When faced with the challenge of building a managed Kubernetes service at OVH, fully based on open-source tools, we had to take some tough design decisions. Today we review one of them…
One of the most structural choices we made while building OVH Managed Kubernetes service was to deploy our customers’ clusters over our own ones. Kubinception indeed…
In this post we are relating our experience running Kubernetes over Kubernetes, with hundreds of customers’ clusters. Why did we choose this architecture? What are the main stakes with such a design? What problems did we encounter? How did we deal with those issues? And, even more important, if we had to take the decision today, would we choose again to do the Kubinception?
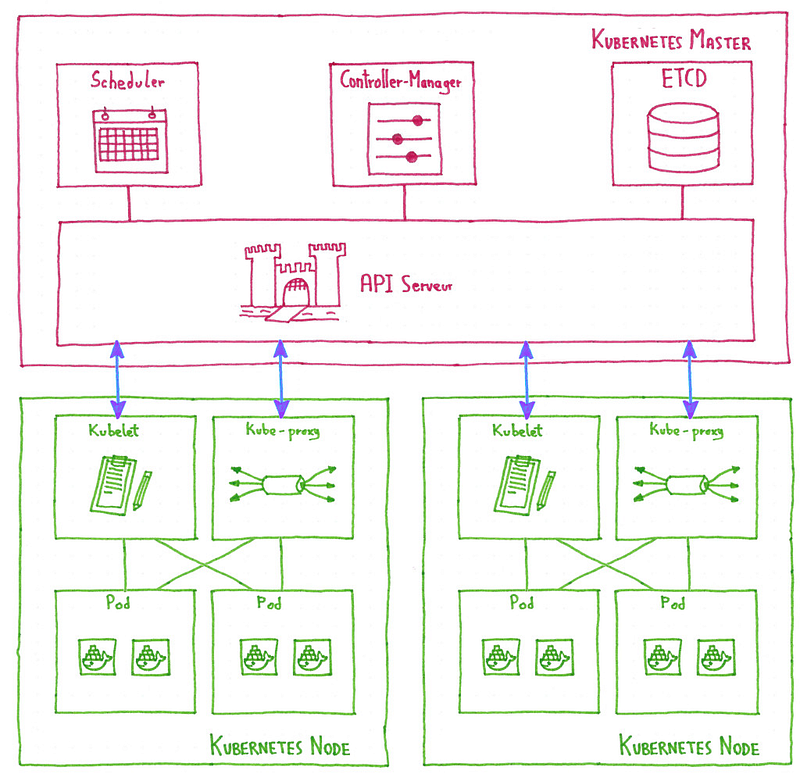
How does a Kubernetes cluster work?
To fully understand why we run Kubernetes on Kubernetes, we need at least a basic understanding of how a Kubernetes cluster works. A full explanation on this topic is out of the context of this post, but let’s do a quick summary:
A working Kubernetes cluster is composed of:
- A control plane that makes global decisions about the cluster, and detects and responds to cluster events. This control plane is composed of several master components.
- A set of nodes, worker instances containing the services necessary to run pods, with some node components running on every node, maintaining running pods and providing the Kubernetes runtime environment.
Master components
In this category of components we have:
- API Server: exposes the Kubernetes API. It is the entry-point for the Kubernetes control plane.
- Scheduler: watches newly created pods and selects a node for them to run on, managing ressource allocation.
- Controller-manager: run controllers, control loops that watch the state of the cluster and move it towards the desired state.
- ETCD: Consistent and highly-available key value store used as Kubernetes’ backing store for all cluster data. This topic deserves its own blog post, so we speaking about it in the coming weeks.
Node components
In every node we have:
- Kubelet: agent that makes sure that containers described in PodSpecs are running and healthy. It’s the link between the node and the control plane.
- Kube-proxy: network proxy running in each node, enabling the Kubernetes service abstraction by maintaining network rules and performing connection forwarding.
Our goal: quick and painless cluster deployment
How come did we go from this that simple Kubernetes architecture to a Kubernetes over Kubernetes one? The answer lies on one of our our main goals building OVH Managed Kubernetes service: to be able to deploy clusters in the simplest and most automated way.
And we didn't only want to deploy clusters, we wanted the deployed clusters to be:
- Resilient
- Isolated
- Cost-optimized
Kubinception: running Kubernetes over Kubernetes
The idea is to use a Kubernetes cluster we are calling admin cluster to deploy customer clusters.
As every Kubernetes cluster, the customer clusters have a set of nodes and a control plane, composed of several master components (API server, scheduler…).
What we are doing is to deploy those customer cluster master components as pods in the admin cluster nodes.
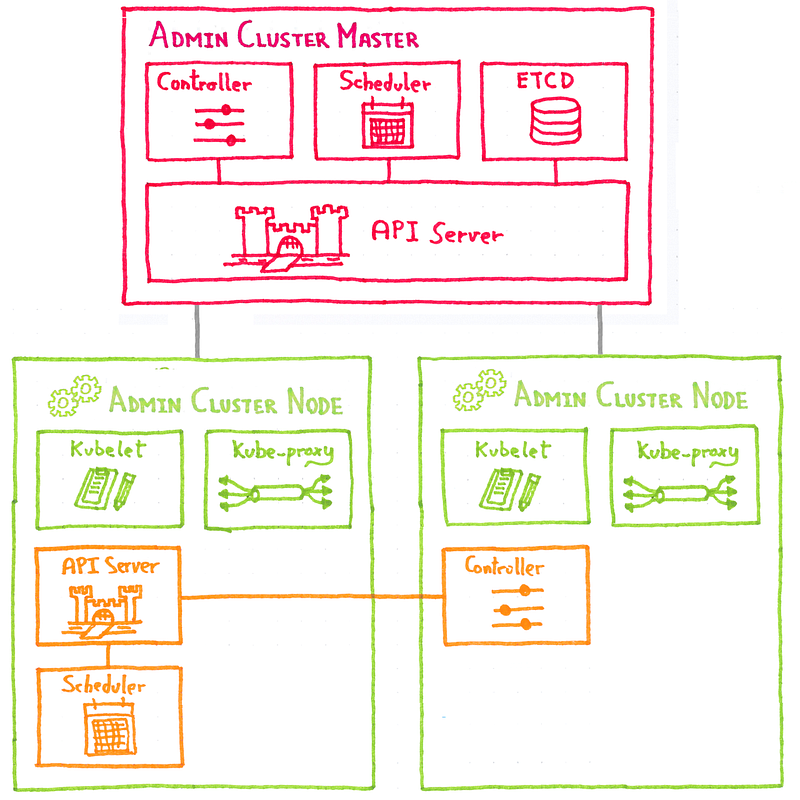
So now we have the stateless components of the customer cluster control plane running as pods in the admin cluster nodes. We haven’t spoken about the ETCD, as we will speak about it in a next post, for the moment let’s only say that is it a dedicated component, living outside Kubernetes.
And the customer cluster worker nodes? They are normal Kubernetes nodes: OVH public cloud instances connecting to the customer cluster API server running in an admin cluster pod.
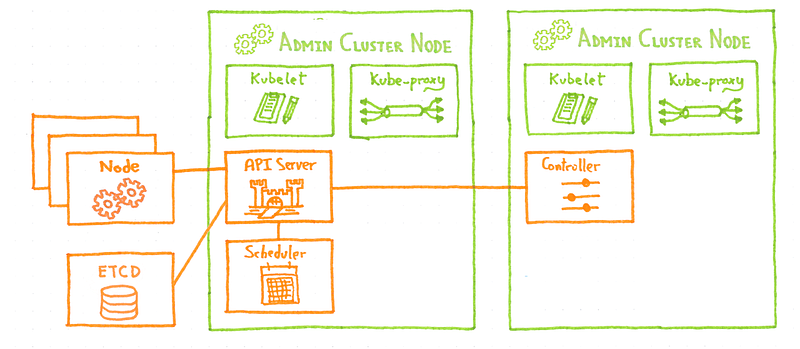
Our goal is to manage lots of cluster, not only one, so how can we add another customer cluster? As you could expect, we deploy the new customer cluster control plane on the admin cluster nodes.
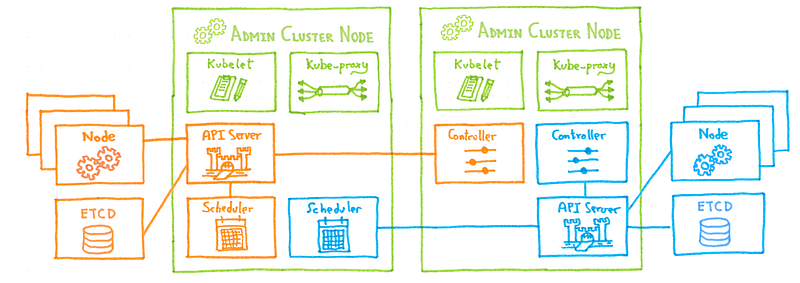
From the admin cluster point of view, we have simple deployed three new pods. Then we spawn some new node instances and connect an ETCD and the cluster is up.
If something can fail, it will do it
We have now an architecture that allows us to quickly deploy new clusters, but if we go back to our goal, quickly deployment was only half of it, we wanted the cluster to be resilient. Let’s begin with the resiliency.
The customer cluster nodes are already resilient, as they are vanilla Kubernetes nodes, and the ETCD resiliency will be detailed in a specific blog post, so let’s see the control plane resiliency, as it’s the specific part of our architecture.
And that’s the beauty of the Kubinception architecture, we are deploying the customer clusters control plane as simple, standard, vanilla pods in our admin cluster. And that means they are as resilient as any other Kubernetes pod: if one of the customer cluster master components goes down, the controller-manager of the admin cluster will detect it and the pod will be rescheduled and redeployed, without any manual action on our side.
What a better way to be sure that our Kubernetes is solid enough…
Basing our Managed Kubernetes service on Kubernetes made us to stumble on facets of Kubernetes we hadn’t found before, to learn lots of things about installing, deploying and operating Kubernetes. And all those knowledge and tooling was directly applied to our customers clusters, making the experience better for everybody.
And what about scaling
The whole system has been designed from the ground up with this idea of scaling The Kubernetes over Kubernetes architecture allows easy horizontal scaling. When an admin cluster begins to get too big, we can simply spawn a new one and deploy there the next customer control planes.
What’s next?
As this post is already long enough, so I leave the explanation on the ETCD for the next post in the series, in two weeks.
Next week let’s focus on another topic, we will deal with Apache Flink and how do we use it for handling alerts at OVH-scale…