
Today, we are generating more data than ever. 90 percent of global data has been generated in the last 2 years. By 2025 the amount of data in the world is estimated to reach 175 Zettabyte. In total, people write 500 million tweets per day, and autonomous cars generate 20TB of data every hour. By the year 2025 more than 75 billion IoT devices will be connected to the web, which will all generate data. Nowadays, devices and services that generate data are everywhere. .

There is also the notion of data exhaust which is the by-product of people’s online activities. It’s the data that’s generated as a result of someone visiting a website, buying a product or searching for something using a search engine. You may have heard this data described as Metadata.
We will start drowning in a flood of data unless we learn how to swim – how to benefit from vast amounts of data. To do this we need to be able to process the data for the sake of better decision-making, preventing fraud and danger, inventing better products or even predicting the future. The possibilities are endless.
But how can we process this huge amount of data? For sure, it’s not possible to do it the old fashioned way. We need to upgrade our methods and equipment.
Big data are data sets that have a volume, velocity and variety too large to be processed by a local computer. So what are the requirements for processing “big data”?

1- Process data in parallel
Data is everywhere and available in huge quantities. First off, lets apply the old rule: ‘Divide and Conquer’.
Dividing the data means that we will need data and processing tasks to be distributed across several computers. These will need to be set in a cluster, to perform these different tasks in parallel and gain reasonable performance and speed boosts.
Lets assume that you needed to find out whats trending on twitter. You would have to process around 500 million tweets with one computer in one hour. Not so easy now, is it? And how would you benefit if it took a month to process? What is the value in finding the trend of the day, one month later?
Parallelization is more than a “nice to have” feature. It’s a requirement!
2- Process data in the cloud
The second step is to create and manage these clusters in an efficient way.
You have several choices here, like creating clusters with your own servers and managing them by yourself. But that’s time consuming and costs quite a lot as well. It also lacks some features you may wish to use, like flexibility. For these reasons, the cloud appears to be a better and better solution every day for a lot of companies.
The elasticity that cloud solutions provide, helps companies to be flexible and adapt infrastructure to their needs. With data processing, for example, we will need to be able to scale up and down our computing cluster easily to adapt the computing power to the volume of data we want to process according to our constraints (time, costs, etc.).
And then, even if you decide to use a cloud provider, you will have several solutions to choose from, each with their own drawbacks. One of these solutions, is to create a computing cluster over the dedicated servers or public cloud instances and send different processing jobs to the cluster. The main drawback, in this solution, would be that if no processing is done, you’re still paying for the reserved but unused processing resources.
A more efficient way would therefore be to create a dedicated cluster for each processing job, with the right resources for that job, and then delete the cluster after. Each new job would have it’s own cluster, sized as needed, spawned on demand. But this solution would only be feasible if the creation of a computing cluster took but a few seconds and not minutes or hours.
Data locality
When creating a processing cluster, it is also possible to consider data locality. Here, cloud providers usually offer several regions spread across data centers situated in different countries. It has two main benefits:
The first one is not directly linked to data locality but more of a legal point. Depending on where your customers are, and where your data is, you may need to comply with local data privacy laws and regulations. You may need to keep your data in a specific region or country and not be able to process it outside. So, to create a cluster of computers in that region, it is easier to process data while complying with local privacy policies.
The second benefit is, of course, the potential to create your processing clusters in close physical proximity to your data. According to estimations, by the year 2025, almost 50 percent of data in the world will be stored in the cloud. On-premises data storing is in decline.
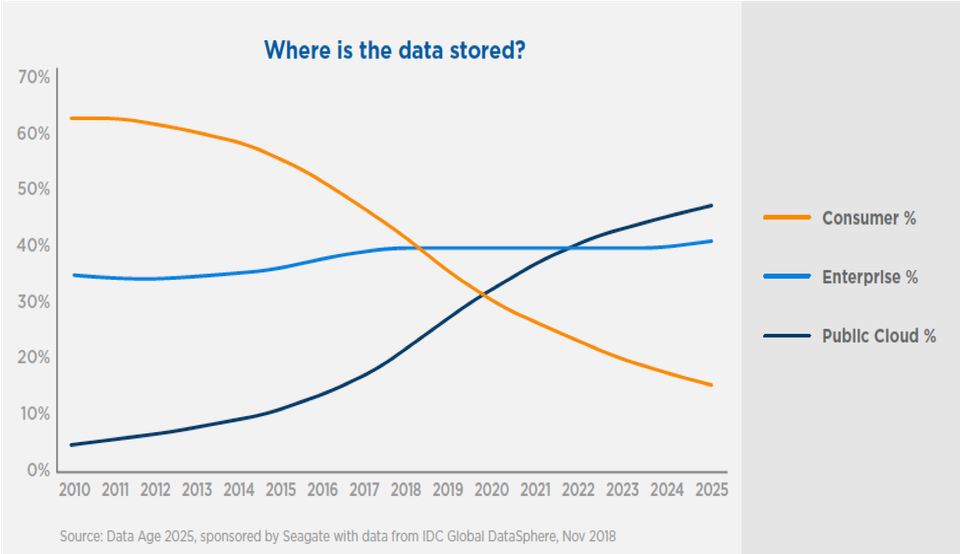
Therefore, using cloud providers that have several regions gives companies the benefit of having processing clusters near their datas physical location – this greatly reduces the time (and costs!) it takes to fetch data.
While processing your data in the cloud may not be a requirement per se, its certainly more beneficial than doing it yourself.
3- Process data with the most appropriate distributed computing technology
The third and final step, is to decide how you are going to process your data, meaning with what tools. Again, you could do it by yourself, by implementing a distributed processing engine in a language of your choice. But where’s the fun in that? (okay, for some of us it might actually be quite fun!)
But it would be astronomically complex. You would need to write code to divide the data into several parts and send each part to a computer in your cluster. Each computer would then process its part of data, and you would need to find a way to retrieve the results of each part and to re-aggregate everything into a coherent result. In short, it would be a lot of work, with a lot of debugging.
Apache Spark
But there are technologies that have been developed specifically for this purpose. They distribute the data and processing tasks automatically and retrieve the results for you. Currently, the most popular distributed computing technology, especially in relation to Data Science subjects, is Apache Spark.
Apache Spark is an open-source, distributed, cluster-computing framework. It is much faster than the previous one, Hadoop MapReduce, thanks to features like in-memory processing and lazy evaluation.
Apache Spark is the leading platform for large-scale SQL, batch processing, stream processing and machine learning. For coding in Apache Spark, you have the option of using different programming languages (including Java, Scala, Python, R and SQL). It can run locally in a single machine or in a cluster of computers to distribute its tasks.
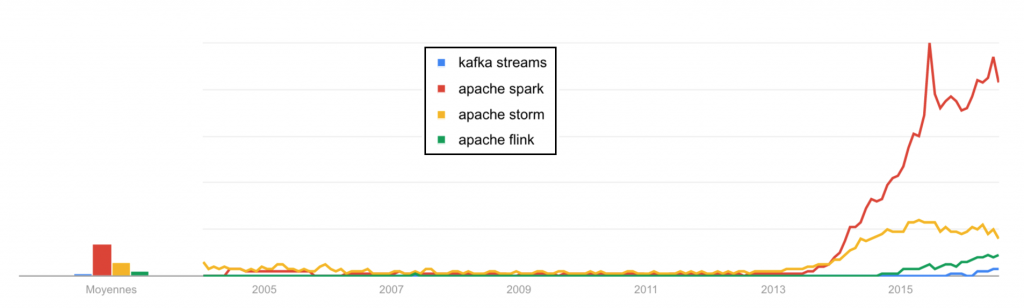
As you can see in the google trends data chart above, there are alternatives. But Apache Spark has definitely established itself as the leader in distributed computing tools.
OVHcloud Data Processing (ODP)
OVHcloud is the leader of European hosting and cloud providers with a wide range of cloud services like public and private cloud, managed Kubernetes and cloud storage. But besides all the hosting and cloud services, OVHcloud also provides a range of big data analytics and artificial intelligence services as well as platforms.
One of the data services offered by OVHcloud is OVHcloud Data Processing (ODP). It is a service that allows you to submit a processing job without worrying about the cluster behind it. You just have to specify the resources you need for the job and the service will abstract the cluster creation, and destroy it for you as soon as your job finishes. In other words, you don’t have to think about clusters any more. Decide on how many resources you will need to process your data in an efficient way, and then let OVHcloud Data Processing do the rest.
On-demand, job-specific Spark clusters
The service will deploy a temporary, job-specific Apache Spark Cluster, then configure and secure it automatically. You don’t need to have any prior knowledge or skills related to the cloud, networking, cluster management systems, security, etc. You only have to focus on your processing algorithm and Apache Spark code.
This service will download your Apache Spark code from one of your Object Storage containers, and ask you how much RAM and CPU cores you would like your job to use. You will also have to specify the region you want the processing to take place in. Last but not least, you will then have to choose the Apache Spark version you want to use to run your code. The service will then launch your job within a few seconds, according to the specified parameters until your job’s completion. Nothing else to do on your part. No cluster creation, no cluster destruction. Just focus on your code.
Your local computer resources no longer limit the amount of data you can process. You can run any number of processing jobs in parallel in any region and any version of Spark. Its also very fast and very easy.

How does it work ?
On your side You just need to:
- Create a container in OVHcloud Object Storage and upload the Apache Spark code and any other required files to this container. Be careful not to put your data in the same container as well, as the whole container will be downloaded by the service.
- You then have to define the processing engine (like Apache Spark) and its version, as well as the geographical region and the amount of resources (CPU cores, RAM and number of worker nodes) you need. There are three different ways to execute this (OVHcloud Control Panel, API or ODP CLI)
These are different steps that happen when you run a processing job in OVHcloud Data Processing (ODP) platform:
- ODP will take over and handle the deployment and execution of your job according to the specifications that you defined.
- Before starting your job, ODP will download all files that you uploaded in the specified container.
- Next, ODP will run your job in a dedicated environment, created specifically for your job. Apart from a limitation on the available ports (list available here), your job can then connect to any data source (databases, object storage, etc) to read or write data (as long as they are reachable through the Internet)
- When the job is complete, ODP stores the execution output logs to your Object Storage and then deletes the whole cluster immediately.
- You will be charged for the amount of resources you specified and only for the duration of your job computation, on a per-minutes basis.
Different ways to submit a job?
There are three different ways that you can submit a processing job to ODP, depending on your requirements. These three ways are OVHcloud Manager, OVHcloud API and CLI (Command Line Interface).
1. OVHcloud Manager
To submit a job with OVHcloud Manager you need to go to OVHcloud.com and login with your OVHcloud account (or create one if neccessary). Then go to the “Public Cloud” page and select the “Data Processing” link on the left panel and submit a job by clicking on “Start a new job”.
Before submitting a job you need to create a container in OVHcloud Object Storage by clicking on “Object Storage” link on the left panel and upload your Apache Spark code and any other required files.
2. OVHcloud API
You can submit a job to ODP by using OVHcloud API. For more information, you can see the OVHcloud API web page https://api.ovh.com/. You can create job submit automation by using ODP API.
3. ODP CLI (Command Line Interface)
ODP has an open source Command Line Interface that you can find in OVH public GitHub at https://github.com/ovh/data-processing-spark-submit). By using CLI, you can upload your files and codes and create your Apache Spark cluster together with just one command.
Some ODP benefits
You can either always run your processing tasks in your local computer, or you can create an Apache Spark cluster in your local premises with any cloud provider. This means you can manage that cluster yourself or using similar services from other competitors. But ODP has several benefits, it is good to have them in your mind when deciding on a solution:
- No cluster management or configuration skills or experience is needed.
- Not limited by resources and easy and fast. (The only limit is your cloud account quota)
- Pay as you go model with easy pricing and no hidden cost. (per-minutes billing)
- Per job resource definition (no more resources lost compared to a mutualised cluster)
- Ease of managing Apache Spark version (You select the version for each job and you can even have different jobs with different versions of the Apache Spark at the same time)
- Region selection (You can select different regions based on your data locality or data privacy policy)
- Start a Data Processing job in just a few seconds
- Real-time logs (when your job is running, you will receive real-time logs in your Customer Panel)
- Full output log will be available just after finishing the job (some competitors take minutes to deliver logs to you)
- Job submit automation (by using ODP API or CLI)
- Data Privacy (OVHcloud is European company and all customers are strictly protected by European GDPR)
Conclusion
With the advance of new technologies and devices, we are flooded with data. More and more, it is essential for businesses and for academic research to process data sets and understand where the value is. By providing the OVHcloud Data Processing (ODP) service, our goal is to provide you with one of the easiest and most efficient platforms to process your data. Just focus on your processing algorithm and ODP will handle the rest for you.

DevOps @OVHcloud, Cloud and Data Engineer, Developer Evangelist