
In our Domain names 101 series, we explained that one ICANN‘s missions is regulating and providing norms for gTLDs domain names (.com, .net, .info …). One of these norms is the Registrar Data Escrow program, also known as RDE.
To put it simply, registrars have to regularly gather and export some data to a third-party company. Since the creation of this program, we have used a solution which has worked very well for many years, but has started to face limitations due to the increasing amount of domain name registrations. Indeed, generating one of these weekly exports lasted 4 days! It was time to design a long-term and scalable solution.

Let’s see together how we went from 4 days of report generation to 15 minutes, a drastic performance improvement of about +38 000%.
What is the Registrar Data Escrow program ?
As we are an ICANN accredited registrar, we have to send regularly a copy of our gTLD domain names data to an escrow agent, a neutral third party. This is a protection mechanism in case of registrar failure, accreditation termination, or accreditation relapse without renewal. So the data associated with registered domain names is never at risk of being lost or inaccessible.
In concrete terms, for all gTLD domain names that we manage for our customers, we send encrypted files containing:
- The domain name
- The names of the primary and secondary name servers
- The expiration date of the domain name
- Identity information of the domain name contact and nichandles, which are the registrant, the technical contact, the administrative contact and the billing contact (person or corporation name, postal address, e-mail address and phone/fax number)
Authorized escrow agents are listed on the ICANN website. We chose Denic Escrow Services, a European actor, to ensure our compliance with GDPR.
Registrars with at least 400,000 registrations per year are required to deposit a full export once a week, and an incremental the remaining days. For the others, a weekly full export is sufficient. You can find all technical details in the Registrar Data Escrow Specifications.
Basically a report is composed of two types of encrypted files: Domains & Handles (Contacts).
# Domain CSV file domain,nameserver-1,nameserver-2,expiration-date,registrant-contact,technical-contact,admin-contact,billing-contact ovhcloud.com,dns.ovh.net,ns.ovh.net,2049-08-01T00:00:00+00:00,EU_contact/123456,EU_xx12345-ovh,EU_xx12345-ovh,EU_xx12345-ovh # Handle CSV file handle,name,address-street1,address-street2,address-street3,address-city,address-state,address-postcode,country-name,email,phone,fax EU_contact/123456,OVH SAS (Klaba Miroslaw),2 Rue Kellermann,"","",ROUBAIX,"",59100,FR,ovhcloud@fake-email.com,+33.123456789,"" EU_xx12345-ovh,OVH SAS (Klaba Miroslaw),2 Rue Kellermann,"","",ROUBAIX,"",59100,FR,ovhcloud@fake-email.com,+33.123456789,""
Why 4 days of generation ?
Domain names have been for sale on OVHcloud since 2000. This ICANN program is mandatory in the Registrar Accreditation Agreement since 1999, and the last official Registrar Data Escrow Specification document has been published in 2009. This is an old requirement that has been implemented in the early days when our Information System was a full monolith with a few domain names in our databases.
At this time, the report generation had been written using a single Perl script doing simple database requests. Over the years, due to the increase of volume and traffic, new teams, new databases, new subsidiaries and new architectures have been created. Data responsibility was divided into different teams like Domain, DNS and Nichandle/Contact. The internal functioning of the report generation did not change though. Without fundamental refactoring, the time needed to generate the report inherently increased over the years.
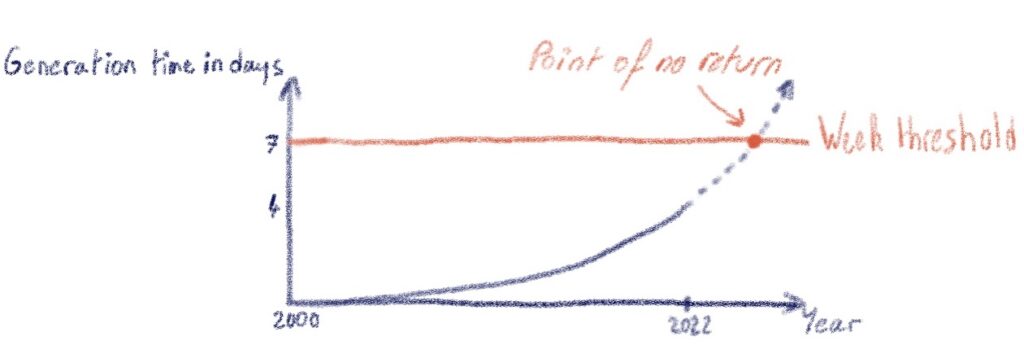
It was no big deal while it was working well and ultimately did not last more than 7 days, so that weekly exports did not overlap.
But, in the last 2 years, we went from 2,5 days to 4 days. In this situation, if it fails the last day for any reason, we would be unable to generate and send a new one within the week threshold. In the interim, we also have reached a point where we manage about 5 million of domain names, and we intend to keep growing. We had to anticipate and find a long-term and scalable solution, capable of handling 10 times our current domain name amount.
The internal Data Lake
In the meantime, over the years, OVHcloud built an internal Data Lake, a centralized place where internal production data is replicated. It’s meant to be a reliable, secured and efficient platform for storing Big Data.
Then, after agreements with our internal data governance team, authorized teams from all OVHcloud may use this data for data science. For example, aggregation tables can be used by business teams to make decisions or produce legal documents.
OVHcloud current Data Lake is based on Hortworks HDP. On top of this Data Lake, Big Data tools, like Spark, are configured for high performance. Every day, the Big Data tools compute all businesses data to obtain smart and practical aggregation tables.
In this context, as Domain team, we had the perfect replacement platform. Our Data Lake colleagues provide this efficient platform and a set of ready-to-use tools that we can use as a service to solve this Registrar Data Escrow program problematic.

The solution replacement
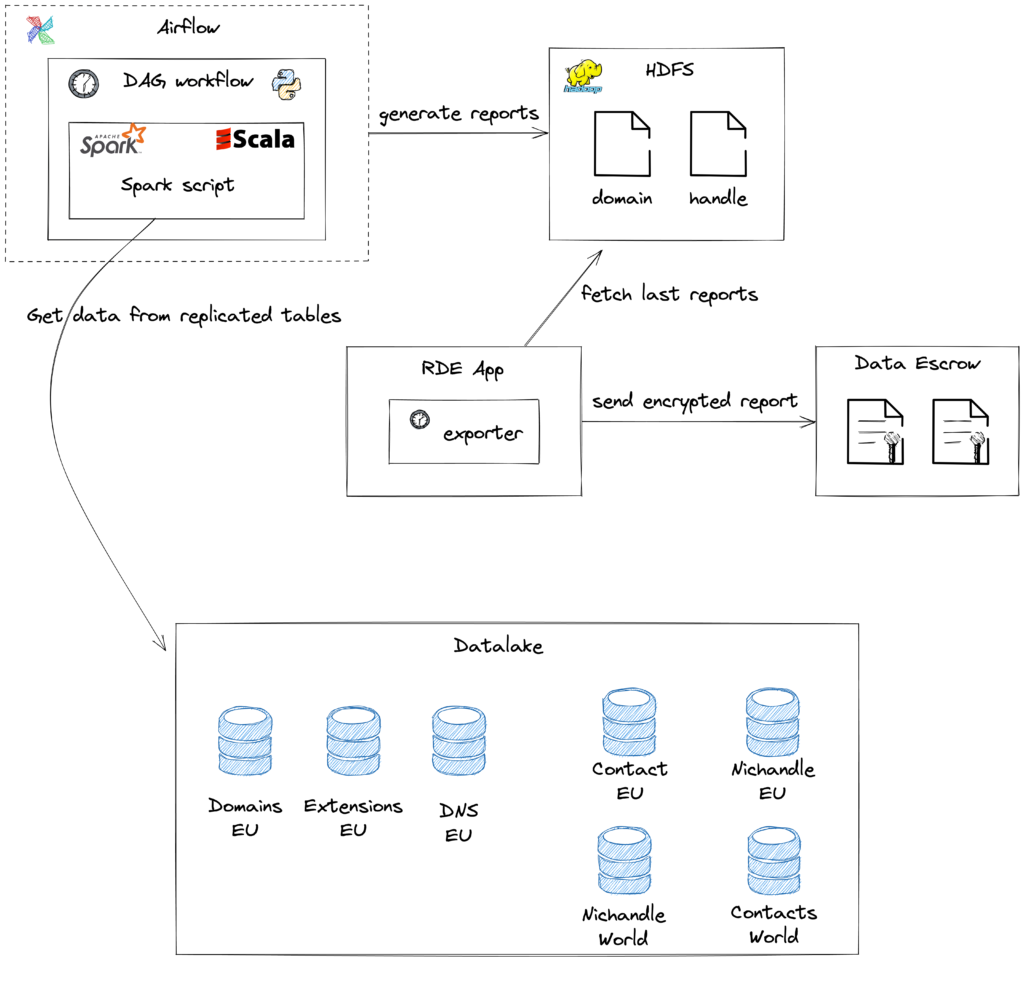
As previously said, the data which is required for the report comes from multiple teams and multi-region databases. As replications are centralized in the Data Lake, we have a single source that we can request, join and normalize easily. Moreover, as we don’t request the real time production databases anymore, we reduce impact on production performance.
The Data Lake team provides an Apache Airflow platform where we can schedule Apache Spark scripts through Directed Acyclic Graph workflows. Let’s see that, bit by bit:
- The Apache Spark script is the piece of code that will run in the Spark server, making all the joining and normalization of input data. Execution is massively distributed on Hadoop YARN, so that data is computed and fetched in parallel, assuring a short and constant execution time in the end. This is the central piece of the performance improvement.
- The script execution is included in a Directed Acyclic Graph workflow, besides other steps like concatenation of result files, working directory removal or uploading final report to Hadoop Distributed File System.
- Apache Airflow runs the DAG at the related schedule. It also provides an administration UI, in order to manually run the jobs, display logs and so on.
Finally, the concatenated report is fetched from HDFS, syntactically and semantically validated, encrypted and sent to our Escrow Agent.
Conclusion
We can clearly see the improvement of performance on the full report generation in the following table.
| Before | After | |
| Generation | 5600 minutes | 13 minutes |
|---|---|---|
| Validation & Encryption | 1 minute | 1 minute |
| Upload | 15 seconds | 15 seconds |
| TOTAL | ≈4 days | ≈15 minutes |
Even though it was pure 20 years legacy, the report generation has been working seamlessly for many years and did the job without us noticing. This is important to say, we should keep normalizing the wait for the right moment to refactor something working, even though it’s bad looking code.
Due to increasingly bad performances, now was the time to change the paradigm and find the right long-term and efficient solution. We chose to go with Big Data technologies to build something ready to face the future. As it’s distributed, report generation should take a constant execution time even with a volume increase. This solution should work seamlessly, in turn, for many years.
On the technological side, we can also tell that Spark works really great. By the way, if you did not know, OVHcloud provides a ready-to-use Data Processing platform which uses Spark clusters.
Finally, as you can see, this article is an overview of what we built together with OVHcloud Data Lake team. But, we did not talk about the Data Lake technologies in details. For more in-depth technical content about Spark, take a look at “How to run massive data operations faster then ever, powered by Apache Spark and OVHcloud Analytics Data Compute” and “Improving the quality of data with Apache Spark” articles 🙂

Domain Names Squad