

Introduction
A few weeks ago, the release of the open-source large language model DeepSeek-R1 has taken the AI world by storm. The Chinese research team claimed their new reasoning model was on par with OpenAI’s flagship model o1, open-sourced the model and gave details about the work behind it.
In this blog post series, we will dive into the DeepSeek-R1 model family and see how you can run it on OVHcloud to build a simple chatbot that handles reasoning.
The “R” in DeepSeek-R1 stands for “Reasoning”, so let’s start by defining what a reasoning model is.
What are reasoning models?
Reasoning models are large language models (LLM) capable of reflecting on a problem before generating an answer. Traditionally, LLMs have been improved by spending more compute (more data, increase the number of parameters and the number of training iterations) at training time: it is training-time compute. Reasoning models, however, differ with standard LLMs in the way they use test-time compute, which means that during inference, they spend more time and resources to generate and refine a better answer.
Reasoning models excel at tasks that require understanding and working through a problem step-by-step, such as mathematics, riddles, puzzles, coding, planning tasks and agentic workflows. They may be counterproductive for use cases that don’t require reasoning capabilities, such as knowledge facts (for example, who discovered penicillin).
In a classroom, a reasoning model would be a student that takes time to understand the question, split the problem into manageable steps and detail the resolution process before rushing to write the answer.
Here is a comparison between the outputs of a standard LLM and a reasoning LLM, on an example prompt:
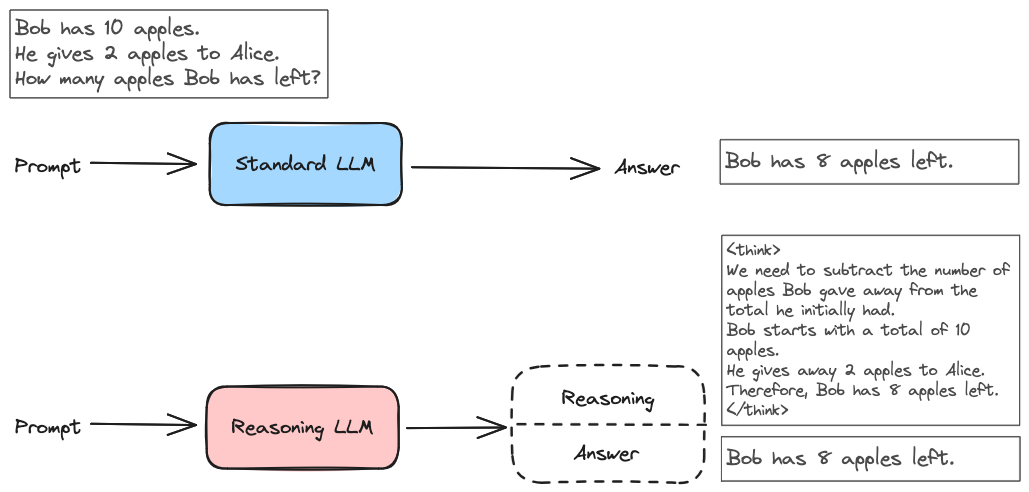
The reasoning model has generated more tokens, showing how it plans to solve the problem, before the actual answer. You can see it generates reasoning content into <think>...</think> tags, in the case of DeepSeek-R1.
A standard LLM can also show reasoning abilities, that are often more visible when using a technique called Chain-of-Thought prompting (CoT), by adding phrases such as “let’s think step-by-step” in the prompt.
However, a reasoning LLM has been trained to behave this way. Its reasoning skill is internalized, so it doesn’t require specific prompting techniques to trigger the chain of thoughts process.
It’s important to note that DeepSeek-R1 is not the first reasoning model; OpenAI led the way by releasing their o1 model in September 2024.
The two main reasons why DeepSeek-R1 made the headline are its open-source nature, and the paper released by the research team which give many details on how they trained the model, with valuable insight for the open-source community to create reasoning models. Especially, the key highlight of their paper is that they observe the reasoning behavior can emerge only through Reinforcement Learning (RL), without fine-tuning.
The DeepSeek-R1 model family
You may have heard about DeepSeek-R1 but it’s not the only model of the DeepSeek family: DeepSeek-V3, DeepSeek-R1-Zero, and distilled models, are also available. So what are the differences between those models?
First, let’s go through some definitions and an overview of how language models are trained.
Language model training overview
The large language models available in apps and playgrounds are usually trained in 3 steps:
- A base model is trained on an unsupervised language modeling task (for instance, next token prediction) with a dataset of trillions of tokens (also called pre-training),
- An instruct model is trained from the base model, by fine-tuning it on a massive dataset of instructions, conversations, questions and answers, to improve the performances of the model with the prompts frequently encountered in a chat,
- The final model is the instruct model trained to better handle human preferences, avoid the generation of harmful content, etc. with techniques such as RLHF (reinforcement learning from human feedback) and DPO (direct policy optimization).

DeepSeek-V3 training
According to the technical report provided by DeepSeek, DeepSeek-V3 is a mixture-of-experts (MoE) language model trained with the same kind of process, which is described in the image below:
- DeepSeek-V3-Base is trained with 14.8 trillion tokens,
- A dataset of 1.5 million instructions examples is used to fine-tune the base model,
- This instruct model goes through reinforcement learning with several reward models. The final model is DeepSeek-V3.

For the reinforcement learning step, DeepSeek uses their algorithm called GRPO (group relative policy optimization), which uses several reward models to assess the quality of the content generated by the model. The score given by each reward model is combined into a final score, used to update the model so that it maximizes its global score the next time.
DeepSeek-R1 model series training
DeepSeek-R1 models are built with a different training pipeline, using the base model of DeepSeek-V3. The diagram below shows the main steps of the process designed by DeepSeek to create several reasoning models mentioned in their technical report:
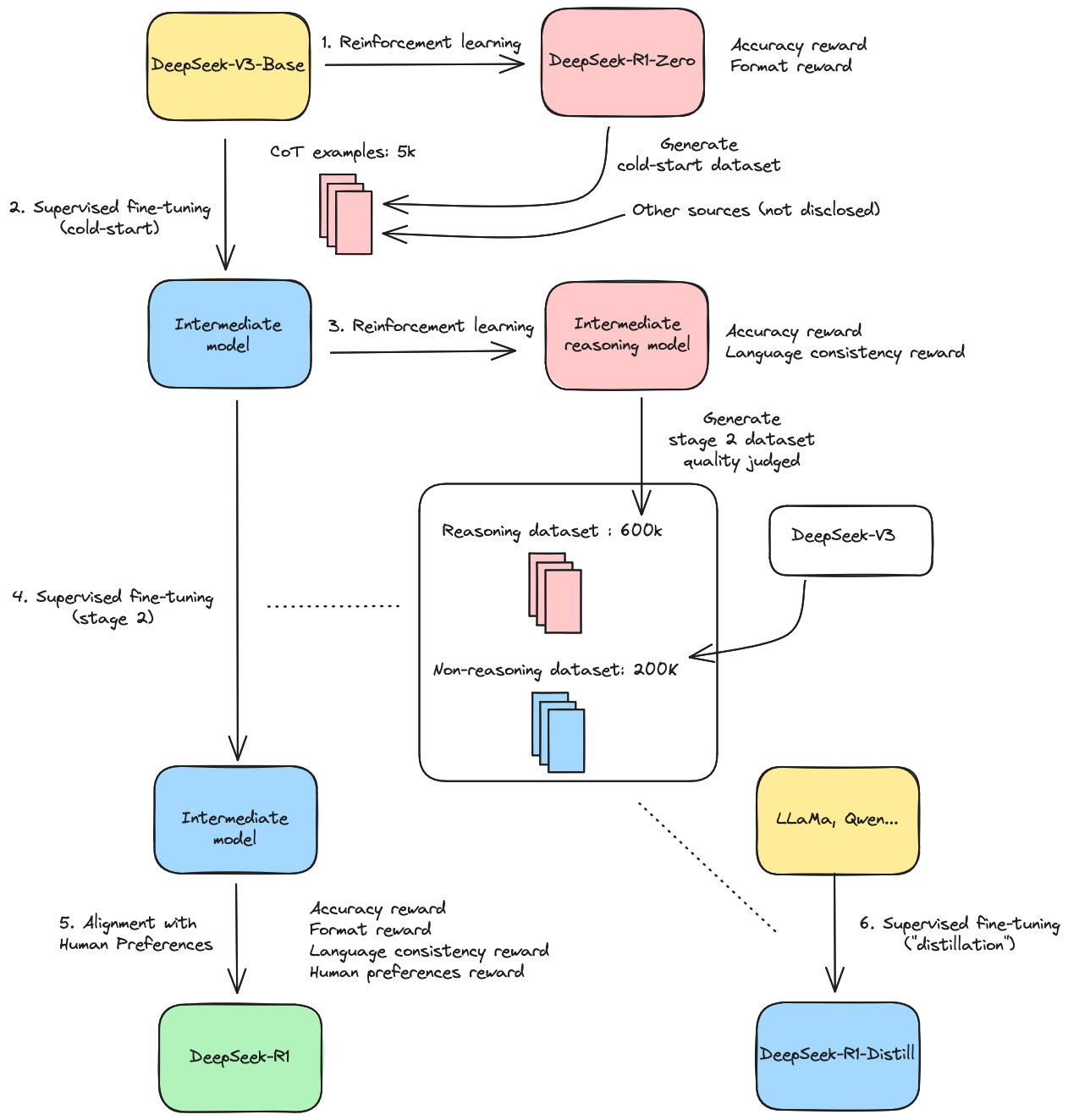
Let’s walk through it step-by-step (no pun intended):
1. The main breakthrough described in DeepSeek’s paper: they managed to train the DeepSeek-V3-Base 671B model to learn the reasoning capability with reinforcement learning only, which doesn’t require labeled data, as opposed to supervised fine-tuning. They use the same GRPO algorithm as before, with two rewards: one on the accuracy of the generated content, with “rule-based” experts instead of full reward models, that are also trained and require significant resources. For example, to assess if the model generated a correct Python code, you could have one expert that compiles the generated code and gives a note based on the number of errors. Another expert would generate test cases and see if the generated code can handle them. The other reward they use is about the format of the model’s responses, which must follow the <think>...<think> tags to enclose the reasoning content. The resulting model is DeepSeek-R1-Zero. However, it has limitations that make it unsuitable for direct use, such as language mixing and poor readability.
2. To overcome these limitations, DeepSeek uses DeepSeek-R1-Zero to create a cold-start reasoning dataset, augmented with other data from sources not explicitly mentioned. DeepSeek-V3-Base is trained with this cold-start data, before applying a new round of reinforcement learning.
3. They use the same RL approach to get a new reasoning model, that generates a better quality of output. Using this model, they build a 100x bigger reasoning data, growing from 5k to 600k samples, using DeepSeek-V3 as a quality judge. This dataset is then completed with 200k samples generated with DeepSeek-V3 on non-reasoning tasks.
4. A second stage of supervised fine-tuning is done with the dataset built earlier.
5. The model is then aligned with human preferences with a final round of reinforcement learning with a specific human preferences reward. The resulting model is DeepSeek-R1.
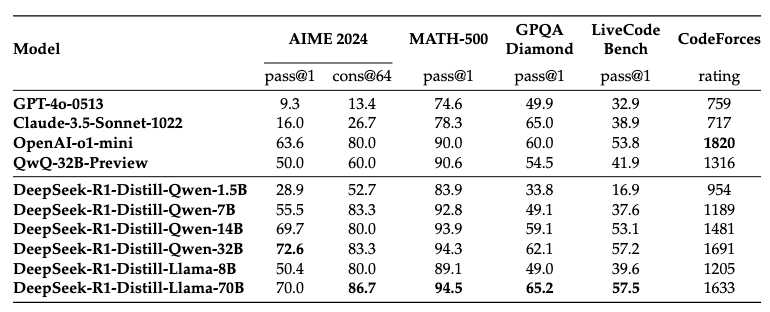
6. Finally, DeepSeek experimented with fine-tuning much smaller models than DeepSeek-V3 (LLaMa 3.3 70B, Qwen 2.5 32B…) with the dataset built at step 3. In the paper, they call this process distillation. However, it must not be mistaken with the knowledge distillation technique frequently used in deep learning, where a student model learns from the probabilities distribution of a teacher model. Here, the term “distillation” refers to the fact that the reasoning skill is “distilled” into the base model, but it’s plain old supervised fine-tuning. This is how the DeepSeek-R1-Distill model series is trained. The quality of the dataset enables the resulting distilled models to beat much larger models on reasoning tasks, as show in the benchmark below:
Recap
The table below summarize the differences between the model of the DeepSeek-R1 series:
| Model | Description |
| DeepSeek-R1-Zero | Intermediate 671B reasoning model trained from DeepSeek-V3 exclusively with reinforcement learning, and used to bootstrap DeepSeek-R1 training. |
| DeepSeek-R1 | 671B reasoning model trained from DeepSeek-V3. |
| DeepSeek-R1-Distill | Smaller models fine-tuned for reasoning with a dataset generated by an intermediate version of DeepSeek-R1. |
Run DeepSeek-R1 on OVHcloud
Now that we’ve seen the differences between all DeepSeek models, let’s try to use them!
AI Endpoints
The fastest way to test DeepSeek-R1 is to use OVHcloud AI Endpoints.
DeepSeek-R1-Distill-Llama-70B is already available, ready to use and optimized for inference speed. Check it out here: https://endpoints.ai.cloud.ovh.net/models/a011515c-0042-41b2-9a00-ec8b5d34462d
AI Endpoints makes it easy to integrate AI into your applications with a simple API call, without the need for deep AI expertise or infrastructure management. And while it’s in beta, it’s free!
Here is an example cURL command to use DeepSeek-R1 Distill Llama 70B on the OpenAI compatible endpoint provided by OVHcloud AI Endpoints:
curl -X 'POST' \
'https://deepseek-r1-distill-llama-70b.endpoints.kepler.ai.cloud.ovh.net/api/openai_compat/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"max_tokens": 4096,
"messages": [
{
"content": "How can I calculate an approximation of Pi in Python?",
"role": "user"
}
],
"model": null,
"seed": null,
"stream": false,
"temperature": 0.7,
"top_p": 1
}'We can see in the output the thinking process followed by the answer, which have been truncated for clarity.
{
"id": "chatcmpl-8c21b2e3fac44d43b63c06fa25e58091",
"object": "chat.completion",
"created": 1741199564,
"model": "DeepSeek-R1-Distill-Llama-70B",
"choices":
[
{
"index": 0,
"message":
{
"role": "assistant",
"content": "<think>\nOkay, the user is asking how to approximate Pi using Python. I need to think about different methods they can use. Let's see, there are a few common approaches. \n\nFirst, there's the Monte Carlo method. ... Let me structure the response with each method as a separate section, explaining what it is, how it works, and providing the code. Then, the user can pick which one they prefer based on their situation.\n</think>\n\nThere are several ways to approximate the value of Pi (π) using Python. Below are a few methods:\n\n### 1. Using the Monte Carlo Method..."
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage":
{
"prompt_tokens": 14,
"completion_tokens": 1377,
"total_tokens": 1391
}
}Stéphane Philippart, Developer Relation Advocate at OVHcloud, has written a blog post covering everything you need to know to get up to speed with AI Endpoints and run this model: Release of DeepSeek-R1 on OVHcloud AI Endpoints
AI Deploy
What if you want to run another version of DeepSeek-R1, such as the Qwen 7B distilled version?
You can use another OVHcloud AI product, AI Deploy, to create your own serving endpoint, with vLLM as the inference engine. It is open-source, fast and well maintained, ensuring maximal compatibility with even the most recent AI models.
Eléa Petton, Solution Architect at OVHcloud, has written a blog post explaining in details how to serve an open-source model with vLLM on AI Deploy. Just replace the Mistral Small model with the DeepSeek distilled version you want to use (e.g. deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) and adapt the number of L40S cards needed (1 is enough for the 7B version) : Mistral Small 24B served with vLLM and AI Deploy – a single command to deploy an LLM (Part 1)
Next up, creating a reasoning chatbot with DeepSeek-R1
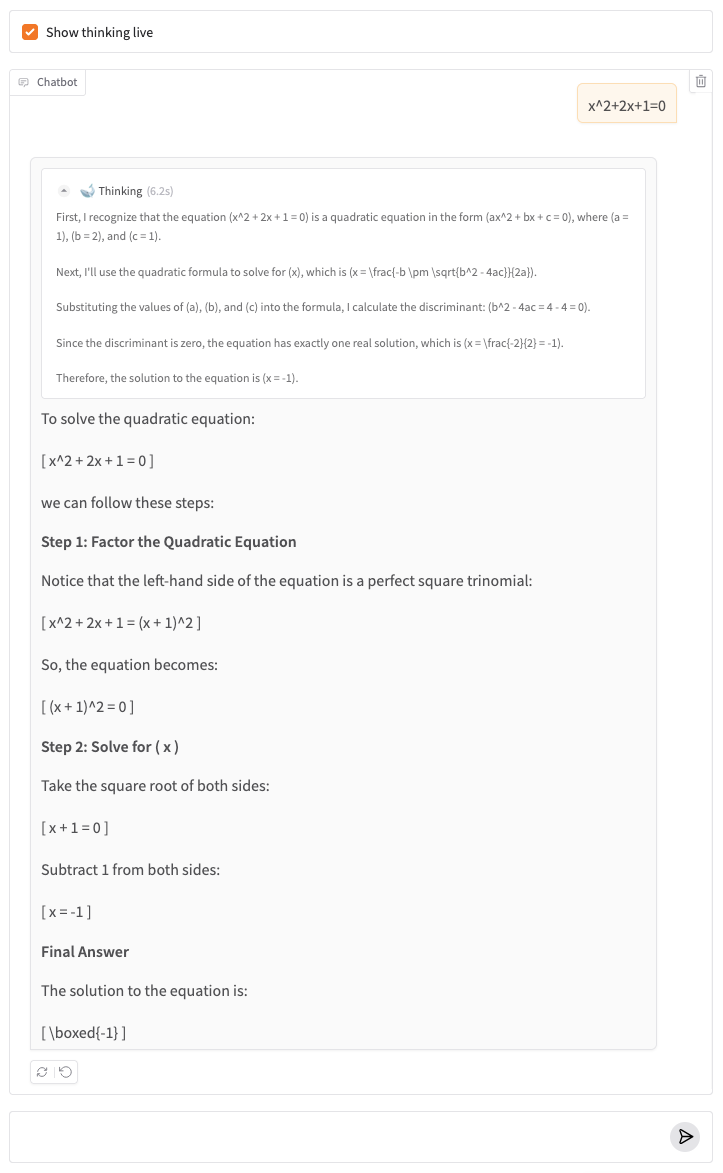
In part 2 of this blog post series, we will use a DeepSeek-R1-Distill model to create a chatbot that will handle reasoning gracefully, by showing the thinking process of the model.
We will develop our chatbot with OVHcloud AI Endpoints and the Python library Gradio, that enables to quickly create simple chat interfaces.
Here a screenshot of the finalized chatbot we will build:
Stay tuned for the next article in this DeepSeek-R1 series. In the meantime, try out DeepSeek-R1 on AI Endpoints and AI Deploy and let us know what you <think>!
Resources
If you want to learn more about DeepSeek-R1 and the topics we covered in this blog post, such as test-time compute, GRPO, reinforcement learning and reasoning models, we suggest having a look at these resources:
- DeepSeek-R1 technical report, by the DeepSeek team
- The Illustrated DeepSeek-R1, by Jay Alamar
- Understanding Reasoning LLMs, by Sebastian Raschka
- A Visual Guide to Reasoning LLMs, by Maarten Grootendorst

Machine Learning Engineer working on AI Endpoints with a focus on new model support and inference optimization