
Chaque jour, OVH détecte et mitige plus de 1 500 attaques dirigées contre les serveurs de ses clients. Un tiers environ de ces attaques sont des « SYN flood ». Cette technique particulière, visant à atteindre un déni de service (DoS), utilise les caractéristiques du protocole TCP… lequel représente plus de 90 % du trafic reçu par OVH et constitue une des fondations du réseau Internet. C’est en effet ce protocole de contrôle de transmissions qui est utilisé pour transmettre les e-mails, les pages web, etc. Les parades à ce type d’attaques ne sont pas nouvelles. En revanche, leur implémentation par OVH, qui a développé une solution basée sur un FGPA et un patch du noyau Linux est plus originale. C’est cette implémentation que nous avons souhaité détailler dans cet article, en décortiquant auparavant le fonctionnement d’une attaque SYN flood.
SYN flood : une attaque bien connue
Ce type d’attaque a émergé dans les années 90. Aujourd’hui, on voit régulièrement des attaques de ce type atteindre 60 millions de paquets par secondes, soit un peu moins de 40 Gbps. Si 40 Gbps semble modeste en comparaison de l’attaque de 1 Tbps que nous avons filtrée en septembre, c’est un piège. La métrique importante dans ce type d’attaques n’est pas le débit, mais le nombre de paquets à traiter. Au cours d’une bataille dans le Seigneur des Anneaux, ce n’est pas la taille des Orques qui compte : c’est leur nombre. Chaque Orque doit être filtré. Dans une attaque informatique, le principe est similaire : chaque paquet doit être inspecté et filtré individuellement.
Le SYN flood étant une technique assez ancienne à l’échelle de l’histoire de l’informatique, les techniques de mitigation sont bien connues et maîtrisées. La plus célèbre et la plus efficace d’entre elles est basée sur des « SYN-cookies ». Elle a été proposée pour la première fois en 1996 par Daniel J. Bernstein, un spécialiste de la cryptographie, plus connu pour son implication dans les nouveaux standards de sécurité. Dans le cadre de la nouvelle offre d’IP Load Balancing d’OVH, nous avons implémenté cette technique de mitigation sur un FPGA, couplé avec un noyau Linux spécialement adapté pour prendre la suite lors du ACK final si celui-ci est légitime. Mais avant de détailler cela, revenons sur ce qu’est une connexion TCP.
Anatomie d’une connexion TCP
Le protocole TCP est un protocole de flux qui fonctionne en mode connecté. Tout est dit 🙂
Plus concrètement, dire que le protocole TCP est un protocole de flux implique que les paquets TCP seront livrés au destinataire dans le même ordre qu’ils ont été envoyés par l’émetteur. Comme le réseau peut réordonner ou perdre des paquets, le destinataire se base sur un numéro de séquence pour remettre les paquets dans l’ordre et confirmer à l’émetteur la bonne réception des paquets. Et pour éviter que n’importe quel client malicieux puisse injecter des paquets dans un flux TCP arbitraire, l’émetteur et le récepteur se mettent d’accord sur leurs numéros de séquence initiaux durant la négociation de la connexion.
Dans la pratique, une connexion TCP est établie avec l’échange de 3 paquets entre le client et le serveur :
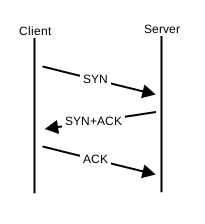
Le client envoie un paquet de demande de SYNchronisation de son numéro de séquence, c’est le SYN. Le serveur ACK-cepte le numéro de séquence et donc la demande de connexion et SYNchronise son propre numéro de séquence, c’est le SYN-ACK. Enfin, le client ACK-cepte le numéro de séquence du serveur, c’est le ACK final. La connexion est établie, le client et le serveur peuvent dialoguer.
Dans l’esprit, si l’on se met à la place du serveur, c’est un peu comme un appel téléphonique :
- Le téléphone sonne, le « serveur » décroche : c’est le
SYN - Le « serveur » répond « Allô ? » : c’est le
SYN-ACK - Le « client » répond « Allô ! » : c’est le
ACKfinal
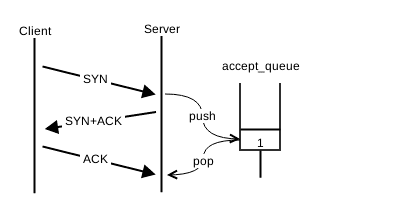
Parfois, le téléphone sonne, vous décrochez, et personne ne répond. Alors vous réessayez une fois, deux fois, parfois trois avant d’abandonner et raccrocher. Le protocole TCP suit exactement la même logique. Une fois qu’il a « décroché », c’est-à-dire reçu le SYN, il l’enregistre dans une file d’attente des connexions en cours d’ouverture. Le récepteur enverra un premier SYN-ACK. S’il ne reçoit pas de ACK dans la seconde suivante, il réessayera puis attendra 2 secondes puis 4, etc. jusqu’à recevoir une réponse ou atteindre le nombre maximum de tentatives. Dès que le récepteur reçoit le ACK final, la connexion peut être acceptée par l’application. Elle quitte alors la file d’attente et une nouvelle connexion peut être mise en attente.
Sous Linux, le nombre maximum de tentatives peut être contrôlé avec le paramètre net.ipv4.tcp_synack_retries. Par défaut ce paramètre vaut 5, ce qui correspond à 6 attentes de 1, 2, 4, 8, 16 et 32 secondes, soit 63 secondes avant d’abandonner la tentative de connexion. Il est possible de surveiller les connexions à moitié ouvertes (« Half-Open ») avec des outils tels que netstat. Elles apparaîtront avec l’état « SYN-RECV ». Un très grand nombre de requêtes dans cet état indique soit un serveur surchargé soit… une attaque.
Dans cet exemple, j’ai forgé un paquet SYN à la main en utilisant une adresse et un port source qui ne m’appartiennent pas, comme le ferait un attaquant. La connexion en cours d’ouverture reste bloquée en état « SYN-RECV »
| col0 |
|---|
| $> netstat -latpn | grep SYN_RECV tcp 0 0 149.202.175.124:22 42.42.42.42:42424 SYN_RECV - |
Vulnérabilités et attaques
Pour réemployer l’analogie de l’appel téléphonique, après avoir décroché et répondu « Allô ? », il arrive que personne ne réponde, même après plusieurs tentatives. Cela peut se produire lorsque vous êtes appelé par un plaisantin ou un centre de démarchage téléphonique peu scrupuleux. Dans l’intervalle, vous avez été injoignable. Si vous attendiez un appel important, vous en êtes pour vos frais. C’est le déni de service.
Pour un serveur, c’est le même principe. Le système d’exploitation maintient une file d’attente par serveur pour les connexions en cours d’ouverture. Cette file d’attente peut contenir un nombre limité de connexions en attente du ACK final. Le « syn_backlog ». Si la file d’attente est remplie avec des connexions en attente, les demandes de connexion suivantes ne pourront pas être honorées pendant le temps d’attente (63 secondes par défaut sous Linux) et c’est le déni de service pendant ce temps. Sous Linux, la taille de la file peut être contrôlée avec le paramètre net.ipv4.tcp_max_syn_backlog. Par défaut ce paramètre vaut 256, et est ajusté automatiquement en fonction de la mémoire totale de la machine.
Quelle que soit la taille de la file, il est possible de la remplir. Il suffit d’envoyer autant de SYN que la file peut en contenir pendant la durée de retry. Par exemple, une file pouvant contenir 256 connexions en attente (la valeur par défaut sous Linux, sans ajustement), celle-ci peut théoriquement être remplie en envoyant à peine plus de 4 paquets par seconde (PPS) ! Pire encore, dans la mesure où le client malicieux n’a pas besoin d’inspecter la réponse SYN-ACK, il peut forger une adresse et un port de destination aléatoires et ainsi passer outre les détections statistiques.
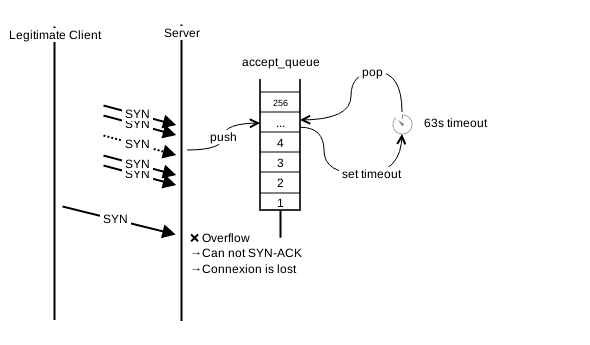
À cela s’ajoute que la simple réception d’un paquet sur un serveur consomme des ressources mémoire et CPU. Même si le paquet ne peut pas être mis en file d’attente, il aura consommé des ressources temporaires et affecté les performances de la machine. Si les ressources sont suffisantes, la barrière suivante est la capacité du réseau. On rentre là dans le cadre du déni de service distribué (le DDoS), qui sort du cadre de ce post. Mais l’idée reste la même. Nous devons protéger nos clients en entrée du réseau. Un serveur seul n’a simplement aucune chance.
Mitigation classique
Plusieurs stratégies de mitigation existent et elles sont généralement combinées pour une meilleure efficacité. Par exemple, en première ligne de défense, le paramètre net.ipv4.tcp_synack_retries peut être diminué. Cette valeur étant logarithmique, chaque décrément divisera par 2 le temps d’attente maximal pour un ACK, mais augmentera le risque de perdre des connexions légitimes. En fonction des capacités de la machine, le net.ipv4.tcp_max_syn_backlog pourra aussi être augmenté.
En deuxième ligne de défense, le système d’exploitation peut décider de recycler les plus anciennes demandes de connexion de la file pour en accepter de nouvelles, sans attendre que l’ensemble des retransmissions du SYN-ACK aient été envoyées. Linux tente de réserver la moitié des entrées de la file pour les « embryons » de connexion. Il considère une connexion jeune jusqu’à 2 retransmissions, soit approximativement 7 secondes au lieu des 63 par défaut.
Enfin, en troisième ligne de défense, la plus puissante : les SYN cookies. Ça tombe bien, c’est le sujet de cet article 😉
Une attaque SYN flood a fonctionné si la file d’attente des connexions a débordé. On peut l’agrandir, mais pas à l’infini car les ressources sont limitées et on préfère les réserver pour les clients légitimes. La technique du SYN cookie suit une approche radicalement différente : si l’objectif de l’attaque est de saturer la file, supprimons la file ! C’est un peu l’approche de l’appendicite : si l’appendice est enflammé, les chirurgiens le retirent.
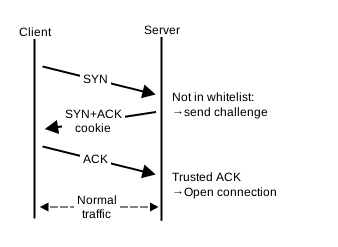
Le principe est simple. Lorsque le destinataire reçoit un SYN, il calcule une signature cryptographique à partir de l’adresse source, de l’adresse de destination, du port source, du port de destination, du numéro de séquence initial du client, d’une valeur dérivée du MSS si disponible (le Maximum Segment Size), ainsi qu’une valeur secrète qui change périodiquement. L’implémentation peut varier d’un système d’exploitation à l’autre, mais l’idée reste la même : encoder une signature du quadruplet définissant la connexion et le numéro de séquence initial du clien avec une valeur secrète. Cette signature cryptographique est alors utilisée comme numéro de séquence initial du serveur dans le SYN-ACK. Si le client est légitime, il répondra au SYN-ACK avec un numéro d’ACK égal à cette valeur + 1. Le serveur recalcule cette valeur de son côté. Si la valeur est cohérente, la connexion est acceptée, comme si elle avait été enregistrée dans la file. C’est en quelque sorte le réseau qui sert de file dans ce cas.
La technique du SYN cookie permettant de se passer de la file intermédiaire, il serait tentant de l’activer en permanence et de désactiver la file d’attente des connexions en cours. Bien que parfaite en apparence, cette technique présente trois inconvénients. Le premier est assez intuitif : la suppression de la file fait également perdre la retransmission des SYN-ACK dans le cas d’une perte réseau. C’est a priori un inconvénient mineur. Si le SYN-ACK s’est perdu, le client pourra retransmettre le SYN. Un client légitime le fera de base tandis que, dans le cas d’un client malicieux, aucune inquiétude : les retransmissions en masse sont sa spécialité…
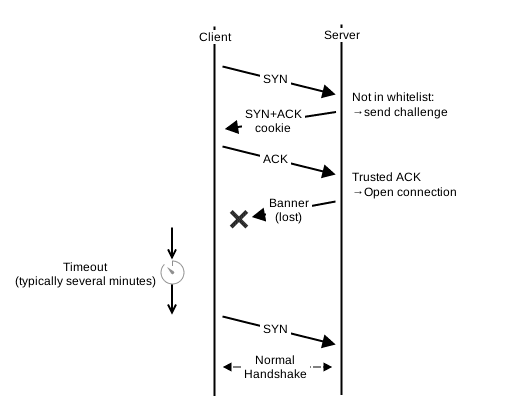
Le second inconvénient est le similaire au premier. Il est possible que le SYN-ACK soit bien arrivé à destination et que ce soit le ACK final qui se soit perdu dans les méandres d’Internet. Dans ce cas, le problème est bien plus important. Normalement, si le ACK n’est pas parvenu, la file va permettre de redéclencher l’envoi du SYN-ACK. Le client détecte alors une retransmission et déclenche à son tour une retransmission du ACK final. Ici, ce ne sera jamais le cas. Il y a alors 2 scénarios possibles. Soit le client est le premier à parler, c’est le cas du HTTP et du SSL dans lesquels le dialogue applicatif est initié par le client. Le serveur n’ayant pas reçu le ACK n’aura alors pas de connexion et déclenchera l’envoi d’un RST. Soit le client attend que le serveur envoie une « bannière » avant d’envoyer sa requête. C’est le cas par exemple du SSH, du IMAP et du SMTP. Dans ce cas, il faudra attendre que le client détecte un time out avant de réinitialiser la connexion, s’il a été programmé dans ce sens. Mais ce n’est pas toujours le cas. Quand on fait du développement bas niveau, il est toujours risqué de préjuger de la qualité des implémentations des applications réseau…
Le troisième et dernier inconvénient est que certaines options TCP ne sont envoyées que lors du SYN. Et certaines sont particulièrement importantes pour les performances. Par exemple la MSS pour Maximum Segment Size est l’équivalent de la MTU au niveau TCP. Elle permet d’éviter la fragmentation du paquet IP. Elle est tellement critique qu’elle est encodée dans la signature du SYN cookie de manière à pouvoir être récupérée au ACK. Le SACK pour « Selective ACK » permet d’indiquer précisément ce qui a été reçu (ou non) pour limiter la quantité de données à retransmettre en cas de perte. Le WScale pour « Window scale » permet de passer la taille maximum de la fenêtre TCP de 64 KB à 1 GB. Cette option est particulièrement importante pour les connexions dont le produit latence x bande passante est grand. Le ECN pour « Explicit Congestion Notification » permet au récepteur de notifier l’émetteur qu’une congestion a été rencontrée sur le réseau avant que la perte se produise, ce qui lui permet d’adapter son débit. Ce n’est pas une option à proprement parler, mais un champ de l’entête TCP. Lors du SYN, il indique que l’émetteur est capable de notifier une congestion. Dans les autres cas, il indique une congestion. Ce paramètre est peu géré, mais important le cas échéant.
Parmi ces options, certaines ne sont pas renvoyées après le SYN (MSS, WScale, SACK Permitted). Elles sont normalement enregistrées dans la file d’attente des connexions et sont donc perdues. L’idéal serait de pouvoir les faire renvoyer par le client. Depuis Linux 2.6.26, ces options sont encodées dans les bits de poids faible du timestamp, un peu à la manière de la stéganographie. Le timestamp est une extension méconnue du TCP et pourtant largement utilisée par les systèmes d’exploitation. Elle permet entre autres de mesurer avec précision le RTO, c’est-à-dire le temps entre l’émission d’un paquet et la réception de sa réponse, comme le ferait un ping ICMP. Cette option fonctionne avec 2 champs : le timestamp de l’émetteur, et une copie de celui reçu. Dans la pratique, si le serveur encode les options dans son propre timestamp, le client les lui renverra dans le ACK. Le serveur pourra alors les décoder et les restaurer. Ce qui permet de palier une des plus importantes limitations des SYN cookies. Et ce, sans support particulier côté client.
En raison de ces limitations, dans Linux, le mécanisme de SYN cookie ne sera activé lors d’un débordement de la file d’attente que si le paramètre net.ipv4.tcp_syncookies est à 1.
De manière plus anecdotique, l’astuce de l’encodage des principales options dans le timestamp a été intégrée dans Linux alors que la question de son obsolescence se posait. L’une des raisons étant la perte de ces options. Il était également suggéré que les machines étaient devenues assez puissantes pour gérer ces attaques sans mécanisme de défense particulier. Plusieurs développeurs ont alors montré qu’il n’en était rien, benchmarks à l’appui. L’un de ces développeurs étant Willy Tarreau, l’auteur de HAProxy sur lequel se base la nouvelle solution d’IP Load Balancing proposée par OVH. Si vous souhaitez en savoir plus, je vous encourage à lire cet excellent article en anglais : https://lwn.net/Articles/277146/.
Comme l’a montré Willy Tarreau, le problème n’est pas résolu sans SYN cookie. Et même avec les SYN cookies, la charge de calcul passait de 60 % à 70 % dans ses tests. En effet, bien qu’il ne soit plus possible de faire déborder la file d’attente des connexions, il reste possible de surcharger le CPU et de rendre la machine complètement indisponible en la surchargeant de paquets SYN en raison du temps de traitement de chaque paquet.
Sous Linux, la cible iptables « SYNPROXY » optimise la gestion des SYN cookies depuis la version 3.12 en les gérant beaucoup plus tôt dans le traitement des paquets dans la pile TCP, ce qui permet de soulager le CPU et mieux tenir la charge. Cette implémentation utilise une stratégie légèrement différente. Au lieu de reconstruire la connexion lors du ACK, elle régénère le paquet SYN qui aurait dû être reçu par la pile TCP et fait en sorte que le numéro de séquence soit cohérent. Cette approche est possible, car cette cible iptables se trouve dans le même noyau Linux et a donc accès aux mêmes primitives.
Lorsque nous avons conçu l’infrastructure de la nouvelle offre IP Load Balancing, une attention particulière a été portée à différents types d’attaques TCP/IP, notamment pour les attaques de type SYN flood, malheureusement trop courantes.
Sur une machine équipée d’un Intel(R) Xeon(R) CPU E5-2650L v3 @ 1.80GHz avec 24 cœurs, sans HyperThreading, 256GB de RAM et une carte Mellanox ConnectX-4 100Gbit/s synchronisée à 40Gbit/s (meilleure stabilité), nous avons commencé à perdre des connexions à partir de 4M de PPS (2 Gbps) et la machine est devenue injoignable en SSH à partir de 7M de PPS. Ces tests ont été réalisés sur la cible iptables SYNPROXY.
7M de PPS avant de perdre une machine peut sembler large. C’est en réalité largement insuffisant. Nous avons déjà reçu et protégé nos clients d’attaques de ce type, comptant plusieurs dizaines de millions de paquets par seconde. La technique est bonne, mais une machine seule ne peut pas résister à une attaque soutenue.
Mitigation par l’IP Load Balancer, featuring « Armor »
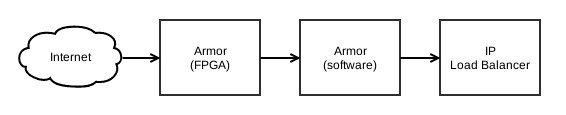
Pour être capable de soutenir toutes les attaques, même les plus violentes, chaque zone IP Load Balancing a sa propre instance de « Armor ». Armor est l’anti-DDoS développé intégralement en interne par OVH. Il est au cœur de la nouvelle génération de VAC. La plupart des stratégies de mitigation de Armor sont implémentées en logiciel de manière extrêmement optimisée. Mais pour soutenir une charge de plusieurs centaines de Gbps / millions de paquets par seconde, les stratégies de mitigation des attaques les plus massives sont implémentées directement sur FPGA. Un FPGA, pour « Field Programmable Gate Array », est une puce électronique reconfigurable. Le principe est simple : pouvoir configurer n’importe quel circuit électronique numérique sur la puce sans avoir à souder les transistors à la main. Cela nous permet de créer notre propre puce dédiée à la mitigation d’attaques, avec des performances significativement plus élevées que ce que nous pourrions obtenir en logiciel.
Un FPGA est fait de différents éléments de base qui peuvent être assemblés pour concevoir des circuits logiques spécialisés. Par exemple, pour un modèle Intel Arria 10 GT 1150, il y a environ 2 millions de registres qui servent de variables, 1 million de tables de correspondance qui permettent de composer les opérateurs logiques, 1 500 blocs de traitement du signal (DSP) spécialisés pour les calculs mathématiques, 2 000 blocs de RAM totalisant 50 Mb ainsi que des entrées/sorties et une très grande quantité de « fils » pour connecter tous ces éléments ensemble et réaliser le circuit.
Ce qui rend ces puces si intéressantes, c’est que chaque élément fonctionne indépendamment des autres. Un FPGA peut typiquement fonctionner à 200 MHz, ce qui est faible comparé aux processeurs. Mais comme tous les éléments fonctionnent en parallèle, il est possible de faire par exemple 1 million de calculs basiques et 2 000 écritures et 2 000 lectures dans la mémoire interne à chaque coup d’horloge. Soit 2×1014 (200 mille milliards) opérations par seconde et 4×1011 (400 milliards) écritures et lectures dans la mémoire interne par seconde.
Pour la mitigation anti-DDoS, le gain se fait à plusieurs niveaux. D’une part, la puce est organisée comme un très long pipeline dans lequel chaque paquet reçu est traité étape par étape, comme une chaîne d’assemblage dans une usine. Il y a des centaines d’étapes pour analyser le paquet, prendre une décision, le supprimer, le modifier, ou le laisser passer. Chaque étape du pipeline fonctionne en parallèle des autres. D’autre part, la puce donne également un accès direct aux interfaces réseau (40 ou 100 Gbps) ainsi qu’à des mémoires SRAM QDR-II, spécialisées dans les accès aléatoires à faible latence. Ces mémoires sont utilisées pour gérer des éléments mémoires nécessitant un accès par paquet : arbres de recherche, tables de hachage contenant des listes blanches ou des compteurs. C’est le type de mémoire qui est utilisé pour réaliser les registres et les caches des microprocesseurs.

La contrepartie de ces performances accrues est que le temps de développement sur FPGA est pour le moment plus élevé que sur CPU. En effet, le développement se fait à très bas niveau et il existe très peu de librairies open source réutilisables, même si ces deux points sont en train de s’améliorer. C’est pourquoi le FPGA est réservé aux attaques massives, et relativement simples à détecter. Cela permet de supporter des débits extrêmement élevés même avec des paquets de taille minimale.
Dans le cas de la mitigation du SYN flood, le FPGA fait les calculs de cookies de manière totalement parallèle, ce qui permet de garantir le traitement de 60 millions de paquets par seconde sur la carte utilisée en amont du service IP Load Balancing. C’est le maximum que peut recevoir un lien 40G, il n’y a donc aucun risque de perdre des paquets tant que l’attaque ne sature pas le lien.
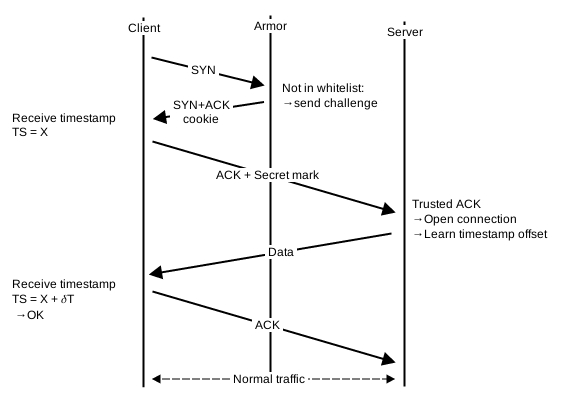
Dans les dernières étapes du pipeline, lorsque le FPGA a validé le cookie renvoyé par le client, il marque la connexion comme valide dans la mémoire QDR, marque le paquet comme valide, et le laisse passer. C’est le premier paquet de la connexion qui arrive sur un serveur de l’IP Load Balancing. Quand ce paquet arrive, le noyau tente de valider le cookie avec sa propre valeur secrète. Chaque serveur ayant sa propre valeur secrète, la validation échoue et le serveur envoie un paquet RST pour rejeter la connexion. Le client doit renouveler sa tentative de connexion pour que cela fonctionne. Or, l’objectif est de rendre la mitigation transparente pour les visiteurs.
Une solution serait de synchroniser cette valeur secrète entre toutes les machines et le FPGA. Cependant, ce faisant, la valeur secrète devrait être exposée en dehors du noyau, ce qui aurait eu pour effet d’augmenter la surface d’attaque, alors que l’objectif est de la réduire. De plus, d’expérience, synchroniser des machines entre elles est toujours plus compliqué qu’il n’y parait au premier abord. Les dizaines d’articles publiés à chaque introduction d’un « leap second » dans les serveurs de temps en témoignent.
En y regardant de plus près, si on utilise le même algorithme de génération du cookie et du timestamp, il est possible de s’appuyer sur l’implémentation standard de Linux pour reconstruire la connexion et ses options. La seule étape à adapter étant la validation du cookie lui-même. Dans ce cas, quand le FPGA valide une connexion, il insère une valeur secrète dans le paquet qui ne peut pas être forgée par un client malicieux. Le noyau détecte et valide cette valeur secrète et passe le relais à l’implémentation standard.
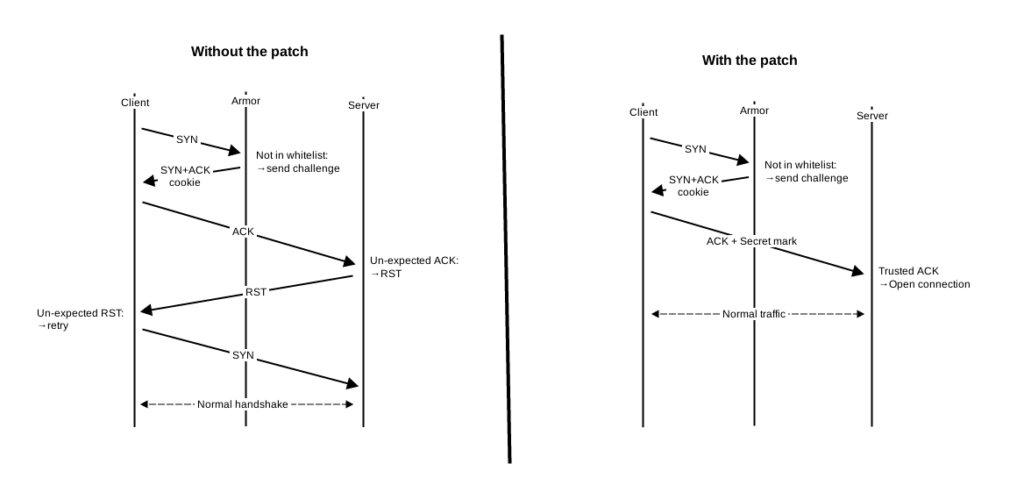
Mission accomplie ! Ou presque.
Le FPGA ne sait pas quelle machine physique prendra en charge la connexion si elle est valide. Pour cette raison, il ne peut pas « prédire » le « bon » numéro de séquence initial dans le SYN cookie. De même il ne peut pas prédire la « bonne » valeur du timestamp. En effet, le timestamp est un entier de 4 octets dérivé de l’uptime de la machine, qui est propre à chaque machine. Par la suite, quand le serveur envoie un paquet à destination du client, par exemple avec la réponse d’une requête HTTP, le client compare la valeur du timestamp avec celle reçue lors du SYN-ACK. Si l’écart entre les 2 valeurs est de plus de 2 milliards, c’est-à-dire la moitié de la valeur maximale du compteur, le client considère qu’il s’agit d’un « ancien » paquet qui revient et l’ignore. C’est le mécanisme « PAWS » pour Protection Against Wrapped Sequence (https://www.ietf.org/rfc/rfc1323.txt). Cette protection a été pensée pour gérer le cas de rebouclage du numéro de séquence, c’est-à-dire lorsqu’il repasse par 0. Le paquet et les suivants étant ignorés, la connexion est bloquée.
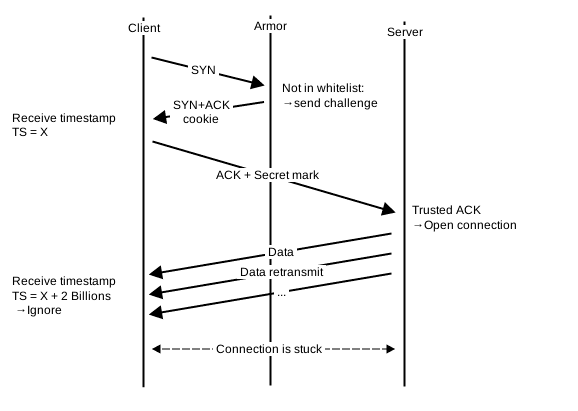
Une solution serait de désactiver l’option timestamp. Or cela reviendrait à sacrifier les performances dans la mesure où les options liées aux performances sont justement encodées dans ce champ, ce qui n’est pas envisageable.
Une autre approche, celle qui est en cours de déploiement, est d’apprendre le décalage entre la valeur choisie par le FPGA et la valeur courante du noyau Linux. On pourrait penser que c’est très intrusif, car cela implique d’enregistrer ce décalage dans chaque socket TCP et d’appliquer la différence pour chaque paquet sortant. Et c’est le cas. Mais la bonne nouvelle est que ce code existe déjà dans le noyau depuis le commit https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=ceaa1fef65a7c2e017b260b879b310dd24888083. Ce commit a été ajouté en 2013 par un développeur de OpenVZ dans le cadre du projet CRIU pour « Checkpoint and Restore In Userspace ». Autrement dit, migration à chaud de processus. Et dans ce cadre, il est nécessaire de migrer l’état de connexions TCP entre des machines ayant un uptime et donc un timestamp différent. D’où ce patch, sur lequel le service IP Load Balancing s’appuie pour reconstruire les connexions de manière vraiment transparente lors de la réception du ACK final.
— Article rédigé par Jean-Tiare Le Bigot (@oyadutaf) et Tristan Groléat (@twisterss)