
A few days ago, we were discussing the GPU strategy for AI in OVHcloud. I realised after a few hours of calls that our finance colleagues were still finding the technical parts of this topic difficult to get their heads round, so I decided to write them a guide. Then someone joked that many of our customers were also confused, so the guide is now a blog post 😉
This guide focuses on GPU-based inference for Large Language Models (LLMs). When we refer to “performance” we mean tokens per second. It’s not a technical deep dive, but it should help you choose the right GPU setup for your use case. Many of the details have been simplified to keep the information practical and accessible.
TL:DR – Best LLM inference options in OVHcloud (As of July 2025)
These are the best deployment options currently available at OVHcloud for LLM Inferencing. The offering will evolve with time as new GPUs are released

1 – Scope your requirements
Before you go any further, try to scope your requirements (The answers to the following questions will help you to choose the best solution).
- What model do you want to deploy ? (e.g. Llama3 70B)
- How many parameters does it have? (e.g. 7B, 70B, 120B)
- What context length do you need? (e.g. 32K, 128K)
- What precision or quantization level? (FP16, FP8, etc.)
- How many concurrent users? (A single user ? 10 ? 500 ? 10000 ?)
- What inference server? (e.g. LLM, TensorRT, Ollama…)
- Throughput needs? (e.g. latency per user, total TPS)
- Is the usage stable or bursty? Predictable or not?
Note : This guide assumes you are interested in inference on an 8B+ LLM on GPU (we won’t cover small LLMs using CPU compute)
2 – Choosing the GPU model – Discriminant Criterion
a) Quantization / Precision support
What is Quantization ? The idea is to reduce the precision of the model weights in order to reduce the memory and computation required, at the cost of a small decrease in the model quality. Quantization reduces memory and compute costs by lowering precision (e.g., FP16 → FP8 → FP4), usually at the cost of model quality. It’s a trade-off.
Currently LLM models are most often published in FP16 but often deployed in FP8 as the loss in quality is far outweighed by the gain in speed.
GPU Quantization Support
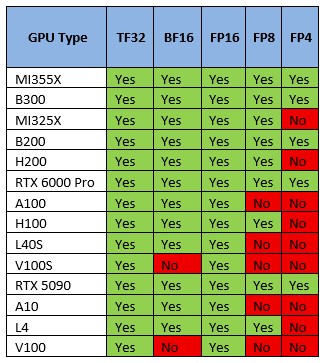
Most GPUs don’t support all types of precision/quantization so it’s a discriminant criterion. Choose a GPU that supports the quantization format you plan to use.
b) Minimum Nb of GPU to run your model
For inference you need to load all the model weights (**) in memory (GPU memory, not RAM) and keep room for Context/Cache. Either you have enough memory or it will simply not work.
Here is a rule of thumb for calculating the required GPU memory for LLMs :
Total GPU memory = (Parameters × Precision Factor) + (Context Size × 0.0005)With Precision Factor :
| FP32 | 4 |
| FP16 | 2 |
| FP8 | 1 |
| FP4 | 0.5 |
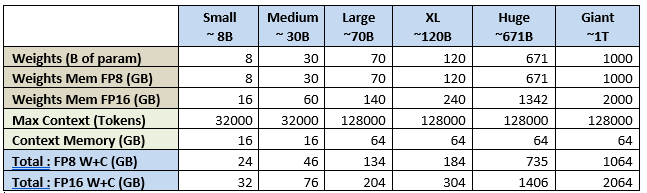
Example: Llama 3.3 70B, with 128k context, in FP8 would need 70 GB for the model weights + 62.5 GB for the context
If we apply this formula to few standard LLM sizes / Contexts, we get the following:
Now we’ll apply this to the most common GPU you can find to get the minimum number of GPU you need :
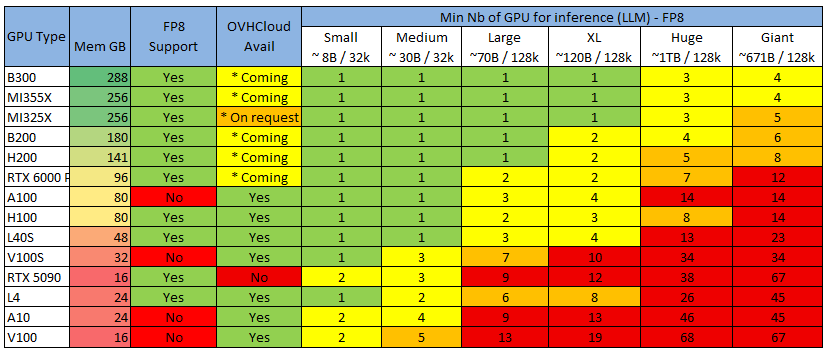

Color Legend, considering that servers usually come with 4 or 8 GPU (16 GPU soon)
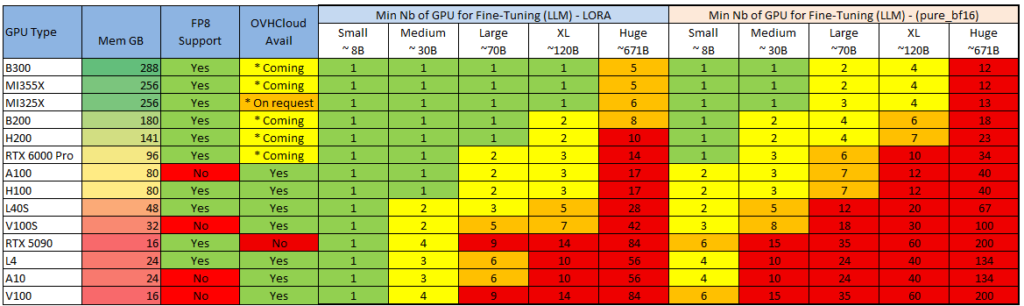
See also for 2 common Fine-tuning methods :
Note : it’s possible to run (small) LLM inference in CPU (see Llama.cpp) but only small models (or high levels of quantization with lower quality).
** Note : it’s possible to reduce the memory needs by “offloading” part of the model layers so RAM, but I won’t cover that (Check out LocalLlama reddit sub – some make a sport out of it) as the performances are poor and I guess if you are coming to cloud, it’s for the real experience 😉
c) Feature x Hardware compatibility
The last discriminant criteria for choosing a GPU is the hardware compatibility with some inference servers features.
Inference servers (the software that runs the model) may have features that are not compatible with certain GPUs (brand or generation).
These change often so I won’t list them but here is an example for VLLM : https://docs.vllm.ai/en/latest/features/compatibility_matrix.html#feature-x-hardware_1
The most common example we see is that “Flash Attention” mechanism is not supported on Tesla generation Nvidia cards, like V100 and V100S.
3 – Choosing the GPU setup and deployment – Performance criterion
a) What impacts the performance for inference ?
Overview
Several elements impact the overall performance (i.e. the tokens/second), with approximate order of importance as follows :
1 – The GPU performance
2 – The Network performance (between GPU and between servers)
3 – The Software (Inference Server, drivers, OS)
Below is an explanation of each and the options you have to choose from.
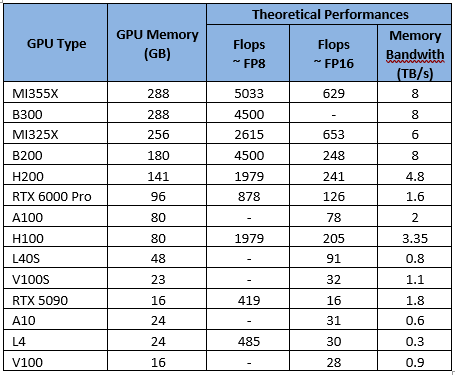
The GPU performance
This is mostly linked to the compute power (“flops”) of the GPU and the bandwidth of its memory (depending on the generation).
See the theoretical performances (what is communicated by Nvidia and AMD) listed below :
The Network performance
When inference takes place, your data flows in several ways:
- GPU to Motherboard : The speed depends on the type and version of the connection. Usually it’s PCIE or SXM (proprietary connection from Nvidia).
In a nutshell : Overall SXM > PCIE and the higher the version the better.
- GPU to GPU : Either the communication goes through the motherboard (so PCIE/SXM) or you have a GPU direct interconnection. Nvlink is the Nvidia solution.
In a nutshell : If you are using several Nvidia GPUs, choose servers with Nvlink.
- The network between Servers (if using multiple servers) : Ethernet, Infiniband…
In a nutshell : if you are distributing your inference over several servers, choose Infiniband over Ethernet.
The software performance (Inference Server, Drivers)
Performance will vary widely based on the Inference Server (VLLM, Ollama, TensorRT…), the underlying libraries used (Pytorch…), and underlying drivers (Cuda, RocM).
In a nutshell : Use the latest versions !
Not all inference servers provide the same performance or provide the same features. I won’t go into the details but here are some tips :
- Ollama : Simple to setup/use. Best option for single user.
- VLLM : Best for getting the latest models and features fast but complex to configure well
- TensorRT : Best throughput but lag In support for new models / features and only works on Nvidia GPU.
a) Different deployment options
Now that you know which GPU and server to choose, you also have several options for the architecture setup.
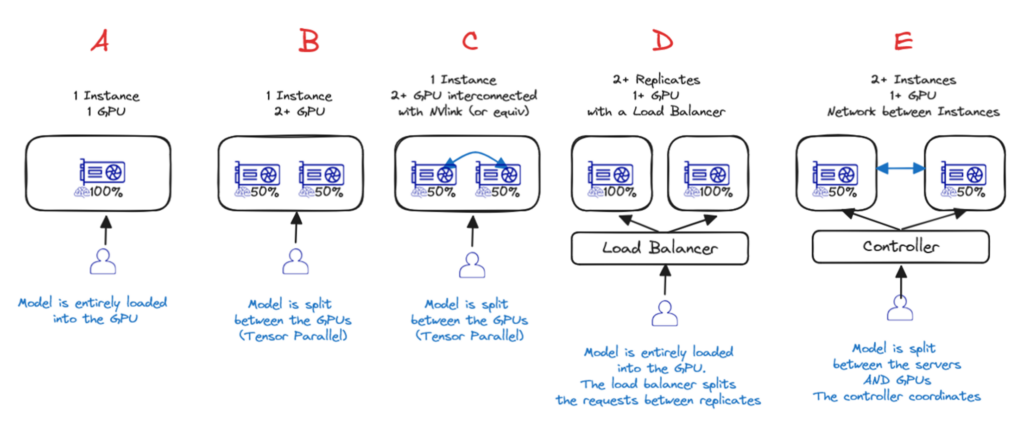
Option A – Single GPU
If the model is small enough to fit into a single GPU, then it’s the best option !
Option B and C – Single instance, Multiple GPU (with or without interconnect)
If it’s too big for a single GPU, then the best option is a single server with multiple GPUs. Either with (Option C) or without Nvlink (Option B). In these two cases the weights of the models are spread over the different GPUs but there is a cost : you will not have 2x the performance of 1 GPU !
Option D – Single instance, Multiple replicates with Loadbalancing
If the model fits on 1 server (1+ GPU) but the performance is not enough, or you need to scale dynamically based on the current needs, then your best option is to use multiple replicates and add a loadbalancer (Option D) – This what AI Deploy provides off the shelf.
Option E – Distributed inference over several servers
If the model is too large to even fit on a single server, then you must distribute the inference over several servers (Option E). By far the most complex (you need to setup the network and software for clustering) and the highest loss in performance (due to server to server network bottlenecks, on top of GPU to GPU).
c) Which OVHcloud product to use ?
For inference you have today six options to choose from :
| Product | Type | GPU Available |
| AI Endpoints | Inference API | Serverless |
| AI Deploy | Container as a Service | H100, L40S, A100, L4, A10, V100S |
| Cloud GPU | Virtual Machine | H100, L40S, A100, L4, A10, V100S, V100, RTX5000 |
| Managed Kubernetes Service | Kubernetes | H100, L40S, A100, L4, A10, V100S, V100, RTX5000 |
| Dedicated Servers | Bare Metal | L40S, L4 |
| On Prem Cloud Platform | DC as a Service | Any |
If you want a fully managed inference, then AI Endpoints is clearly the best option : it’s a serverless service where you pay per token consumed. You don’t need to deploy the model or manage it.
Caveat is that you need to choose from the models we propose (you cannot add your own) – That said we invite you to ask for new models on our Discord !
AI Deploy is a product specially tailored to run inference servers with a few key features :
- It’s a container as a service : you bring your own container, we run it.
- Simple configuration : you can launch several times the container via single command line and change the parameters directly via that command line.
- Scalability by design : at any time add replicates and we manage the loadbalancing.
- Autoscaling : you can setup autoscaling either on CPU/RAM thresholds and soon you will be able to use custom metrics too (ex : latency on the inference).
- Scaling to 0 : You will soon be able to scale to 0 à if no request has been sent to your server for some time, we stop the machine.
- Pay by the minute of compute, no commitment.

Director of Engineering - AI