
Guest blog by Wim Kerkhoff, Founder and CEO of Kerkhoff Technologies Inc and Crafty Penguins

Regardless of where your Windows or Linux servers are located, how confident are you that in the event of a major disaster, that your business can continue as usual?
While there are many awesome SaaS cloud solutions that don’t require any servers, the reality is that many companies (of all sizes and types) require their “own” server. It might be in the office, in co-located servers they own, or with a VPS or dedicated server with a provider like OVHcloud. There are many reasons, from personal preference to compliance to security to cost and compatibility.
Read on to learn how custom requirements require creative solutions for Disaster Recovery (DR), and how to build confidence that your IT infrastructure can withstand major failures.

Case Study – RetailCo and Software Co
This article is based on our with two clients that had somewhat similar requirements, so we could reuse the designs our engineers created. Both have a mix of Windows and Linux servers.
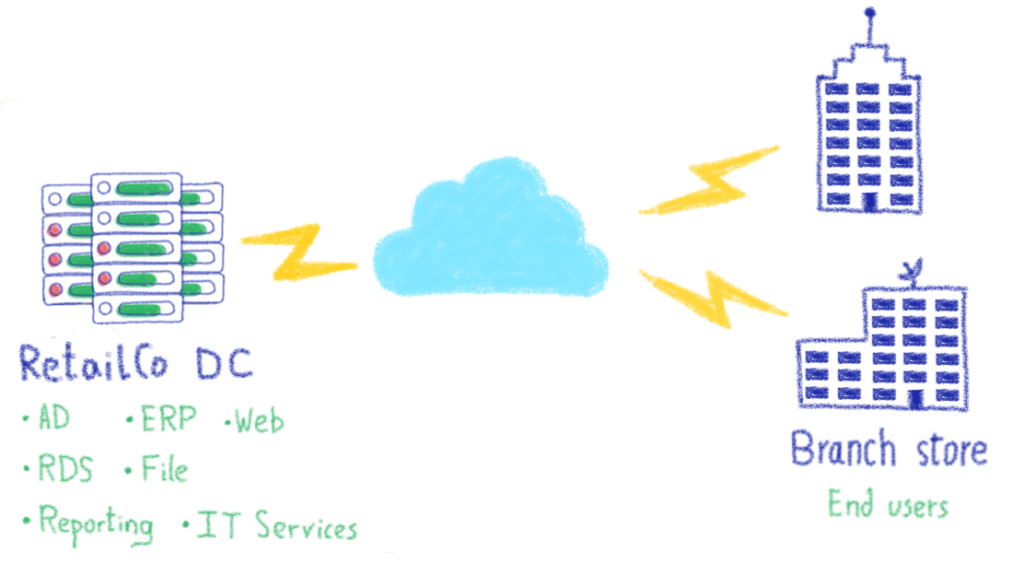
Client #1 we’ll call RetailCo. They have over 12 retail “bricks and mortar” locations in Western Canada, with a growing online e-commerce capability. The core application runs on Windows servers with Microsoft SQL Server and Remote Desktop Services (RDS) clusters.
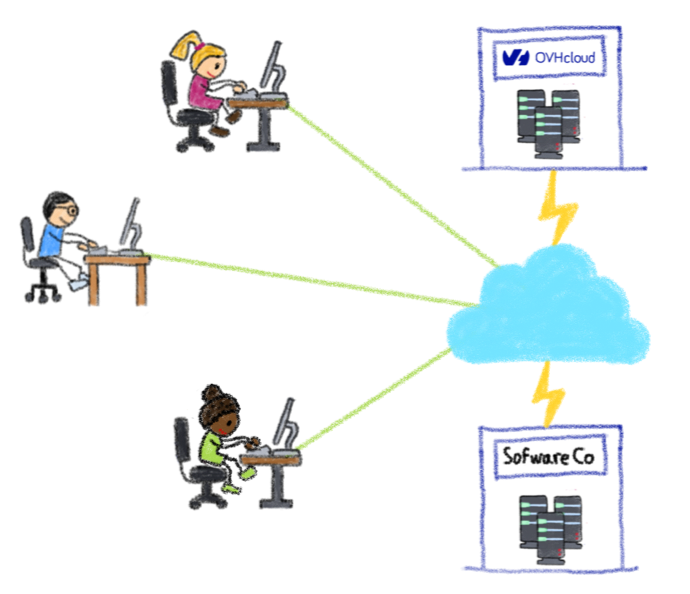
Client #2 we’ll call SoftwareCo. They have a large office in the Vancouver area with over 100 employees, many of who are software developers and creative artists in the mobile app industry. In the event of the failure of their office or downtown Vancouver hosted server, they wanted the confidence that business operations could continue with perhaps several hours of IT work to flip over to the OVHcloud servers in Quebec-Canada.
Backup and Recovery isn’t enough
Basic backup has been around for many decades. Traditionally, the storage method was via magnetic tape drives connected directly to each server. This transitioned to hard drives as capacity increased, prices dropped, and they become more portable with easy USB connections. And as high-speed internet became more common, then online cloud backups arrived.
From the new clients we talk to, pretty much everyone has backups. However, there are often major issues: the backups are often not automatic or tested. Somebody might be taking a tape drive or removable USB drive home every day or week in their purse, but it’s empty because the backup job failed and nobody watches it. Or, the drive may have corrupted.
It’s also very common that while the backup job may be monitored and validated as recoverable, that the recovery is very time consuming. It may require hardware to be available that is 100% identical to the original failed hardware. Or it may require a time consuming data or physical shipment of storage media to the recovery location. Having recoverable data and actually restoring operations is two very different things: with some backup methods, it could take a week to restore business! Even if the backup jobs have been reliably running every single hour.
With RetailCo’s previous managed hosting provider, backups were technically in place. However, it was a file/folder backup method only, and backups were only stored within the hosting provider’s facility. That meant that if a server failed, a technician would have to create a new virtual machine, install Windows, join to the Active Directory domain, install all the required software, manually configure everything, and only then restore the files to the new server. That process could take several days depending on the role and complexity of the failed server!
Image-based backups have existed for over 10 years now; these are very helpful but still do not guarantee a quick recovery. If the original hardware has failed for whatever reason, it can take weeks to procure a suitable replacement. It depends a lot on on the type of failure.
Replicating data to long-term “cold” or “cool” storage in Amazon or Azure can be very cheap and easy to do. However, getting the data back out and up and operational can be very time and labour-intensive. Clearly, creative solutions are required.
Every year brings new failure situations to account for
When it comes to IT and the ways that systems can fail, every year is a new opportunity for new types of failures. We have the classic threats of hardware failure, power outages, and earthquakes. Over the last couple of years, even here in Western Canada we’ve seen new situations:
- 100-year floods, trashing highways and transportation routes – I couldn’t leave my town
- Covid-19 and Remote work changing how systems are accessed
- Increased ransomware demands (over $1M) and cyber insurance requirements.
- Intelligent intrusions – hackers actively deleting backups
- Record heatwaves causing air conditioners to fail
- Human error, due to increasing IT complexity
- New regulations and compliance requirements in various industries
My conclusion is that we all need to be prepared for a variety of situations.
Moving past Archaic Backups and Disaster Recovery to Business Continuity
Clearly, just having recoverable backups is not enough. We need to move the conversation past backups and Disaster Recovery to Business Continuity. In other words, what does the business require at a minimum to continue operations? How important are the data, applications, and digital communications? Is it acceptable for them to be completely unavailable for a week while they are being recovered? What is the true cost of downtime, considering not only expenses but lost revenue, reputation impact and damaged customer confidence?
In the case of RetailCo, they indicated that “continuation of business” means that stores are open and transacting. Perhaps not in a beautiful ideal scenario, but open for business and able to take payment. As their primary servers are in Vancouver, we configured a warm standby of their database and web portals in OVHcloud. In a failure of the primary servers in Vancouver, cashiers would be able to sell goods to clients using the web version of the point of sale software, even though the Remote Desktop Services (RDS) cluster was offline. The full restore of the environment would take a significant amount of time, however the core function of the business (store fronts and warehouse) would continue to operate while restoration took place.
For SoftwareCo, they didn’t have any significant software running on their Windows servers; primarily they were used for Active Directory authentication and internal DNS only. These servers are mission critical for remote VPN access and authentication. So, we setup active AD and DNS replicas in the OVHcloud, and replicated image-based snapshots of all servers and data to OVHcloud. This allowed for instant failover of the essential AD/DNS servers, with quick recovery of file data should that be required. All data was kept in the “private Cloud” – servers under the clients control. This fulfilled their requirement for georedundancy and client managed storage.
These custom solutions provided all components:
- Fast recovery by using real-time data replication to servers located 4000 km away. The advantage is that it doesn’t matter how often we’re backing up or how long it takes to recover.
- Frequent incremental data backups to multiple locations (onsite and offsite)
- Image-based drive backup technology for ease of restoration
- CyberSecurity data protection through encryption and different chains of command and control
The following diagram provides an illustration of the overall design for the RetailCo business continuity design.

Our checklist for high confidence server backups
- Executive written approval on backup frequency and recovery time objectives. For each service and server:
- Agree on how often backups need to be created. This is called the Recovery Point Objective (RPO). Example: your website may not change often, so a monthly backup is sufficient.
- Agree on the maximum time it must take to recover. This is called the Recovery Time Objective (RTO). Example: The website doesn’t change often, but it’s critical for sales and marketing so must be restored to service within 2 hours.
- Agree on retention policies. This may impact storage costs. Example: for the website, we only need to keep a backup as old as 3 months ago. Example: for the accounting database, we need to be able to recover data from 1 year ago.
- Design and implement a backup system that actually fulfills the approved RTO and RPO strategy.
- On a regular basis, test the backups to confirm they are recoverable in the agreed-upon objectives.
- On a regular basis, audit all IT systems (including Shadow IT services) for new data that may not be sufficient backed up.
- Have multiple local backups, for the quickest recovery.
- All backups run automatically, with health monitoring and alerting on failures.
- Security controls are in place, so that ransomware, malware, viruses, and hands-on attackers can’t delete either local or remote backups.
- Encryption is in place for backup data at rest (onsite and offsite) and in transit (whether USB drive or Internet upload).
Why OVHcloud is great to work with?
- Costs: Dedicated hardware is more under the client’s control and there is additional cost for testing or production use. It’s a happy medium between the cost savings of CapEx vs Lease vs Pay-as-you-go. For clients who need multiple virtual servers with lots of CPU and RAM, OVHcloud generally provides more bang for the buck then AWS or Azure.
- Ease: The addition of new hardware is a few clicks in the ordering page, unlike with client owned datacenters equipment where it can take months to order and install new hardware. The OVHcloud portals and dashboards are also much easier to navigate then AWS and Azure, which can get quite complicated.
- Real hardware: with direct access to the hardware, the only limit to the number of virtual machines is the amount of RAM and CPU in that OVHcloud dedicated server.
- Data Sovereignty: OVHcloud is a Non-US Cloud service provider and the Data Centers are in Quebec & Europe.
- Predictable pricing : OVHcloud provides cloud services with simple billing and no hidden costs. No Ingress-egress Fees for customers wanting to move data around.
Our approach – vendor-neutral
Our approach is not a pure-cloud one; we prefer being more pragmatic about it. We’re happy to design Multicloud solutions but if possible it’s great to stay vendor neutral. Being locked into one ecosystem can be problematic for some companies. Thus, we have maintained the people, skills, tools, and process to support a variety of platforms and configurations.
Crafty Penguins – Linux Managed IT services
Our Crafty Penguins division specializes in Linux consulting and server management. Check out the technology stack and service pricing pages to learn more. Many clients start with a Discovery Project for an assessment and health check of their current servers.
Kerkhoff Technologies – Managed IT Services & IT Consulting
Our Kerkhoff Technologies division provides Managed IT Services for clients using Windows & Linux systems. Check out our service and technology stack pages to learn more. Need an assessment, security review, migration or new server setup? Reach out and schedule an introductory call.

