A tutorial to create and build your own Speech-To-Text application with Python.
At the end of this first article, your Speech-To-Text application will be able to receive an audio recording and will generate its transcript!
Final code of the app is available in our dedicated GitHub repository.
Overview of our final app
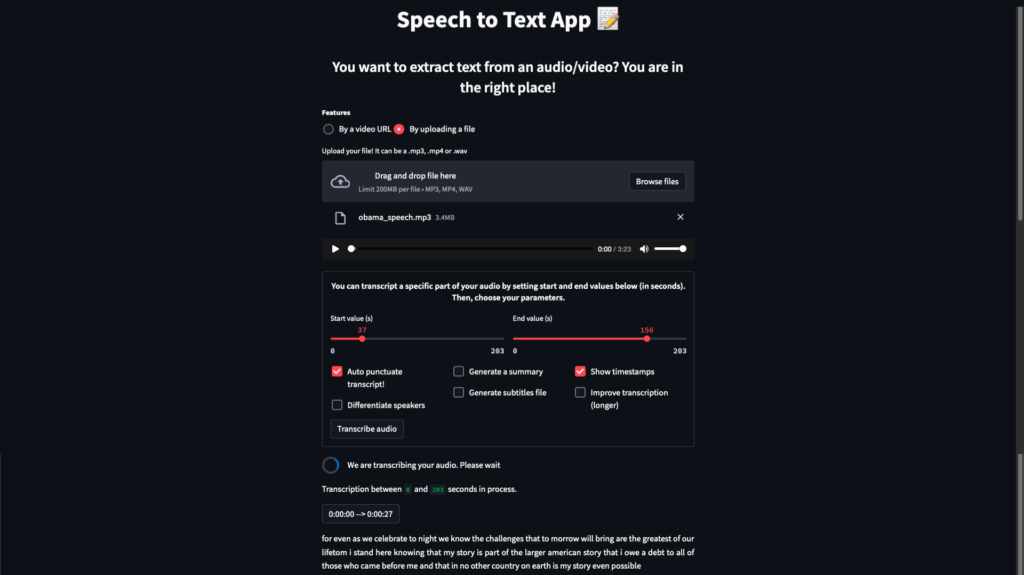
Overview of our final Speech-To-Text application
Objective
In the previous notebook tutorials, we have seen how to translate speech into text, how to punctuate the transcript and summarize it. We have also seen how to distinguish speakers and how to generate video subtitles, all the while managing potential memory problems.
Now that we know how to do all this, let's combine all these features together into a Speech-To-Text application using Python!
➡ To create this app, we will use Streamlit, a Python framework that turns scripts into a shareable web application. If you don't know this tool, don't worry, it is very simple to use.
This article is organized as follows:
- Import code from previous tutorials
- Write the Streamlit App
- Run your app!
In the following articles, we will see how to implement the more advanced features (diarization, summarization, punctuation, …), and we will also learn how to build and use a custom Docker image for a Streamlit application, which will allow us to deploy our app on AI Deploy !
⚠️ Since this article uses code already explained in the previous notebook tutorials, we will not re-explain its usefulness here. We therefore recommend that you read the notebooks first.
Import code from previous tutorials
1. Set up the environment
To start, let's create our Python environment. To do this, create a file named requirements.txt and add the following text to it. This will allow us to specify each version of the libraries required by our Speech to text project.
librosa==0.9.1
youtube_dl==2021.12.17
streamlit==1.9.0
transformers==4.18.0
httplib2==0.20.2
torch==1.11.0
torchaudio==0.11.0
sentencepiece==0.1.96
tokenizers==0.12.1
pyannote.audio==2.1.1
pyannote.core==4.4
pydub==0.25.1Then, you can install all these elements in only one command. To do so, you just have to open a terminal and enter the following command:
pip install -r requirements.txt2. Import libraries
Once your environment is ready, create a file named app.py and import the required libraries we used in the notebooks.
They will allow us to use artificial intelligence models, to manipulate audio files, times, …
# Models
import torch
from transformers import Wav2Vec2Processor, HubertForCTC
# Audio Manipulation
import audioread
import librosa
from pydub import AudioSegment, silence
import youtube_dl
from youtube_dl import DownloadError
# Others
from datetime import timedelta
import os
import streamlit as st
import time3. Functions
We also need to use some previous functions, you will probably recognize some of them.
⚠️ Reminder: All this code has been explained in the notebook tutorials. That's why we will not re-explain its usefulness here.
To begin, let's create the function that allows you to transcribe an audio chunk.
def transcribe_audio_part(filename, stt_model, stt_tokenizer, myaudio, sub_start, sub_end, index):
device = "cuda" if torch.cuda.is_available() else "cpu"
try:
with torch.no_grad():
new_audio = myaudio[sub_start:sub_end] # Works in milliseconds
path = filename[:-3] + "audio_" + str(index) + ".mp3"
new_audio.export(path) # Exports to a mp3 file in the current path
# Load audio file with librosa, set sound rate to 16000 Hz because the model we use was trained on 16000 Hz data
input_audio, _ = librosa.load(path, sr=16000)
# return PyTorch torch.Tensor instead of a list of python integers thanks to return_tensors = ‘pt’
input_values = stt_tokenizer(input_audio, return_tensors="pt").to(device).input_values
# Get logits from the data structure containing all the information returned by the model and get our prediction
logits = stt_model.to(device)(input_values).logits
prediction = torch.argmax(logits, dim=-1)
# Decode & lower our string (model's output is only uppercase)
if isinstance(stt_tokenizer, Wav2Vec2Tokenizer):
transcription = stt_tokenizer.batch_decode(prediction)[0]
elif isinstance(stt_tokenizer, Wav2Vec2Processor):
transcription = stt_tokenizer.decode(prediction[0])
# return transcription
return transcription.lower()
except audioread.NoBackendError:
# Means we have a chunk with a [value1 : value2] case with value1>value2
st.error("Sorry, seems we have a problem on our side. Please change start & end values.")
time.sleep(3)
st.stop()Then, create the four functions that allow silence detection method, which we have explained in the first notebook tutorial.
Get the timestamps of the silences
def detect_silences(audio):
# Get Decibels (dB) so silences detection depends on the audio instead of a fixed value
dbfs = audio.dBFS
# Get silences timestamps > 750ms
silence_list = silence.detect_silence(audio, min_silence_len=750, silence_thresh=dbfs-14)
return silence_listGet the middle value of each timestamp
def get_middle_silence_time(silence_list):
length = len(silence_list)
index = 0
while index < length:
diff = (silence_list[index][1] - silence_list[index][0])
if diff < 3500:
silence_list[index] = silence_list[index][0] + diff/2
index += 1
else:
adapted_diff = 1500
silence_list.insert(index+1, silence_list[index][1] - adapted_diff)
silence_list[index] = silence_list[index][0] + adapted_diff
length += 1
index += 2
return silence_listCreate a regular distribution, which merges the timestamps according to a min_space and a max_space value.
def silences_distribution(silence_list, min_space, max_space, start, end, srt_token=False):
# If starts != 0, we need to adjust end value since silences detection is performed on the trimmed/cut audio
# (and not on the original audio) (ex: trim audio from 20s to 2m will be 0s to 1m40 = 2m-20s)
# Shift the end according to the start value
end -= start
start = 0
end *= 1000
# Step 1 - Add start value
newsilence = [start]
# Step 2 - Create a regular distribution between start and the first element of silence_list to don't have a gap > max_space and run out of memory
# example newsilence = [0] and silence_list starts with 100000 => It will create a massive gap [0, 100000]
if silence_list[0] - max_space > newsilence[0]:
for i in range(int(newsilence[0]), int(silence_list[0]), max_space): # int bc float can't be in a range loop
value = i + max_space
if value < silence_list[0]:
newsilence.append(value)
# Step 3 - Create a regular distribution until the last value of the silence_list
min_desired_value = newsilence[-1]
max_desired_value = newsilence[-1]
nb_values = len(silence_list)
while nb_values != 0:
max_desired_value += max_space
# Get a window of the values greater than min_desired_value and lower than max_desired_value
silence_window = list(filter(lambda x: min_desired_value < x <= max_desired_value, silence_list))
if silence_window != []:
# Get the nearest value we can to min_desired_value or max_desired_value depending on srt_token
if srt_token:
nearest_value = min(silence_window, key=lambda x: abs(x - min_desired_value))
nb_values -= silence_window.index(nearest_value) + 1 # (index begins at 0, so we add 1)
else:
nearest_value = min(silence_window, key=lambda x: abs(x - max_desired_value))
# Max value index = len of the list
nb_values -= len(silence_window)
# Append the nearest value to our list
newsilence.append(nearest_value)
# If silence_window is empty we add the max_space value to the last one to create an automatic cut and avoid multiple audio cutting
else:
newsilence.append(newsilence[-1] + max_space)
min_desired_value = newsilence[-1]
max_desired_value = newsilence[-1]
# Step 4 - Add the final value (end)
if end - newsilence[-1] > min_space:
# Gap > Min Space
if end - newsilence[-1] < max_space:
newsilence.append(end)
else:
# Gap too important between the last list value and the end value
# We need to create automatic max_space cut till the end
newsilence = generate_regular_split_till_end(newsilence, end, min_space, max_space)
else:
# Gap < Min Space <=> Final value and last value of new silence are too close, need to merge
if len(newsilence) >= 2:
if end - newsilence[-2] <= max_space:
# Replace if gap is not too important
newsilence[-1] = end
else:
newsilence.append(end)
else:
if end - newsilence[-1] <= max_space:
# Replace if gap is not too important
newsilence[-1] = end
else:
newsilence.append(end)
return newsilenceAdd automatic "time cuts" to the silence list till end value depending on min_space and max_space values:
def generate_regular_split_till_end(time_list, end, min_space, max_space):
# In range loop can't handle float values so we convert to int
int_last_value = int(time_list[-1])
int_end = int(end)
# Add maxspace to the last list value and add this value to the list
for i in range(int_last_value, int_end, max_space):
value = i + max_space
if value < end:
time_list.append(value)
# Fix last automatic cut
# If small gap (ex: 395 000, with end = 400 000)
if end - time_list[-1] < min_space:
time_list[-1] = end
else:
# If important gap (ex: 311 000 then 356 000, with end = 400 000, can't replace and then have 311k to 400k)
time_list.append(end)
return time_listCreate a function to clean the directory where we save the sounds and the audio chunks, so we do not keep them after transcribing:
def clean_directory(path):
for file in os.listdir(path):
os.remove(os.path.join(path, file))Write the Streamlit application code
1. Configuration of the application
Now that we have the basics, we can create the function that allows to configure the app. It will give a title and an icon to our app, and will create a data directory so that the application can store sounds files in it. Here is the function:
def config():
st.set_page_config(page_title="Speech to Text", page_icon="📝")
# Create a data directory to store our audio files
# Will not be executed with AI Deploy because it is indicated in the DockerFile of the app
if not os.path.exists("../data"):
os.makedirs("../data")
# Display Text and CSS
st.title("Speech to Text App 📝")
st.subheader("You want to extract text from an audio/video? You are in the right place!")As you can see, this data directory is located at the root of the parent directory (indicated by the ../ notation). It will only be created if the application is launched locally on your computer, since AI Deploy has this folder pre-created.
➡️ We recommend that you do not change the location of the data directory (../). Indeed, this location makes it easy to juggle between running the application locally or on AI Deploy.
2. Load the speech to text model
Create the function that allows to load the speech to text model.
As we are starting out, we only import the transcription model for the moment. We will implement the other features in the following article 😉.
⚠️ Here, the use case is English speech recognition, but you can do it in another language thanks to one of the many models available on the Hugging Face website. In this case, just keep in mind that you won't be able to combine it with some of the models we will use in the next article, since some of them only work on English transcripts.
@st.cache(allow_output_mutation=True)
def load_models():
# Load Wav2Vec2 (Transcriber model)
stt_model = HubertForCTC.from_pretrained("facebook/hubert-large-ls960-ft")
stt_tokenizer = Wav2Vec2Processor.from_pretrained("facebook/hubert-large-ls960-ft")
return stt_tokenizer, stt_modelWe use a @st.cache(allow_output_mutation=True) here. This tells Streamlit to run the function and stores the results in a local cache, so next time we call the function (app refreshment), Streamlit knows it can skip executing this function. Indeed, since we have already imported the model(s) one time (initialization of the app), we must not waste time to reload them each time we want to transcribe a new file.
However, downloading the model when initializing the application takes time since it depends on certain factors such as our Internet connection. For one model, this is not a problem because the download time is still quite fast. But with all the models we plan to load in the next article, this initialization time may be longer, which would be frustrating 😪.
➡️ That's why we will propose a way to solve this problem in a next blog post.
3. Get an audio file
Once we have loaded the model, we need an audio file to use it 🎵!
For this we will realize two features. The first one will allow the user to import his own audio file. The second one will allow him to indicate a video URL for which he wants to obtain the transcript.
3.1. Allow the user to upload a file (mp3/mp4/wav)
Let the user upload his own audio file thanks to a st.file_uploader() widget:
def transcript_from_file(stt_tokenizer, stt_model):
uploaded_file = st.file_uploader("Upload your file! It can be a .mp3, .mp4 or .wav", type=["mp3", "mp4", "wav"])
if uploaded_file is not None:
# get name and launch transcription function
filename = uploaded_file.name
transcription(stt_tokenizer, stt_model, filename, uploaded_file)As you can see, if the uploaded_file variable is not None, which means the user has uploaded an audio file, we launch the transcribe process by calling the transcription() function that we will soon create.
3.2. Transcribe a video from YouTube
Create the function that allows to download the audio from a valid YouTube link:
def extract_audio_from_yt_video(url):
filename = "yt_download_" + url[-11:] + ".mp3"
try:
ydl_opts = {
'format': 'bestaudio/best',
'outtmpl': filename,
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
}],
}
with st.spinner("We are extracting the audio from the video"):
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
ydl.download([url])
# Handle DownloadError: ERROR: unable to download video data: HTTP Error 403: Forbidden / happens sometimes
except DownloadError:
filename = None
return filename⚠️ If you are not the administrator of your computer, this function may not work for local execution.
Then, we need to display an element that allows the user to indicate the URL they want to transcribe.
We can do it thanks to the st.text_input() widget. The user will be able to type in the URL of the video that interests him. Then, we make a quick verification: if the entered link seems correct (contains the pattern of a YouTube link : "youtu"), we try to extract the audio from the URL's video, and then transcribe it.
This is what the following function does:
def transcript_from_url(stt_tokenizer, stt_model):
url = st.text_input("Enter the YouTube video URL then press Enter to confirm!")
# If link seems correct, we try to transcribe
if "youtu" in url:
filename = extract_audio_from_yt_video(url)
if filename is not None:
transcription(stt_tokenizer, stt_model, filename)
else:
st.error("We were unable to extract the audio. Please verify your link, retry or choose another video")4. Transcribe the audio file
Now, we have to write the functions that links the majority of those we have already defined.
To begin, we write the code of the init_transcription() function. It informs the user that the transcription of the audio file is starting and that it will transcribe the audio from start seconds to end seconds. For the moment, these values correspond to the temporal ends of the audio (0s and the audio length). So it is not really interesting, but it will be useful in the next episode 😌!
This function also initializes some variables. Among them, srt_text and save_results are variables that we will also use in the following article. Do not worry about them for now.
def init_transcription(start, end):
st.write("Transcription between", start, "and", end, "seconds in process.\n\n")
txt_text = ""
srt_text = ""
save_result = []
return txt_text, srt_text, save_resultWe have the functions that perform the silences detection method and that transcribe an audio file. But now we need to link all these functions. The function transcription_non_diarization() will do it for us:
def transcription_non_diarization(filename, myaudio, start, end, srt_token, stt_model, stt_tokenizer, min_space, max_space, save_result, txt_text, srt_text):
# get silences
silence_list = detect_silences(myaudio)
if silence_list != []:
silence_list = get_middle_silence_time(silence_list)
silence_list = silences_distribution(silence_list, min_space, max_space, start, end, srt_token)
else:
silence_list = generate_regular_split_till_end(silence_list, int(end), min_space, max_space)
# Transcribe each audio chunk (from timestamp to timestamp) and display transcript
for i in range(0, len(silence_list) - 1):
sub_start = silence_list[i]
sub_end = silence_list[i + 1]
transcription = transcribe_audio_part(filename, stt_model, stt_tokenizer, myaudio, sub_start, sub_end, i)
if transcription != "":
save_result, txt_text, srt_text = display_transcription(transcription, save_result, txt_text, srt_text, sub_start, sub_end)
return save_result, txt_text, srt_textYou will notice that this function calls the display_transcription() function, which displays the right elements according to the parameters chosen by the user.
For the moment, the display is basic since we have not yet added the user's parameters. This is why we will modify this function in the next article, in order to be able to handle different display cases, depending on the selected parameters.
You can add it to your app.py file:
def display_transcription(transcription, save_result, txt_text, srt_text, sub_start, sub_end):
temp_timestamps = str(timedelta(milliseconds=sub_start)).split(".")[0] + " --> " + str(timedelta(milliseconds=sub_end)).split(".")[0] + "\n"
temp_list = [temp_timestamps, transcription, int(sub_start / 1000)]
save_result.append(temp_list)
st.write(temp_timestamps)
st.write(transcription + "\n\n")
txt_text += transcription + " " # So x seconds sentences are separated
return save_result, txt_text, srt_textOnce this is done, all you have to do is display all the elements and link them using the transcription() function:
def transcription(stt_tokenizer, stt_model, filename, uploaded_file=None):
# If the audio comes from the YouTube extracting mode, the audio is downloaded so the uploaded_file is
# the same as the filename. We need to change the uploaded_file which is currently set to None
if uploaded_file is None:
uploaded_file = filename
# Get audio length of the file(s)
myaudio = AudioSegment.from_file(uploaded_file)
audio_length = myaudio.duration_seconds
# Display audio file
st.audio(uploaded_file)
# Is transcription possible
if audio_length > 0:
# display a button so the user can launch the transcribe process
transcript_btn = st.button("Transcribe")
# if button is clicked
if transcript_btn:
# Transcribe process is running
with st.spinner("We are transcribing your audio. Please wait"):
# Init variables
start = 0
end = audio_length
txt_text, srt_text, save_result = init_transcription(start, int(end))
srt_token = False
min_space = 25000
max_space = 45000
# Non Diarization Mode
filename = "../data/" + filename
# Transcribe process with Non Diarization Mode
save_result, txt_text, srt_text = transcription_non_diarization(filename, myaudio, start, end, srt_token, stt_model, stt_tokenizer, min_space, max_space, save_result, txt_text, srt_text)
# Delete files
clean_directory("../data") # clean folder that contains generated files
# Display the final transcript
if txt_text != "":
st.subheader("Final text is")
st.write(txt_text)
else:
st.write("Transcription impossible, a problem occurred with your audio or your parameters, we apologize :(")
else:
st.error("Seems your audio is 0 s long, please change your file")
time.sleep(3)
st.stop()This huge function looks like our main block code. It almost gathers all the implemented functionalities.
First of all, it retrieves the length of the audio file and allows the user to play it with a st.audio(), a widget that displays an audio player. Then, if the audio length is greater than 0s and the user clicks on the "Transcribe" button, the transcription is launched.
The user knows that the code is running since all the script is placed in a st.spinner(), which is displayed as a loading spinner on the app.
In this code, we initialize some variables. For the moment, we set the srt_token to False, since we are not going to generate subtitles (we will do it in next tutorials as I mentioned).
Then, the location of the audio file is indicated (remember it is in our ../data directory). The transcription process is at that time really started as the function transcription_non_diarization() is called. The audio file is transcribed from chunk to chunk, and the transcript is displayed part by part, with the corresponding timestamps.
Once finished, we can clean up the directory where all the chunks are located, and the final text is displayed.
5. Main
All that remains is to define the main, global architecture of our application.
We just need to create a st.radio() button widget so the user can either choose to transcribe his own file by importing it, or an external file by entering the URL of a video. Depending on the radio button value, we launch the right function (transcript from URL or from file).
if __name__ == '__main__':
config()
choice = st.radio("Features", ["By a video URL", "By uploading a file"])
stt_tokenizer, stt_model = load_models()
if choice == "By a video URL":
transcript_from_url(stt_tokenizer, stt_model)
elif choice == "By uploading a file":
transcript_from_file(stt_tokenizer, stt_model)Run your app!
We can already try our program! Indeed, run your code and enter the following command in your terminal. The Streamlit application will open in a tab of your browser.
streamlit run path_of_your_project/app.py
⚠️⚠️ If this is the first time you manipulate audio files on your computer, you may get some OSErrors about the libsndfile, ffprobe and ffmpeg libraries.
Don't worry, you can easily fix these errors by installing them. The command will be different depending on the OS you are using. For example, on Linux, you can use apt-get:
sudo apt-get install libsndfile-dev
sudo apt-get install ffmpegconda install -c main ffmpeg
If the application launches without error, congratulations 👏 ! You are now able to choose a YouTube video or import your own audio file into the application and get its transcript!
😪 Unfortunately, local resources may not be powerful enough to get a transcript in just a few seconds, which is quite frustrating.
➡️ To save time, you can run your app on GPUs thanks to AI Deploy. To do this, please refer to this documentation to boot it up.
You can see what we have built on the following video:
Quick demonstration of our Speech-To-Text application after completing this first tutorial
Conclusion
Well done 🥳 ! You are now able to import your own audio file on the app and get your first transcript!
You could be satisfied with that, but we can do so much better!
Indeed, our Speech-To-Text application is still very basic. We need to implement new functions like speakers differentiation, transcripts summarization, or punctuation, and also other essential functionalities like the possibility to trim/cut an audio, to download the transcript, interact with the timestamps, justify the text, ...
➡️ If you want to improve your Streamlit application, follow the next article 😉.