

The good old time
Many years ago I was a SysAdmin. Do you remember this old job? Let me remind you of a few recurring scenarios:
ssh someone@somewhere
apt-get install something
vi /etc/something
/etc/init.d/something restartssh someone@somewhere
fdisk /dev/sdb
mkfs.ext4 /dev/sdb1
vi /etc/festab
mount /mountpointssh someone@somewhere
modeprobe ipt_MASQUERADE
echo 1 > /proc/sys/net/ipv4/ip_forwarding
iptables -t nat ...Sure, it was a bit more complicated than a few command lines, but I think you know what I mean. Oh, and does this one sound familiar to many of you?
ssh someone@somewhere
apt-get install pacemaker
#do many complicated stuffs
vi /etc/corosync/corosync.conf
#do other complicated requirements
crm configure property stonith...
crm configure property quorum...I spent my time deploying and maintaining systems, building resilient architectures, and debugging or fixing failing servers. It was the good old days!
A few years ago I switched to more customer facing jobs, like product marketing management and technical evangelism, where I used my knowledge to promote products with a good technical approach.
But now guess what? Things has changed. No seriously, when I have to put my fingers on a terminal, a lot of things are different. It’s not that /etc/init.d has been replaced by systemctl and no one is using screen anymore, but the way of thinking about deployments and resilient architectures is totally different.
Of course I’m not totally out of it, as I used to play around with OpenStack and understand microservices architectures on paper. But it takes a bit more practice to be comfortable speaking with real customers about real applications, deployed with a scalable architecture or in a cloud-native way on Kubernetes.
Sounds like a new adventure begins
I therefore suggest that you follow me on this journey: moving from a standalone, rock-solid deployment to an scalable architecture using the new primitives. I know the hype is around Kubernetes, but I also know a lot of people are not ready to go in that direction, because the knowledge base is not that easy to manage and the step is high as it is case for me.
I’m going to share what I’m going to discover, I’ll try to make it as simple as possible and keep an educational approach.
On this journey, I will be taking small steps, one step at a time, and this post is the first describing the basics and theory for building a scalable architecture.
Leaving pets village
For those unfamiliar with the pets vs cattle analogy, let’s say we’re in a village. Each villager has a handful of animals, not many of them. And each animal requires a lot of time from its owner to feed it, take care of it, play and educate it. They are pets, almost members of the family. And of course, our villagers invest affect and more into each animal. Therefore, losing a pet is really critical as it is unique and cannot be replaced.
Coming back to IT, in the past we deployed applications and servers with the same idea. We spent time on installation, maintenance. One server had very little in common with the others and for critical services we invest so much time in building HA (high availability) architectures with voting solutions like quorum devices, fencing tools like STONITH (Shoot The Other Node In The Head) drivers, or dormant resources with active/passive components.
We had to address at least those three questions:
- How can I scale my architecture when I need more power?
Usually the answer was “add more RAM” or “change to a better CPU”. Even if your infrastructure is virtualized, this approach has some limitations. - What should I do when something goes wrong?
Here was the debugging approach with a little urgency depending on your pet’s notoriety. - What if… (no words, it’s too hard) what if the worst happen?
And yes, you know that, like all of us… “shit happens”. This is where we used some corosync stuff and other cool tools.
Overall, you might have a smirk on Monday morning if you check the event logs and find that a big infrastructure failure popped up on Saturday night. You were in the middle of the 16th episode of the 5th season of Lost (yes we’re back in 2009), Locke just asked Ben to kill Jacob, and you completely missed the alert email asking you leave your sofa to fix the infra. But this Monday morning, you discovered with joy and happiness that your fantastic distributed system had worked as intended and put the system in degraded mode. And you were going to celebrate it with a double coffee because now you will have to go from degraded mode to normal mode and debug the failure.
That’s the pet village, the one many of us know pretty well. But like I said, the time has changed and we are leaving this place.
This is the pet village, the one that many of us know quite well. But as I said, times have changed and we are leaving this place.
Destination: the cattle land
The country we are going to is full of “collections of fabrics” or “groups of things”. There’s a big shed, a huge pasture, and you feed your cattle with tools like trucks and grain silos. In a sense, you are managing the cattle, not each head of cattle. I don’t want to sound like someone who doesn’t care about animal welfare, but in a cattle, a cow is much like another cow (sorry vegetarians). If a cow is missing, you can easily replace it, you see what I mean?
It’s the same for us, IT people. In this country, each component is not unique and shares a common configuration with the other in its group. The configuration has been industrialized, like a one-click deployment, and any component can be replaced by a command line, bringing us to a situation where losing a component is not a problem anymore.
And if we need to answer the precedent questions, it would look like:
- How can I scale my architecture when I need more power?
Easy, friend, you just need to add another component in the group. - What should I do when something goes wrong?
You could call the vet… but here I know an easier solution. You will say that I am cruel and I will say that I am talking about machines and software, not animals. What did you have in mind…? - What if the worst happen?
Here again, we’ll have everything to replace it easily.
On the road to cattle land
So the question is: how to do it? How do you move from a standalone deployment to a scalable architecture?
You might think you’ll have to rewrite everything and drop your app to rewrite a new one, but we’ve said we will be doing things step by step… So I would identify three main actions for our first step. These actions need to be addressed to move into cattle land:
- Identify the stateless and stateful components
- Move stateful component to managed services
- Industrialize stateless components
At this point, we may need some clarification on what a stateless component is: it’s a component that doesn’t store any data or status locally and share-nothing. All data that needs to be persisted should be stored in a stateful storage service, usually a database. In other words, you can lose/kill/remove/destroy (strike the unnecessary ones) any of the stateless components without impacting the application, because you won’t lose any data.
And the stateful components will be delegated to your cloud provider, like OVHcloud. They will be responsible for managing the high availability elements for you, usually the service offers this option.
Let’s try to explain it with some drawings. Let’s start with an application deployed in the pets village, a basic blog:
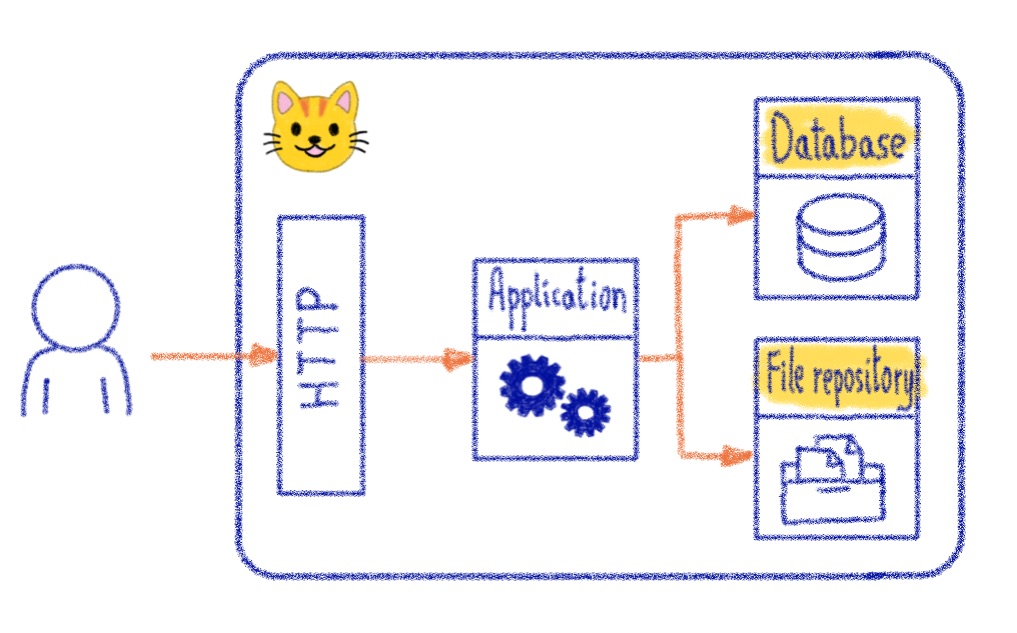
The large box represents our standalone server. Highlighted in yellow are the stateful components which are the database and the files (images). This is our data that we don’t want to lose a single byte. The rest of the application are stateless components.
Now see the target we are speaking about:
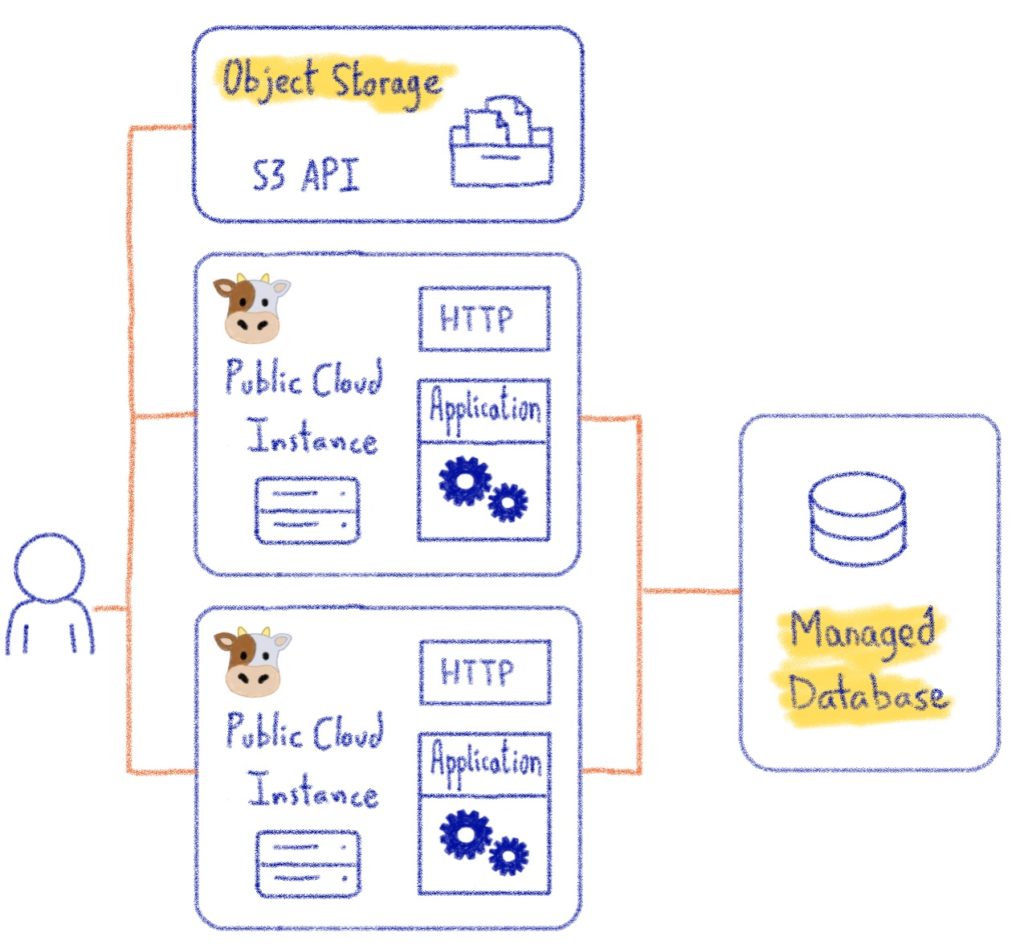
We’ll move our stateful component to managed services at OVHcloud. The MongoDB database will be hosted by Managed Databases for MongoDB service and the images will be pushed to Object Storage service which provide an S3 API.
Now we have dealt with the data, we can work to build our stateless component in a cattle mode. The road to the cattle land is marked out and we can move forward. Let’s see how to do that in the next post with a practical approach and some real demos.
Jean-Daniel used to be a technical guy working as system engineer on Linux and OpenStack. Since few years, he changed hats to develop marketing skills using the previous knowledge to serve the communication.