
Two years after launching our Managed Kubernetes service, we’re seeing a lot of diversity in the workloads that run in production. We have been challenged by some customers looking for GPU acceleration, and have teamed up with our partner NVIDIA to deliver high performance GPUs on Kubernetes. We’ve done it in a way that combines simplicity, day-2-maintainability and total flexibility. The solution is now available in all OVHcloud regions where we offer Kubernetes and GPUs.

The challenge behind a fully managed service
Readers unfamiliar with our orchestration service and/or GPUs may be surprised that we did not yet offer this integration in general availability. This lies in the fact that our team is focused on providing a totally managed experience, including patching the OS (Operating System) and Kubelet of each Node each time it is required. To achieve this goal, we have built and maintained a single hardened image for the dozens of flavors, in each of the 10+ regions.
Based on the experience of selected beta users, we found that this approach doesn’t always work for use cases that require a very specific NVIDIA driver configuration. Working with our technical partners at NVIDIA, we found a solution to leverage GPUs is a simple way that allows fine tuning such as the CUDA configuration for example.
NVIDIA to the rescue
This Keep-It-Simple-Stupid (KISS) solution relies on the great work of NVIDIA building and maintaining an official NVIDIA GPU operator. The Apache 2.0 licensed software uses the operator framework within Kubernetes. It does this to automate the management of all NVIDIA software components needed to use GPUs, such as NVIDIA drivers, Kubernetes device plugin for GPUs, and others.
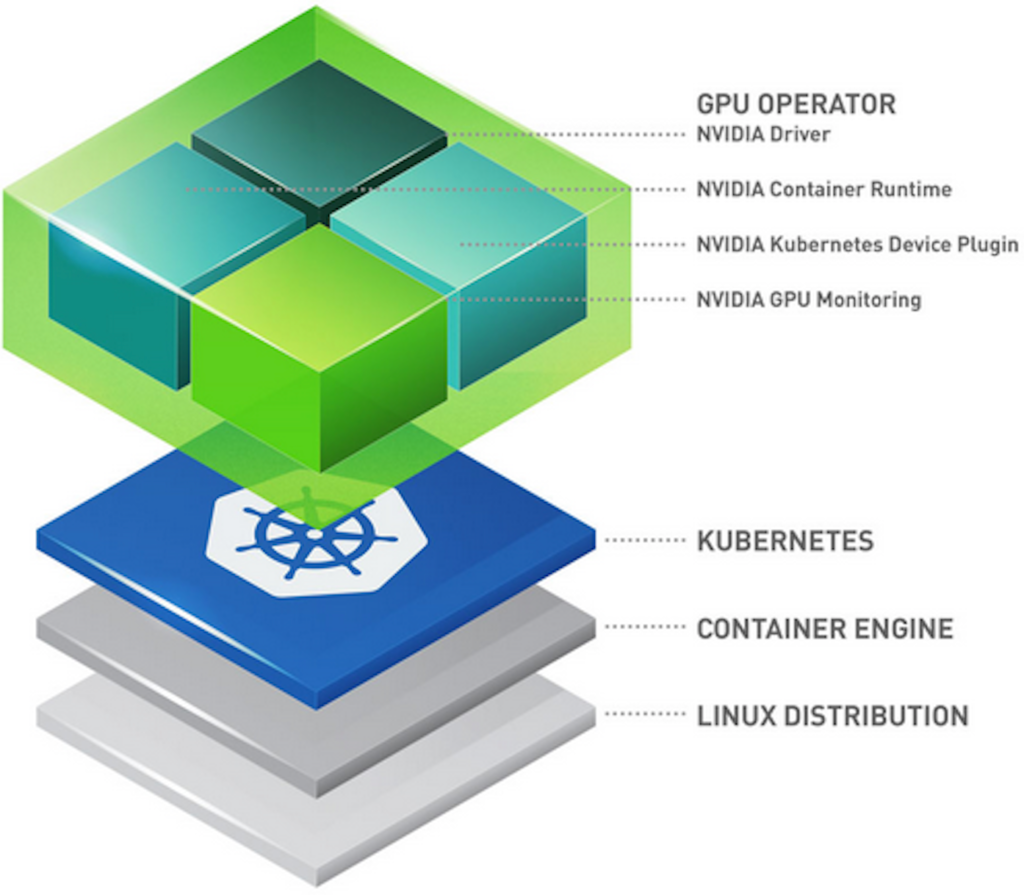
We ensured it was compliant with our fully maintained Operating System (OS), based on a recent Ubuntu LTS version. After testing it, we documented how to use it on our Managed Kubernetes Service. We appreciate that this solution leverages an open source software that you can use on any compatible NVIDIA hardware. This allows you to guarantee consistent behavior in hybrid or multicloud scenarios, aligned with our SMART motto.
Here is an illustration describing the shared responsibility model of the stack:
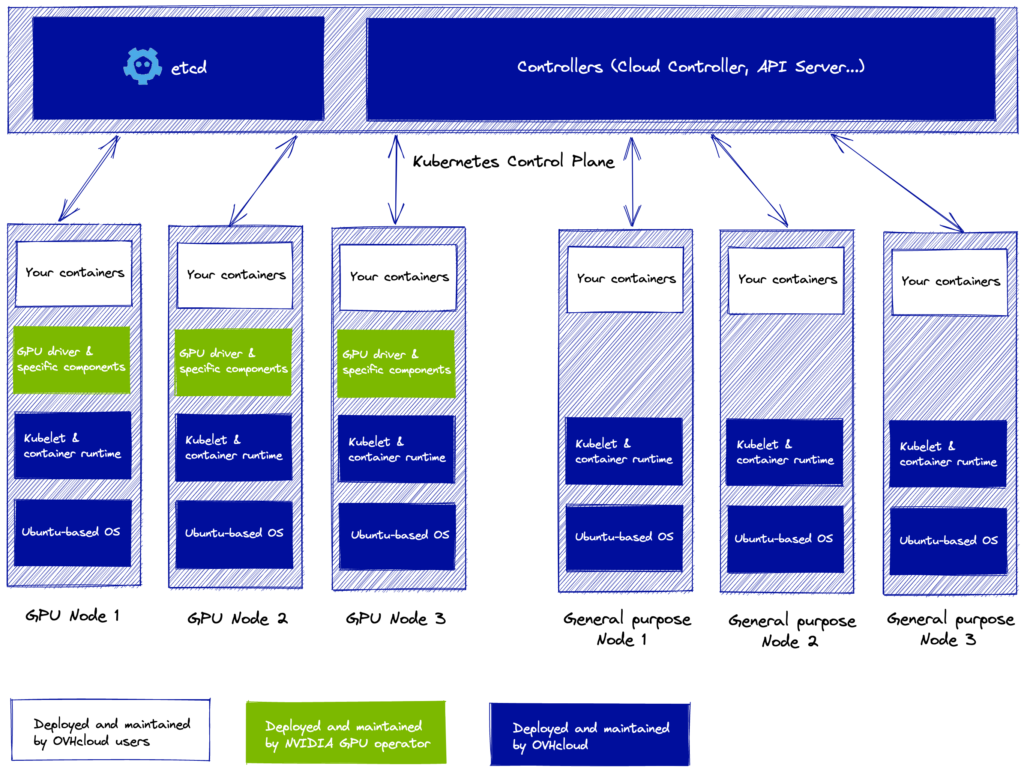
All our OVHcloud Public customers can now leverage the feature, adding a GPU node pool to any of their existing or new clusters. This can be done in the regions where both Kubernetes and T1 or T2 instances are available: GRA5, GRA7 and GRA9 (France), DE1 (Germany) (available in the upcoming weeks) and BHS5 (Canada) at the date this blog post is published.
Note that GPUs worker nodes are compatible with all features released, including vRack technology and cluster autoscaling for example.
Having Kubernetes clusters with GPU options means deploying typical AI/ML applications, such as Kubeflow, MLFlow, JupyterHub, NVIDIA NGC is easy and flexible. Do not hesitate to discuss this feature with other Kubernetes users on our Gitter Channel. You may also have a look to our fully managed AI Notebook or AI training services for even simpler out-of-the box experience and per-minute pricing!
Cloud Native Services Product Manager