
En 2018, nous avons lancé l’un des plus gros projets de l’histoire d’OVH : migrer les 3 millions de sites web hébergés dans notre datacenter de Paris. Si vous souhaitez découvrir les raisons de ce projet titanesque, vous pouvez lire cet article.
Il est désormais temps de vous expliquer comment nous avons procédé pour ce chantier. Nous avons déjà parlé de nos contraintes opérationnelles (ne pas avoir d’impact sur les sites web bien que nous ne maîtrisions pas le code source, limiter le temps d’indisponibilité…).
Nous avons aussi de nombreuses contraintes techniques, liées à l’architecture de nos services. Avant de décrire nos différents scénarios de migration dans le prochain article, nous allons vous expliquer comment fonctionne l’infrastructure hébergeant vos sites web.
Anatomie des hébergements web
Pour fonctionner, les sites et applications web ont généralement besoin de deux choses :
- le code source qui se charge d’exécuter le comportement du site web ;
- les données utilisées par le code source pour personnaliser l’expérience.
Pour qu’un site soit opérationnel, le code source est exécuté sur un ou plusieurs serveurs dont l’environnement a été configuré avec les outils liés aux langages de programmation utilisés. Dans le monde, c’est PHP qui est prédominant sur le marché mais le choix ne se limite pas qu’à ce langage.
Pour rester en condition opérationnelle, ces serveurs doivent être maintenus et mis à jour, et leur fonctionnement doit être continuellement surveillé. C’est un rôle généralement différent de celui des développeurs, qui se chargent de créer le code source du site web. Si le job vous intéresse, renseignez-vous sur les compétences des administrateurs systèmes et des devops.
Pour le propriétaire du site web, cela coûte cher : il faut avoir une équipe suffisamment grande pour gérer une présence 24 heures sur 24, 365 jours par an. Avec une telle équipe, les développeurs peuvent se concentrer sur des demandes de prestation ponctuelles, uniquement lorsque le propriétaire du site web souhaite le changer.
C’est cette gestion que nous proposons dans nos hébergements web. Au lieu de recruter une équipe d’administrateurs systèmes pour chaque site web, nous avons recruté une équipe d’experts techniques qui se chargent de l’ensemble des sites web que nous hébergeons. Et pour stocker les données ? Il faut aussi des serveurs et, donc, des équipes partagées entre tous les sites web que nous hébergeons.
De la même manière, chaque site web ne nécessite pas de bénéficier des ressources d’un serveur entier. En fonction de nos offres, nous mutualisons les ressources sur nos infrastructures : plusieurs sites web fonctionnent sur les mêmes serveurs.
L’ensemble de ces économies d’échelle nous permet de proposer une offre d’hébergement web à bas coût (à partir de 1,49 € HT/mois), tout en conservant un niveau de qualité important. D’ailleurs, nous vous expliquerons très prochainement comment nous calculons notre qualité de service. Si vous ne voulez pas attendre, allez voir la conférence que nos développeurs ont donné à la FOSDEM en février.
Pour atteindre ce niveau de qualité avec autant de sites web, nous avons aussi adapté notre infrastructure.
Architecture technique de nos hébergements web
La solution classique pour construire un service d’hébergement web est d’installer un serveur, d’y configurer des bases de données ainsi qu’un environnement d’exécution du code source, puis d’y placer les nouveaux clients jusqu’à ce que le serveur soit rempli, avant de passer au serveur suivant.
C’est très efficace, mais il y a quelques inconvénients sur ce type d’architecture :
- En cas de panne, la reprise sur activité peut être longue : à moins d’avoir une réplication en temps réel des systèmes, ce qui est très coûteux, il faut récupérer les données puis les migrer sur une nouvelle machine avant de rouvrir le service aux clients.
Bien que la probabilité de défaillance matérielle ou logicielle soit faible, c’est une opération courante sur les infrastructures de grande taille. - Pour réagir rapidement à l’introduction de nouvelles technologies sur le marché, vous pouvez uniquement les configurer sur les nouveaux serveurs dans un premier temps. Puis les ajouter sur les serveurs existants dans une seconde phase, afin de prendre le temps de les déployer correctement.
Mais sur un marché aussi rapide que celui d’Internet, il devient difficile d’avoir une infrastructure hétérogène. Les équipes techniques doivent alors s’adapter avec de multiples configurations différentes, augmentant les risques de régression ou de panne.
Pour les équipes support, il devient aussi très difficile de mémoriser toutes les configurations, étant donné leur nombre et leurs changements perpétuels. - Chaque brique logicielle est complexe. Afin d’obtenir les meilleures performances et la meilleure qualité de service, nous avons créé des équipes spécialistes de chaque technologie : bases de données, environnement PHP, systèmes de stockage, réseau… Faire interagir toutes ces équipes sur le même serveur peut être difficile au quotidien et entraîner des quiproquos dangereux pour la disponibilité des sites web.
- Il est difficile d’isoler un client qui consommerait plus de ressources que la moyenne. Ainsi, si vous avez de la chance, vous n’êtes pas sur le même serveur que ce client. Dans le cas contraire, les performances de votre site web peuvent en pâtir.
Vous l’avez compris, à notre échelle, nous avons choisi de partir sur une autre architecture, bien connue des sites web qui doivent tenir face à la charge : une architecture N-tier.
Architecture N-tier
Les architectures N-tier sont utilisées par les sites à forte charge afin de proposer plus de ressources pour chaque brique logicielle. Cela consiste à distribuer ces briques sur plusieurs serveurs.
En reprenant notre division code/données, nous avons donc trois serveurs nécessaires pour le fonctionnement d’un site web :
- un serveur chargé de l’exécution du code source ;
- deux serveurs de stockage fréquemment utilisés : bases de données et serveur de fichiers.
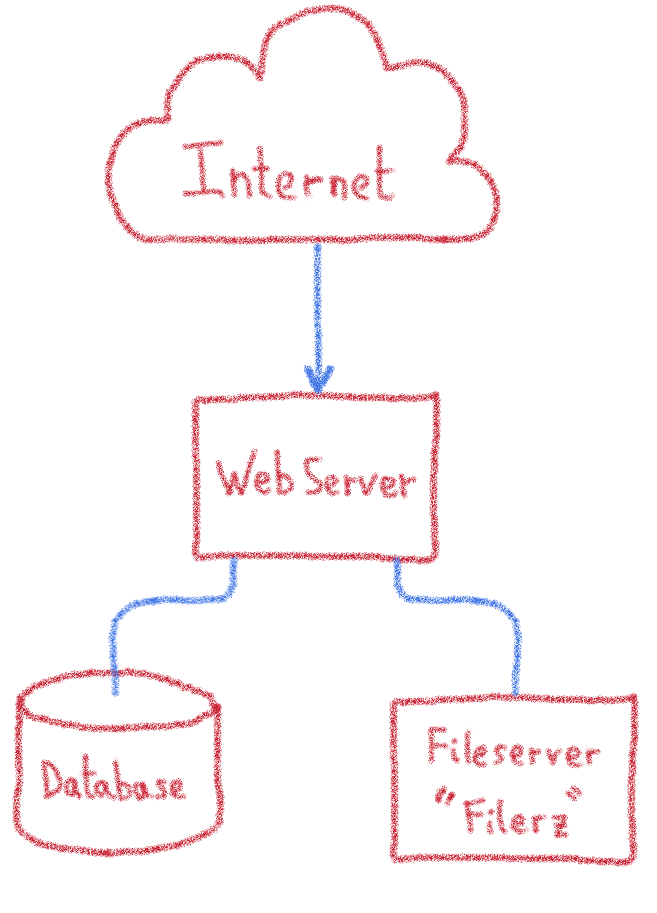
Serveurs de fichiers : Filerz
Ce sont les serveurs sur lesquels nous stockons les fichiers composant le site web ; généralement, c’est le code source des sites qui utilise ce stockage. Ces serveurs ont un matériel spécifique pour garantir les accès rapides aux données, ainsi que leur durabilité. Nous utilisons un système de fichiers spécialisé, nommé ZFS, qui nous permet de manipuler facilement les sauvegardes locales et distantes.
Ces machines sont gérées par une équipe dédiée nommée « Storage », qui fournit ce type de service à d’autres départements chez OVH (hébergement web, e-mails…). Si cela vous intéresse, ils proposent aussi les NAS-HA que vous trouverez dans le catalogue public de nos serveurs dédiés.
En cas de panne, nous conservons un stock de pièces et serveurs prêts à l’emploi, afin de rétablir le service au plus vite.
Bases de données
Les serveurs de bases de données sont généralement utilisés par les sites web pour accueillir les données du site de manière dynamique. Ils se composent d’un SGBD, système de gestion de bases de données (MySQL sur nos offres), qui structure les informations et les rend accessibles au travers d’un langage de requêtes (SQL dans notre cas).
Ces serveurs nécessitent aussi un matériel spécifique pour le stockage des données. Il faut de bonnes ressources en RAM afin de bénéficier des systèmes de cache des SGBD et répondre plus rapidement aux requêtes fréquentes.
Ces machines sont gérées par une équipe dédiée, nommée « Database », qui a la responsabilité de cette infrastructure. Elle propose aussi ces services au public, au travers de l’offre CloudDB.
C’est la même équipe qui se charge des SQL privés, aussi concernés par la migration.
À Paris, ces serveurs sont hébergés dans un Private Cloud (SDDC) qui permet de basculer des machines virtuelles à la volée d’une machine physique à l’autre en cas de soucis. Cela réduit les temps d’interruption pour maintenance ou le temps de rétablissement en cas de panne.
Serveurs web
Ce sont les serveurs qui reçoivent les requêtes et exécutent le code source correspondant au site web. En fonction du code source, ils se basent sur les fichiers et les données fournies sur les serveurs précédents. L’exécution du code source nécessite principalement de bonnes ressources en CPU.
Les serveurs ne conservant aucune donnée localement, il est possible d’en ajouter d’autres et de distribuer la charge sur plusieurs machines. Cela nous permet de répartir les sites web sur différents serveurs et d’éviter des distorsions d’utilisation au travers de l’infrastructure. En effet, les usages sont distribués sur tous les serveurs de la « ferme », dynamiquement.
Si l’un des serveurs tombe en panne, les autres machines de la ferme sont en capacité de reprendre le trafic. Cela nous permet d’utiliser de très nombreuses machines disponibles dans nos stocks, à condition qu’elles soient bien loties en ressources en CPU.
Répartition de charge
Les requêtes n’arrivent pas sur le bon serveur web par magie. Pour cela, il faut un point d’entrée qui envoie les requêtes au bon endroit. C’est une technologie connue : les load balancers (répartiteurs de charge, en français).
Dans notre datacenter de Paris, il s’agit de serveurs dont le matériel est dédié à la répartition de charge. Dans notre nouvelle infrastructure de Gravelines, nous utilisons une brique publique : les IPLB.
Le trafic des sites web arrive sur quelques adresses IP que nous dédions à nos hébergements web. Ces adresses ont pour destination nos répartiteurs de charge. Ainsi, ils sont le point d’entrée de nos infrastructures. Nous y avons d’ailleurs placé les meilleures technologies de protection contre les attaques DDoS, afin de sécuriser les sites web de nos clients.
Ces load balancers fonctionnent parfaitement pour un site à fort trafic réparti sur plusieurs serveurs web : les requêtes sont distribuées équitablement, avec des algorithmes de répartition de charge, sur l’ensemble des serveurs disponibles.
Mais notre besoin est différent : nous souhaitons avoir plusieurs sites différents sur un même serveur et changeons la répartition en fonction de plusieurs critères : l’offre souscrite (plus celle-ci est importante, moins de clients se trouvent sur le serveur), les ressources réellement utilisées (pour répartir la charge en continu)…
Nous avons aussi des offres où les ressources sont garanties (hébergement Performance : autant de clients que de ressources sur les serveurs), voire dédiées (Cloud Web : un serveur égal un client).
En réalité, la distribution de la charge est très fortement liée à nos clients et nous avons modifié le système de répartition avec une brique dédiée à OVH, nommée « predictor ». Elle se charge de choisir le serveur web, en fonction du site internet de la requête. Les « predictors » s’adaptent aux métriques de notre infrastructure, ainsi qu’aux données fournies par notre système d’information.
Cela complexifie quelque peu notre infrastructure. Nous en avons omis ici une grande partie pour limiter cet aspect. Mais restons sur cette représentation, elle est suffisante pour expliquer les scénarios envisagés et celui retenu.
Voici le schéma en ajoutant la répartition de charge, ainsi que les multiples serveurs de bases de données et de stockage de fichiers.
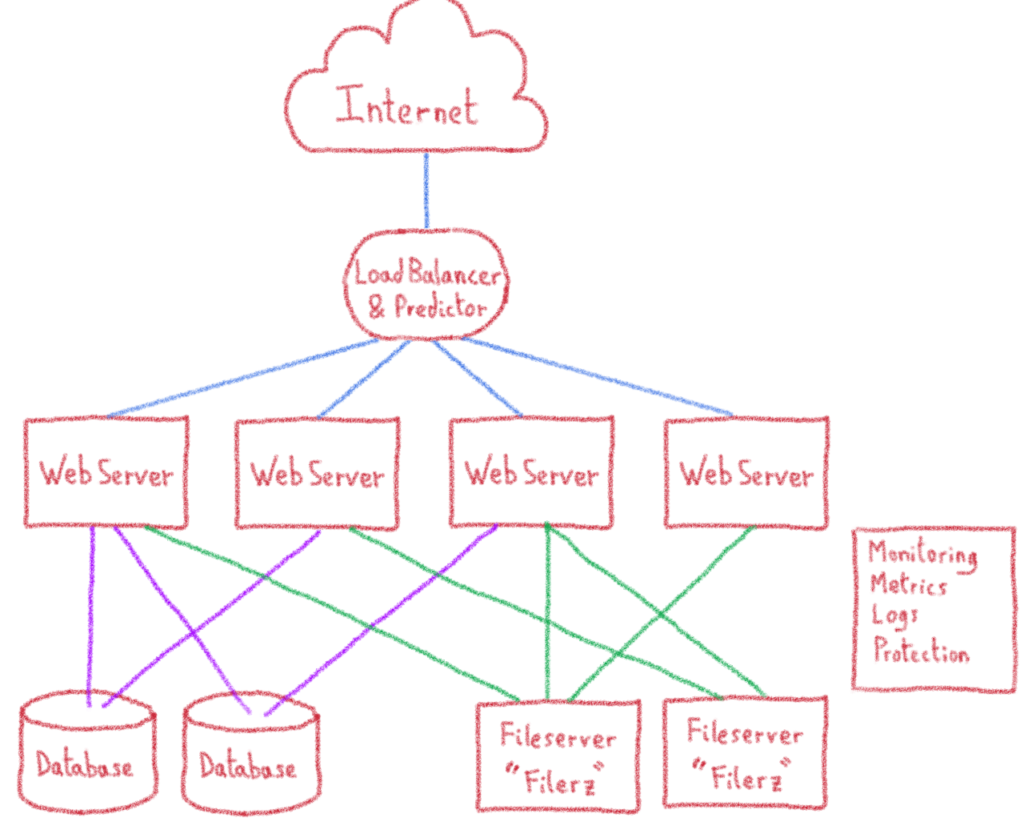
Cette architecture nous permet d’héberger un nombre incroyablement grand de sites web différents. Mais comme tous les administrateurs d’infrastructures le savent : « Shit happens. » C’est-à-dire qu’un jour ou l’autre, une panne arrivera. Il faut donc savoir comment réagir dans ce cas, s’entraîner et réduire les impacts.
Domaines de panne
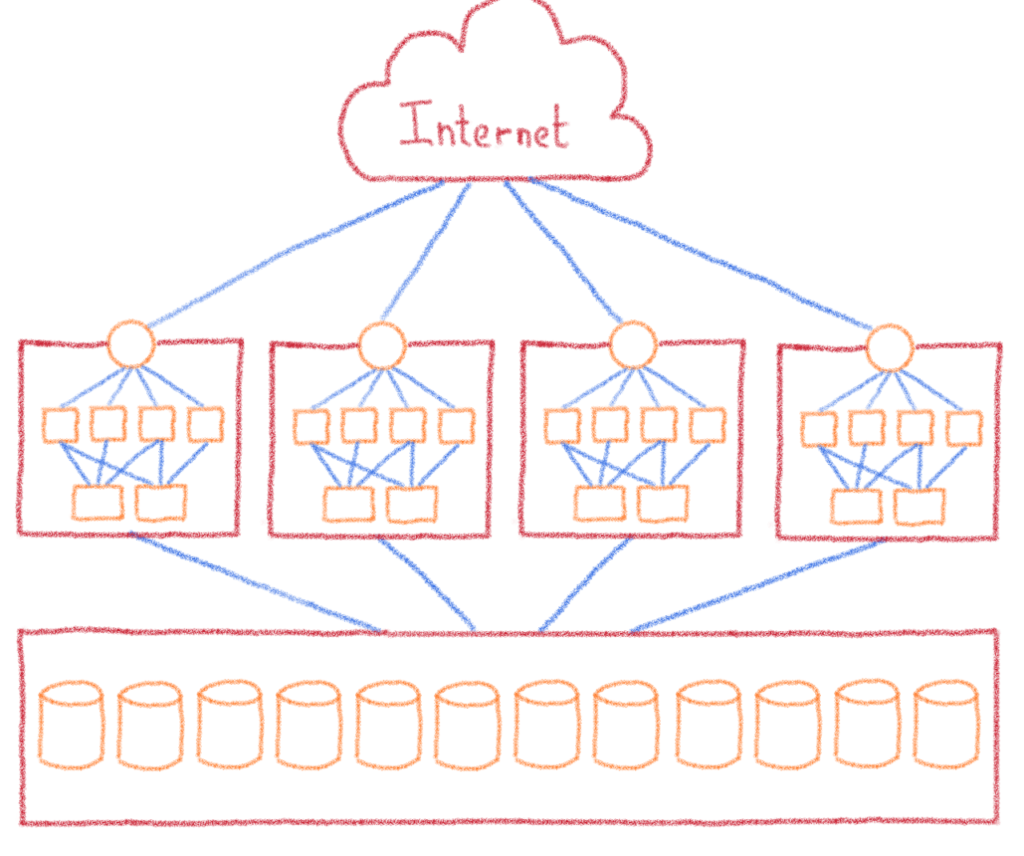
L’une des techniques pour réduire ces effets est de limiter le périmètre des pannes, en créant des domaines de panne. Dans un univers tout autre que l’informatique, nous retrouvons bien ce concept dans la gestion forestière, avec la création de parcelles vierges « pare-feu ». Ne parlons pas de la construction et des portes du même nom.
Dans notre métier, il s’agit de diviser l’infrastructure en plusieurs morceaux et de distribuer les clients au sein de plusieurs infrastructures. C’est la genèse de nos différents clusters. Nous avons découpé l’infrastructure de Paris en 12 clusters identiques. Dans chacun, nous retrouvons le load balancer, les serveurs web et les filerz. Si l’un des clusters tombe en panne, « seulement » 1/12e des clients sont touchés.
Les serveurs de bases de données sont traités à part : bien que cela ne soit pas mentionné comme fonctionnalité, nous permettons à nos clients de croiser l’utilisation de leurs bases de données entre leurs hébergements quand ils doivent partager des informations. Le choix du cluster n’étant pas à la charge du client, nous avons dissocié les bases de données des clusters afin de les rendre accessibles à tout le datacenter.
Pour la dernière fois, nous devons mettre à jour notre schéma d’infrastructure :
Pilotage de l’infrastructure
Toute cette infrastructure est nourrie par une configuration en temps réel, réalisée par notre système d’information. Cette partie fait le lien entre l’espace client, les API d’OVH et l’infrastructure.
Le système d’information possède une représentation exhaustive de l’infrastructure, ce qui permet d’adapter la livraison des nouveaux comptes, de gérer les changements d’offre ou bien les actions techniques sur les comptes.
Par exemple, lorsque vous créez une nouvelle base de données sur votre hébergement, c’est ce système d’information qui se charge de sélectionner le serveur sur lequel elle sera située. Il s’assure de sa création sur cette même infrastructure, avant de vous notifier par e-mail ou par API de sa disponibilité.
Félicitations, vous connaissez désormais notre architecture ! Pour savoir où tourne votre site web, vous trouvez dans votre espace client le nom des serveurs de bases de données, de filerz et de clusters liés à votre hébergement.
Contraintes techniques pour la migration
Cette architecture nous impose quelques contraintes techniques pour ne pas altérer le fonctionnement des sites web :
- l’adresse IP des sites web est partagée par tous les autres sites du même cluster ;
- il n’existe pas de correspondance entre les serveurs de bases de données et les clusters ;
- pour déplacer un site web, il faut synchroniser la migration du load balancer (à cause des adresses IP), du filerz et des bases de données associés à l’hébergement web ;
- le code source d’un site web peut utiliser une base de données qui n’est pas référencée sur son hébergement web ;
- le code source peut comporter des références à l’infrastructure (lien absolu comportant le numéro du filerz, le nom du cluster, le nom des serveurs de bases de données…).
Vous connaissez maintenant l’ensemble des contraintes opérationnelles et techniques liées au projet de migration de datacenter. Dans le prochain article, nous parlerons des différents scénarios de migration que nous avons envisagés et de celui retenu.
À bientôt !
Engineering manager on webhosting