
Intro
TL;DR: You might want to skip the intro and jump right into “Celery – Distributed Task Queue”.

Hello! I’m Bartosz Rabiega, and I’m part of the R&D/DevOps teams at OVHcloud. As part of our daily work, we’re developing and maintaining the Ceph-as-a-Service project, in order to provide highly available, solid, distributed storage for various applications. We’re dealing with 60PB+ of data, across 10 regions, so as you might imagine, we’ve got quite a lot of work ahead in terms of replacing broken hardware, handling natural growth, provisioning new regions and datacentres, evaluating new hardware, optimising software and hardware configurations, researching new storage solutions, and much more!

Because of the wide scope of our work, we need to offload as many repetitive tasks as possible. And we do that through automation.
Automating your work
To some extent, every manual process can be described as set of actions and conditions. If we somehow managed to force something to automatically perform the actions and check the conditions, we would be able to automate the process, resulting in an automated workflow. Take a look at the example below, which shows some generic steps for manually replacing hardware in our project.

Hmm… What could help us do this automatically? Doesn’t a computer sound like a perfect fit? 🙂 There are many ways to force computers to process automated workflows, but first we need to define some building blocks (let’s call them tasks) and get them to run sequentially or in parallel (i.e. a workflow). Fortunately, there are software solutions that can help with that, among which is Celery.
Celery – Distributed Task Queue
Celery is a well-known and widely adopted piece of software that allows us to process tasks asynchronously. The description of the project on its main page (http://www.celeryproject.org/) may sound a little bit enigmatic, but we can narrow down its basic functionality to something like this:

Such machinery is perfectly suited to tasks like sending emails asynchronously (i.e. ‘fire and forget’), but it can also be used for different purposes. So what other tasks could it handle? Basically, any tasks you can implement in Python (the main Celery language)! I won’t go too much into the details, as they are available in the Celery documentation. What matters is that since we can implement any task we want, we can use that to create the building blocks for our automation.
There is one more important thing… Celery natively supports combining such tasks into workflows (Celery primitives: chains, groups, chords, etc.). So let’s get through some examples…
We’ll use the following task definitions – single task, printing args and kwargs:
@celery_app.task
def noop(*args, **kwargs):
# Task accepts any arguments and does nothing
print(args, kwargs)
return TrueNow we can execute the task asynchronously, using the following code:
task = noop.s(777)
task.apply_async()The elementary tasks can be parametrised and combined into a complex workflow using celery methods, i.e. “chain”, “group”, and “chord”. See the examples below. In each of them, the left side shows a visual representation of a workflow, while the right side shows the code snippet that generates it. The green box is the starting point, after which the workflow execution progresses vertically.
Chain – a set of tasks processed sequentially

workflow = (
chain([noop.s(i) for i in range(3)])
)Group – a set of tasks processed in parallel

workflow = (
group([noop.s(i) for i in range(5)])
)Chord – a group of tasks chained to the following task

workflow = chord(
[noop.s(i) for i in range(5)],
noop.s(i)
)
# Equivalent:
workflow = chain([
group([noop.s(i) for i in range(5)]),
noop.s(i)
])An important point: the execution of a workflow will always stop in the event of a failed task. As a result, a chain won’t be continued if some task fails in the middle of it. This gives us quite a powerful framework for implementing some neat automation, and that’s exactly what we’re using for Ceph-as-a-Service at OVHcloud! We’ve implemented lots of small, flexible, parameterisable tasks, which we combine together to reach a common goal. Here are some real-life examples of elementary tasks, used for the automatic removal of old hardware:
- Change weight of Ceph node (used to increase/decrease the amount of data on node. Triggers data rebalance)
- Set service downtime (data rebalance triggers monitoring probes, but this is expected, so set downtime for this particular monitoring entry)
- Wait until Ceph is healthy (wait until the data rebalance is complete – repeating task)
- Remove Ceph node from a cluster (node is empty so it can simply be uninstalled)
- Send info to technicians in DC (hardware is ready to be replaced)
- Add new Ceph node to a cluster (install new empty node)
We parametrise these tasks and tie them together, using Celery chains, groups and chords to create the desired workflow. Celery then does the rest by asynchronously executing the workflow.
Big workflows and Celery
As our infrastructure grows, so doo our automated workflows grow, with more tasks per workflow, higher complexity of workflows… What do we understand as a big workflow? A workflow consisting of 1,000-10,000 tasks. Just to visualize it take a look on following examples:
A few chords chained together (57 tasks in total)
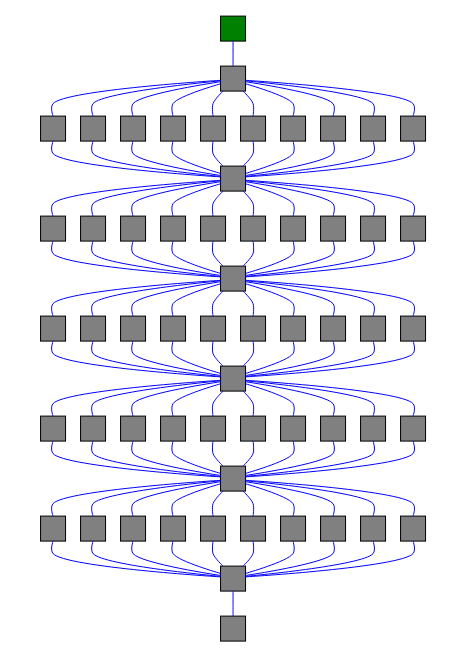
workflow = chain([
noop.s(0),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
noop.s()
])More complex graph structure built from chains and groups (23 tasks in total)
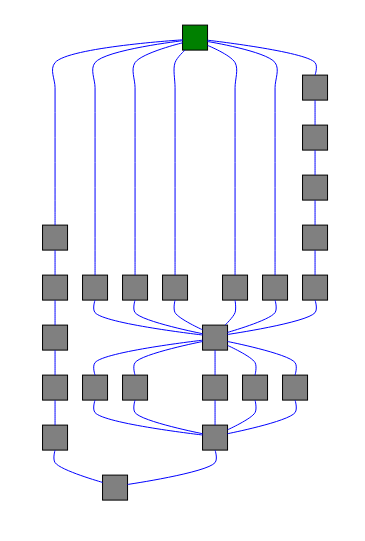
# | is ‘chain’ operator in celery
workflow = (
group(
group(
group([noop.s() for i in range(5)]),
chain([noop.s() for i in range(5)])
) |
noop.s() |
group([noop.s() for i in range(5)]) |
noop.s(),
chain([noop.s() for i in range(5)])
) |
noop.s()
)As you can probably imagine, visualisations get quite big and messy when 1,000 tasks are involved! Celery is a powerful tool, and has lots of features that are well-suited for automation, but it still struggles when it comes to processing big, complex, long-running workflows. Orchestrating the execution of 10,000 tasks, with a variety of dependencies, is no trivial thing. There are several issues we encountered when our automation grew too big:
- Memory issues during workflow building (client side)
- Serialisation issues (client -> Celery backend transfer)
- Nondeterministic, broken execution of workflows
- Memory issues in Celery workers (Celery backend)
- Disappearing tasks
- And more…
Take a look at some GitHub tickets:
- https://github.com/celery/celery/issues/5000
- https://github.com/celery/celery/issues/5286
- https://github.com/celery/celery/issues/5327
- https://github.com/celery/celery/issues/3723
Using Celery for our particular use case became difficult and unreliable. Celery’s native support for workflows doesn’t seem to be the right choice for handling 100/1,000/10,000 tasks. In its current state, it’s just not enough. So here we stand, in front of a solid, concrete wall… Either we somehow fix Celery, or we rewrite our automation using a different framework.
Celery – to fix… or to fix?
Rewriting all of our automation would be possible, although relatively painful. Since I’m a rather lazy person, perhaps attempting to fix Celery wasn’t an entirely bad idea? So I took some time to dig through Celery’s code, and managed to find the parts responsible for building workflows, and executing chains and chords. It was still a little bit difficult for me to understand all the different code paths handling the wide range of use cases, but I realised it would be possible to implement a clean, straightforward orchestration that would handle all the tasks and their combinations in the same way. What’s more, I had a glimpse that it wouldn’t take too much effort to integrate it into our automation (let’s not forget the main goal!).
Unfortunately, introducing new orchestration into the Celery project would probably be quite hard, and would most likely break some backwards compatibility. So I decided to take a different approach – writing an extension or a plugin that wouldn’t require changes in Celery. Something pluggable, and as non-invasive as possible. That’s how Celery Dyrygent emerged…
Celery Dyrygent
https://github.com/ovh/celery-dyrygent
How to represent a workflow
You can think of a workflow as a directed acyclic graph (DAG), where each task is a separate graph node. When it comes to acyclic graphs, it is relatively easy to store and resolve dependencies between nodes, which leads to straightforward orchestration. Celery Dyrygent was implemented based on these features. Each task in the workflow has an unique identifier (Celery already assigns task IDs when a task is pushed for execution) and each one of them is wrapped into a workflow node. Each workflow node consists of a task signature (a plain Celery signature) and a list of IDs for the tasks it depends on. See the example below:

How to process a workflow
So we know how to store a workflow in a clean and easy way. Now we just need to execute it. How about using… Celery? Why not? For this, Celery Dyrygent introduces a workflow processor task (an ordinary Celery task). This task wraps a whole workflow and schedules an execution of primitive tasks, according to their dependencies. Once the scheduling part is over, the task repeats itself (it ‘ticks’ with some delay).
Throughout the whole processing cycle, workflow processor retains the state of the entire workflow internally. As a result, it updates the state with each repetition. You can see an orchestration example below:



Most notably, workflow processor stops its execution in two cases:
- Once the whole workflow finishes, with all tasks successfully completed
- When it can’t proceed any further, due to a failed task
How to integrate
So how do we use this? Fortunately, I was able to find a way to use Celery Dyrygent quite easily. First of all, you need to inject the workflow processor task definition into your Celery applicationP:
from celery_dyrygent.tasks import register_workflow_processor
app = Celery() # your celery application instance
workflow_processor = register_workflow_processor(app)Next, you need to convert your Celery defined workflow into a Celery Dyrygent workflow:
from celery_dyrygent.workflows import Workflow
celery_workflow = chain([
noop.s(0),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
chord([noop.s(i) for i in range(10)], noop.s()),
noop.s()
])
workflow = Workflow()
workflow.add_celery_canvas(celery_workflow)Finally, simply execute the workflow, just as you would an ordinary Celery task:
workflow.apply_async()That’s it! You can always go back if you wish, as the small changes are very easy to undo.
Give it a try!
Celery Dyrygent is free to use, and its source code is available on Github (https://github.com/ovh/celery-dyrygent). Feel free to use it, improve it, request features, and report any bugs! It has a few additional features not described here, so I’d encourage you to take a look at the project’s readme file. For our automation requirements, it’s already a solid, battle-tested solution. We’ve been using it since the end of 2018, and it has processed thousands of workflows, consisting of hundreds of thousands of tasks. Here are some productions stats, from June 2019 to February 2020:
- 936,248 elementary tasks executed
- 11,170 workflows processed
- 4,098 tasks in the biggest workflow so far
- ~84 tasks per workflow, on average
Automation is always a good idea!
DevOps Engineer
IT professional since 2011 as QA Specialist, System Analyst and Software Developer. Since 2016 working as DevOps engineer in Ceph as a Service team at OVH (Poland).
Develops and takes daily care of Ceph as a Service project providing 250+ ceph clusters.