
This article is a joint collaboration between OVHcloud and Facets Cloud.
Over the past few years, the speed at which teams can build infrastructure has changed dramatically. Models that once took weeks to train can now be iterated in days. Tooling has improved, workflows have matured, and the overall friction in getting from idea to working output has reduced significantly.
But this acceleration often stops the moment teams try to deploy — and this can make AI deployment frustrating. In this blog, you will learn how Facets can help teams accelerate migration to OVHcloud by making deployment more structured, repeatable and predictable.
What first begins as a fast, iterative process slows down when it enters the infrastructure layer. The work is no longer about models or code. It shifts to provisioning environments, configuring pipelines, managing permissions, setting up networking, and ensuring that everything works reliably outside a controlled development setting. This phase is not inherently complex, but it is fragmented, and that introduces delay.
As a result, there is now a visible gap between how quickly teams can build and how slowly they can move to production. The model may be ready in hours, but the surrounding system required to run it still takes days, weeks, or in some cases even months, to put together.
AI deployment is slow because infrastructure is inconsistent, not because AI is limited
It is tempting to assume that deployment delays are still a technical limitation but, in most cases, that is no longer true. The bottleneck is not the model itself. It is everything around it.
Infrastructure is rarely standardised across teams. Each project tends to define its own setup, its own pipeline, and its own configuration. Even when teams use the same tools, the way those tools are applied differs just enough to create inconsistency.
Over time, these differences accumulate. Environments are recreated, pipelines are reconfigured, dependencies are re-evaluated, and access is managed manually. What should be a repeatable process becomes a fresh effort every time.
This is where deployment slows down. Not because teams cannot build quickly, but because the systems around deployment are not structured for reuse.
Faster deployment starts with reusable infrastructure
Teams that deploy faster do not necessarily rely on fundamentally different tools. They change how infrastructure is organised.
Instead of treating infrastructure as something that needs to be set up for every project, they define it once and reuse it. Environments are created from standard definitions rather than being handcrafted. Deployment workflows follow consistent patterns instead of being recreated each time. Access, policies and guardrails are built into the system rather than handled separately.
This does not eliminate complexity, but it contains it. Systems become easier to understand, easier to operate and easier to extend. Most importantly, they become predictable.
Once infrastructure behaves predictably, deployment stops being a recurring source of delay.
AI improves operations only when infrastructure is already structured as a system
There is growing interest in applying AI to DevOps and infrastructure management, but its role is often misunderstood.
AI does not fix fragmented systems. If the underlying setup is inconsistent, AI will only automate that inconsistency. It may reduce effort in specific tasks, but it does not create structure on its own.
AI becomes valuable when it operates on top of a well-defined system. It can help teams understand system state, identify issues faster, assist with debugging, and reduce manual operational work. But it works best when the infrastructure beneath it is already standardised, reusable and consistent.
Infrastructure needs to shift from project-level setup to a standardised system
As AI accelerates development, the limitations of infrastructure become more pronounced. Teams are able to build faster than they can deploy, and that imbalance introduces friction.
This is not a temporary phase. As development continues to speed up, deployment will remain the limiting factor unless the underlying structure changes.
A different approach is needed. Instead of treating infrastructure as a series of isolated setups, teams need systems that standardise how infrastructure is created, managed and reused.
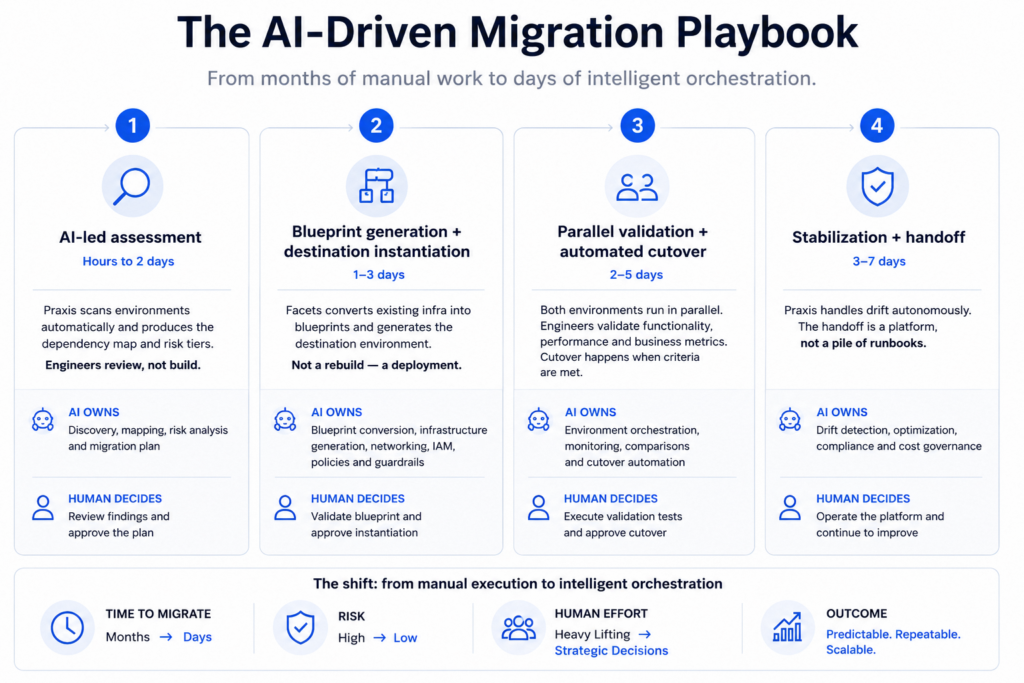
Facets turns infrastructure into a reusable deployment system
Facets is designed around this model. It brings infrastructure, CI/CD, environments, workflows and guardrails into a single operating system for deployment. It brings infrastructure, CI/CD, environments, workflows and guardrails into a single operating system for deployment. Teams can create environments on demand, follow predefined deployment workflows and retain operational context within the platform instead of relying on scattered documentation or individual knowledge.
This changes how teams interact with infrastructure. The focus shifts from repeatedly setting things up to using a system that is already structured to work.
Choosing the right cloud matters once infrastructure is standardised
Once infrastructure is structured as a system, the choice of where to run it becomes more important.
For AI workloads, teams need reliable compute, predictable cost structures and control over how environments are configured. OVHcloud provides a strong foundation for this, with access to GPU infrastructure, cost predictability, and flexibility in how environments are managed.
However, infrastructure alone does not remove friction. The real advantage comes when teams can move to that infrastructure quickly and operate it consistently without rebuilding their setup.
OVHcloud + Facets: Accelerating Deployment Through Standardisation
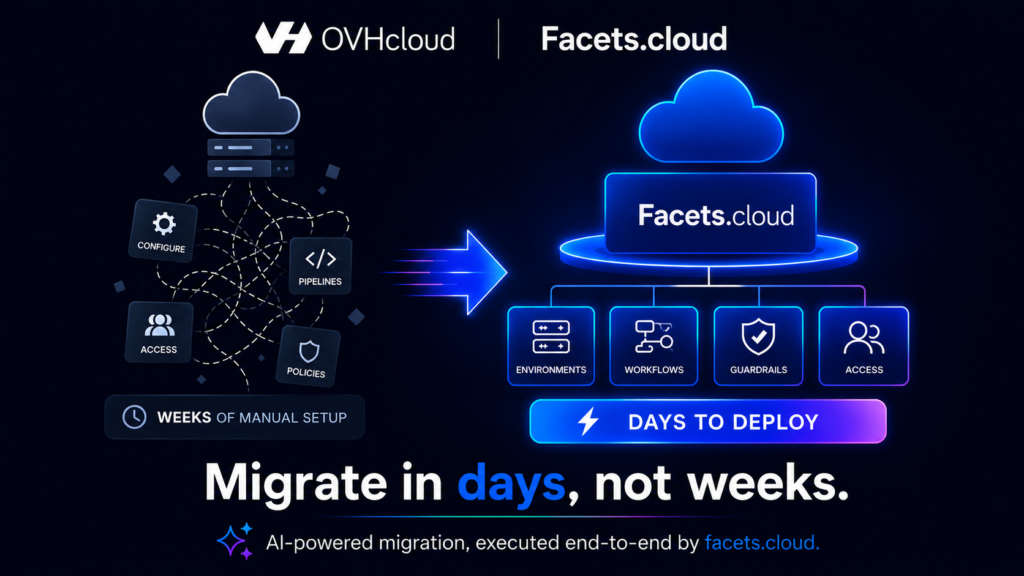
OVHcloud provides reliable, on-demand infrastructure for modern workloads. Facets helps teams make that infrastructure deployment-ready.
Together, they address both sides of the problem. OVHcloud provides the cloud foundation, while Facets defines how environments, workflows, policies and guardrails are created and operated on top of it.
Facets.cloud introduces reusable infrastructure blueprints that can be applied across projects. These blueprints define environments, workflows and operational guardrails in advance, allowing teams to deploy standardised systems instead of assembling infrastructure manually each time.
This shifts deployment from a configuration-heavy process to a repeatable, system-driven approach. Teams can reduce the time spent on setup, avoid recreating the same deployment patterns and move workloads onto OVHcloud with greater consistency.
The result is a faster path from migration planning to production-ready environments — helping teams migrate in days, not weeks.
AI speed is ultimately limited by how fast infrastructure can be deployed and operated
AI has already compressed the time it takes to build. The next bottleneck is AI deployment.
And that bottleneck is not solved by adding more tools or more people—it is solved by changing how infrastructure is structured. Because in practice, the speed of AI is defined not by how quickly models are built, but by how quickly they can be deployed and run.
Discover Facets.cloud