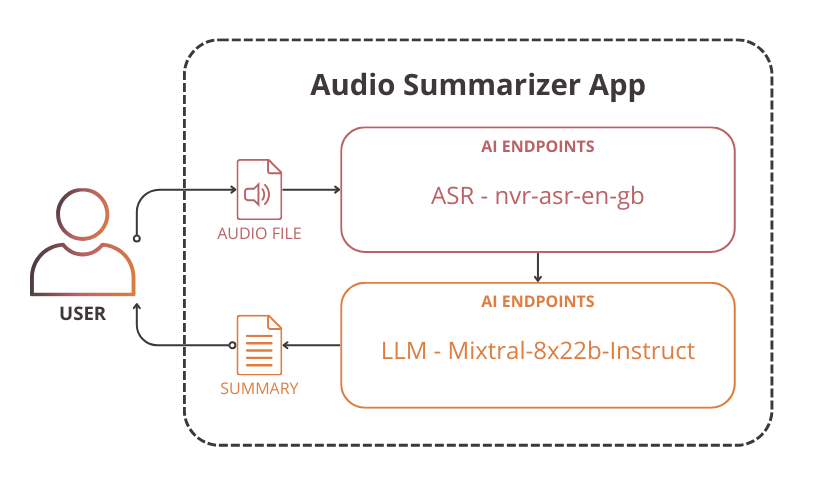
To build the Audio Summarizer, start by setting up the environment.
Set up the environment
In order to use AI Endpoints APIs easily, create a .env file to store environment variables.
ASR_AI_ENDPOINT=https://nvr-asr-en-gb.endpoints.kepler.ai.cloud.ovh.net/api/v1/asr/recognize
LLM_AI_ENDPOINT=https://mixtral-8x22b-instruct-v01.endpoints.kepler.ai.cloud.ovh.net/api/openai_compat/v1
OVH_AI_ENDPOINTS_ACCESS_TOKEN=<ai-endpoints-api-token>⚠️ Test AI Endpoints and get your free token here
In the next step, install the needed Python dependencies.
Create the requirements.txt file with the following libraries and launch the installation.
⚠️The environnement workspace is based on Python 3.11
openai==1.13.3
gradio==4.36.1
pydub==0.25.1
python-dotenv==1.0.1
pip install -r requirements.txtOnce this is done, you can create a Python file named audio-summarizer-app.py.
Then, import Python librairies as follow:
import gradio as gr
import io
import os
import requests
from pydub import AudioSegment
from dotenv import load_dotenv
from openai import OpenAINow, load and access the environnement variables.
# access the environment variables from the .env file
load_dotenv()
asr_ai_endpoint_url = os.environ.get("ASR_AI_ENDPOINT")
llm_ai_endpoint_url = os.getenv("LLM_AI_ENDPOINT")
ai_endpoint_token = os.getenv("OVH_AI_ENDPOINTS_ACCESS_TOKEN")💡 You are now ready to start coding your web app!
Transcribe audio file with ASR
First, create the Automatic Speech Recognition (ASR) function in order to transcribe audio files into text.
How it works?
- The audio file is preprocessed as follow:
.wavformat,1channel,16000frame rate - The transformed audio
processed_audiois read - An API call is made to the ASR AI Endpoint named
nvr-asr-en-gb - The full response is stored in
respvariable and returned by the function
def asr_transcription(audio):
if audio is None:
return " "
else:
# preprocess audio
processed_audio = "/tmp/my_audio.wav"
audio_input = AudioSegment.from_file(audio, "mp3")
process_audio_to_wav = audio_input.set_channels(1)
process_audio_to_wav = process_audio_to_wav.set_frame_rate(16000)
process_audio_to_wav.export(processed_audio, format="wav")
# headers
headers = headers = {
'accept': 'application/json',
"Authorization": f"Bearer {ai_endpoint_token}",
}
# put processed audio file as endpoint input
files = [
('audio', open(processed_audio, 'rb')),
]
# get response from endpoint
response = requests.post(
asr_ai_endpoint_url,
files=files,
headers=headers
)
# return complete transcription
if response.status_code == 200:
# Handle response
response_data = response.json()
resp=''
for alternative in response_data:
resp+=alternative['alternatives'][0]['transcript']
else:
print("Error:", response.status_code)
return resp🎉 Congratulations! Your ASR function is ready to use.
Now it’s time to call an LLM to summarize the transcribed text.
Summarize audio with LLM
In this second step, create the Chat Completion function to use Mixtral8x22B effectively.
What to do?
- Check that the transcription exists
- Use the OpenAI API compatibility to call the LLM
- Customize your prompt in order to specify LLM task
- Return the audio summary
def chat_completion(new_message):
if new_message==" ":
return "Please, send an input audio to get its summary!"
else:
# auth
client = OpenAI(
base_url=llm_ai_endpoint_url,
api_key=ai_endpoint_token
)
# prompt
history_openai_format = [{"role": "user", "content": f"Summarize the following text in a few words: {new_message}"}]
# return summary
return client.chat.completions.create(
model="Mixtral-8x22B-Instruct-v0.1",
messages=history_openai_format,
temperature=0,
max_tokens=1024
).choices.pop().message.content⚡️ You’re almost there! Now all you have to do is build your web app.
To make your solution easy to use, what better way than to quickly create an interface with just a few lines of code?
Build Gradio app
Gradio is an open-source Python library that allows to quickly create user interfaces for Machine Learning models and demos.
What does it mean in practice?
Inside a Gradio Block, you can:
- Define a theme for your UI
- Add a title to your web app with
gr.HTML() - Upload audio thanks to the dedicated component,
gr.Audio() - Obtain the result of the written transcription with the
gr.Textbox() - Get a summary of the audio with the powerful LLM and a second
gr.Textbox()component - Add a clear button with
gr.ClearButton()to reset the page of the web app
with gr.Blocks(theme=gr.themes.Default(primary_hue="blue"), fill_height=True) as demo:
# add title and description
with gr.Row():
gr.HTML(
"""
<div align="center">
<h1>Welcome on Audio Summarizer web app 💬!</h1>
<i>Transcribe and summarize your broadcast, meetings, conversations, potcasts and much more...</i>
</div>
<br>
"""
)
# audio zone for user question
gr.Markdown("## Upload your audio file 📢")
with gr.Row():
inp_audio = gr.Audio(
label = "Audio file in .wav or .mp3 format:",
sources = ['upload'],
type = "filepath",
)
# written transcription of user question
with gr.Row():
inp_text = gr.Textbox(
label = "Audio transcription into text:",
)
# chabot answer
gr.Markdown("## Chatbot summarization 🤖")
with gr.Row():
out_resp = gr.Textbox(
label = "Get a summary of your audio:",
)
with gr.Row():
# clear inputs
clear = gr.ClearButton([inp_audio, inp_text, out_resp])
# update functions
inp_audio.change(
fn = asr_transcription,
inputs = inp_audio,
outputs = inp_text
)
inp_text.change(
fn = chat_completion,
inputs = inp_text,
outputs = out_resp
)Then, you can launch it in the main.
if __name__ == '__main__':
demo.launch(server_name="0.0.0.0", server_port=8000)Now, the web app is ready to be used!
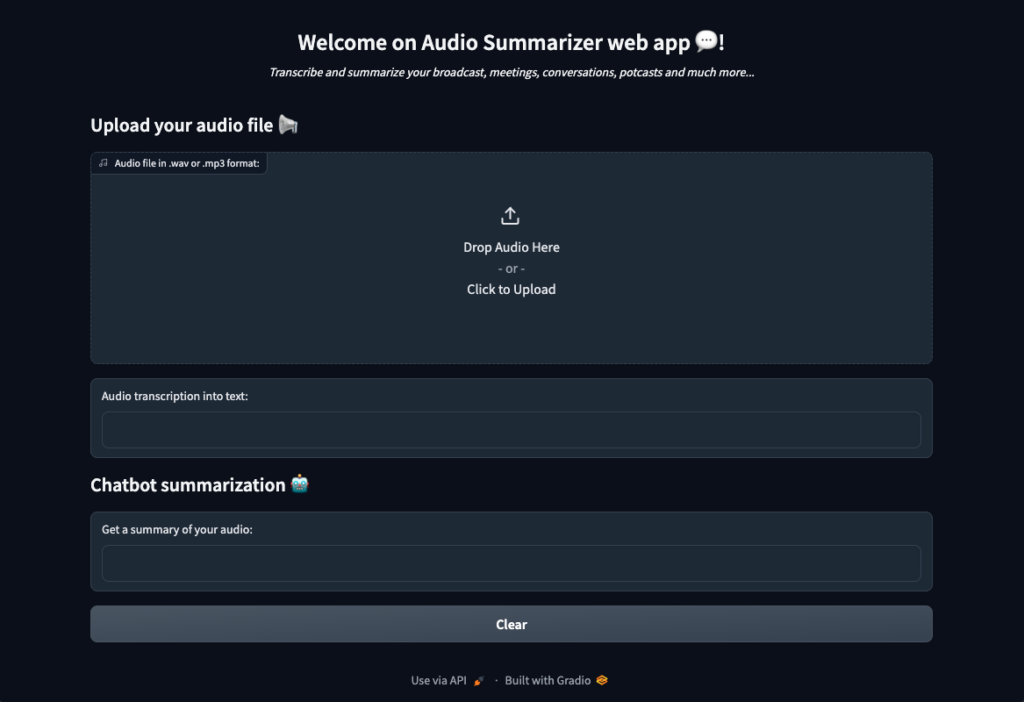
🚀 That’s it! Now get the most out of your tool by launching it locally.
Launch Gradio web app locally
Finally, you can start this Gradio app locally by launching the following command:
python audio-summarizer-app.pyBenefit from the full power of your tool and save time!
☁️ It’s also possible to make your interface accessible to everyone…
Go Further
If you want to go further and deploy your web app in the cloud, refer to the following articles and tutorials.
- Deploy a custom Docker image for Data Science project
- AI Deploy – Tutorial – Build & use a custom Docker image
- AI Deploy – Tutorial – Deploy a Gradio app for sketch recognition
Conclusion of the Audio Summarizer
Well done 🎉! You have learned how to build your own Audio Summarizer app in a few lines of code.
You’ve also seen how easy it is to use AI Endpoints to create innovative turnkey solutions.
➡️ Access the full code here.
What’s next? Modify your prompt and add translation to get the summary in an other language 💡
References
- Enhance your applications with AI Endpoints
- RAG chatbot using AI Endpoints and LangChain
- How to use AI Endpoints, LangChain and Javascript to create a chatbot
- How to use AI Endpoints and LangChain to create a chatbot

Machine Learning Engineer