
LLM (Large Language Model) has undoubtedly been one of the most buzzing topics over the past two years, since the release of ChatGPT by OpenAI.
𝗧𝗵𝗲 𝗕𝗮𝘀𝗶𝗰𝘀 𝗼𝗳 𝗟𝗟𝗠𝘀
Large Language Models are essentially sophisticated AI systems designed to understand and generate human-like text. What makes them large” is the sheer volume of data they’re trained on and the billions of parameters they use to capture the nuances of human language. But remember, while they can generate human-like text, machines don’t “understand” language in the way humans do. Instead, they process data as numbers, thanks to a technique called Natural Language Processing (NLP).
Today, we’ll cover the key NLP techniques used to prepare text data into a machine-readable form for use in LLMs, starting with text pre-processing.
𝗞𝗲𝘆 𝗦𝘁𝗲𝗽𝘀 𝗶𝗻 𝗧𝗲𝘅𝘁 𝗣𝗿𝗲-𝗽𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴:
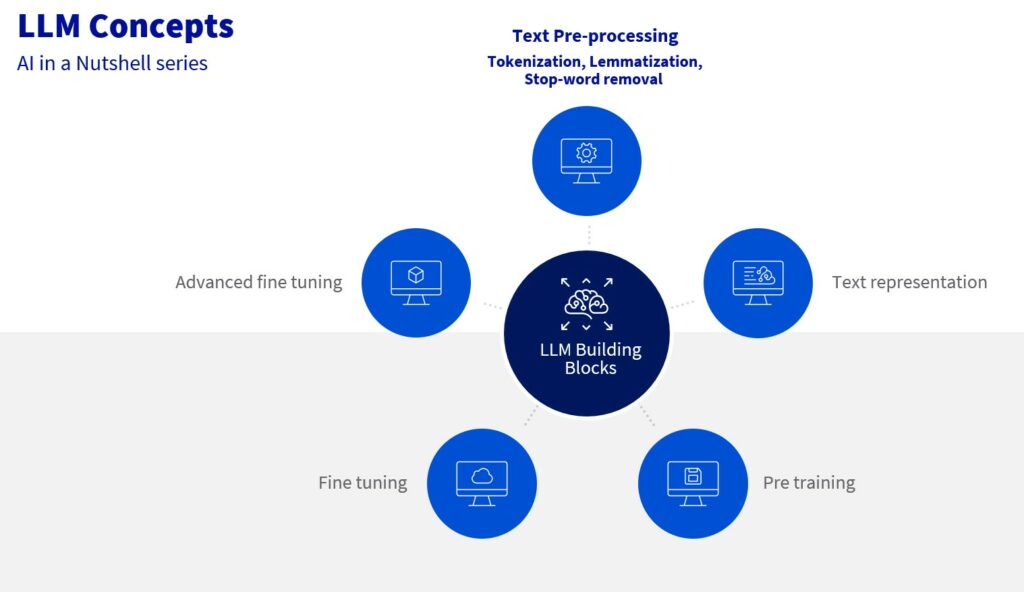
1️⃣ 𝗧𝗼𝗸𝗲𝗻𝗶𝘇𝗮𝘁𝗶𝗼𝗻
Tokenization is where it all begins. The model breaks down text into smaller units called tokens, which could be words or even sub-words. For example, the sentence “Working with NLP is tricky” becomes [“Working”, “with”, “NLP”, “is”, “tricky”, “.”]. This step is crucial because it allows the model to understand input text in a structured way that can be processed numerically.
2️⃣ 𝗦𝘁𝗼𝗽 𝘄𝗼𝗿𝗱 𝗿𝗲𝗺𝗼𝘃𝗮𝗹
Not every word in a sentence carries significant meaning. Stop words like “with” and “is” are common across many sentences but add little to the meaning. By removing these, the model can focus on the more meaningful parts of the text, enhancing efficiency and accuracy.
3️⃣ 𝗟𝗲𝗺𝗺𝗮𝘁𝗶𝘇𝗮𝘁𝗶𝗼𝗻
Lemmatization simplifies words to their base form, making it easier for the model to understand the context without getting bogged down by variations. For instance, words like “talking”, “talked”, and “talk” all get reduced to their root form “talk.
We are then ready for the next step, which is to change the text into a form the computer can understand.
Embeddings & Vectors
Vector embeddings are one of the most fascinating and useful concepts in machine learning. They are central to many NLP, recommendation, and search algorithms.
𝗪𝗵𝗮𝘁 𝗮𝗿𝗲 𝗪𝗼𝗿𝗱 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀? 🤔
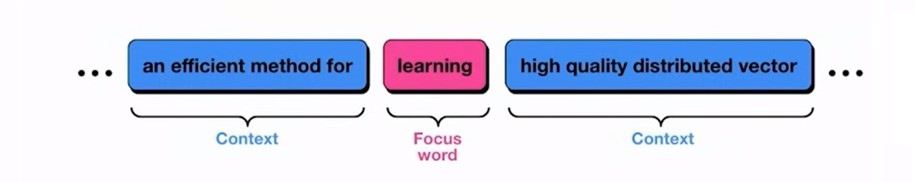
Word embeddings are a type of representation that allows words with similar meanings to have similar representations. Think of them as vectors in a high-dimensional space where each dimension captures a different aspect of the word’s meaning.
Simply put, words possessing similar meanings or often occuring together in similar contexts, will have a similar vector representation, based on how “close” or “far apart” those words are in their meanings.
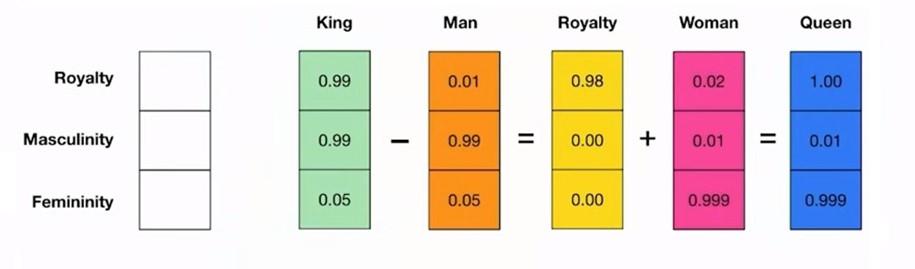
𝗔 𝗳𝗮𝗺𝗼𝘂𝘀 𝗲𝘅𝗮𝗺𝗽𝗹𝗲
Consider the equation: “king” – “man” + “women” = “queen”. This example illustrates how word embeddings can capture complex semantic relationships. The vector operations translate semantic similarity as perceived by humans into proximity in a vector space.
𝗕𝗲𝘆𝗼𝗻𝗱 𝗪𝗼𝗿𝗱𝘀: 𝗩𝗲𝗰𝘁𝗼𝗿 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀
In other words, when we represent real-world objects and concepts such as images, audio recordings, news articles, user profiles, weather patterns, and political views as vector embeddings, the semantic similarity of these objects and concepts can be quantified by how close they are to each other as points in vector spaces. Vector embedding representations are thus suitable for common machine learning tasks such as clustering, recommendation, and classification.

𝗩𝗲𝗰𝘁𝗼𝗿 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀
Once you have these embeddings, you need a way to store and query them efficiently. This is where Vector Databases come in. Vector databases are designed to handle high-dimensional data, making them perfect for storing and retrieving word embeddings.
Fine-Tuning vs. Pre-Training
🎯 What is Fine-Tuning?
Think of fine-tuning as the process of specializing in a specific domain, like a college student focusing on medicine. It builds upon the foundation of pre-trained models to adapt them for specific tasks.
🏋️♂️ Overcoming “Largeness” Challenges
LLMs are powerful but come with challenges like high computational costs, extensive training time, and the need for vast amounts of high-quality data. Fine-tuning helps overcome these obstacles by:
1️⃣ Reducing computational power requirements
2️⃣ Shortening training time from weeks or months to hours or days
3️⃣ Requiring less data, typically only a few hundred megabytes to a few gigabytes
🔧 Fine-Tuning vs. Pre-Training
While pre-training demands thousands of CPUs and GPUs, fine-tuning can be done with just a single CPU and GPU. Plus, fine-tuning takes significantly less time and data compared to pre-training!
Fine-Tuning & transfer learning
Fine-tuning a pre-trained LLM involves training it on a smaller, task-specific dataset to boost performance. But what happens when labeled data is scarce? Enter zero-shot, few-shot, and multi-shot learning—collectively known as N-shot learning techniques.
𝗧𝗿𝗮𝗻𝘀𝗳𝗲𝗿 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴
These techniques fall under the umbrella of transfer learning. Just like skills from piano lessons can be applied to learning guitar, transfer learning involves leveraging knowledge from one task to enhance performance on a related task. For LLMs, this means fine-tuning on new tasks with varying amounts of task-specific data.
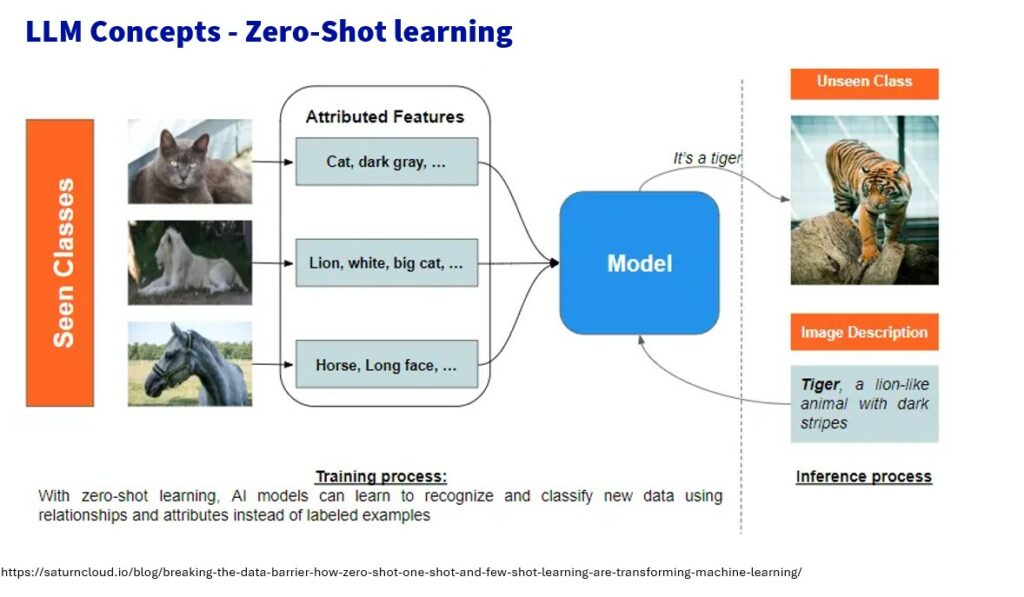
❌💉 Zero-Shot Learning
Zero-shot learning enables LLMs to tackle tasks they haven’t been explicitly trained on. Imagine a child identifying a zebra based on descriptions and knowledge of horses. LLMs use zero-shot learning to generalize knowledge to new situations without needing specific examples.
💉 Few-Shot Learning
Few-shot learning allows models to learn new tasks with minimal examples. Think of a student answering a new exam question based on prior knowledge from lectures. When only one example is used, it’s called one-shot learning.
💉💉💉 Multi-Shot Learning
Multi-shot learning is similar to few-shot learning but requires more examples. It’s like showing a model several pictures of a Golden Retriever to help it recognize the breed and generalize to similar breeds with additional examples.
These techniques make LLM more adaptable and efficient even with limited data 💡
Transformers
𝗪𝗵𝗮𝘁 𝗶𝘀 𝗮 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿?
Introduced in the paper “Attention Is All You Need” 7 years ago, transformers emphasize long-range relationships between words to generate accurate and coherent text.
𝗛𝗼𝘄 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀 𝗪𝗼𝗿𝗸
Let’s consider an example sentence: “Jane, who lives in New York and works as a software engineer, loves exploring new restaurants in the city.”
1️⃣Text Pre-processing:
The transformer breaks down the sentence into tokens (e.g., “Jane,” “who,” “lives,” etc.) and converts them into numerical form using word embeddings.
2️⃣Positional Encoding:
Adds information about the position of each word in the sequence, helping the model understand the context and relationships between distant words.
3️⃣Encoders:
Use attention mechanisms and neural networks to encode the sentence, focusing on specific words and their relationships.
4️⃣Decoders:
Process the encoded input to generate the final output, such as predicting the next word in the sequence. Why Transformers are Special
𝗟𝗼𝗻𝗴-𝗥𝗮𝗻𝗴𝗲 𝗗𝗲𝗽𝗲𝗻𝗱𝗲𝗻𝗰𝗶𝗲𝘀
Transformers excel at capturing relationships between distant words. For instance, they can understand the connection between “Jane” and “loves exploring new restaurants,” even though these words are far apart in the sentence.
𝗦𝗶𝗺𝘂𝗹𝘁𝗮𝗻𝗲𝗼𝘂𝘀 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴
Unlike traditional models that process one word at a time, transformers can handle multiple parts of the input text simultaneously. This speeds up the process of understanding and generating text.

Fostering and enhancing impactful collaborations with a diverse array of AI partners, spanning Independent Software Vendors (ISVs), Startups, Managed Service Providers (MSPs), Global System Integrators (GSIs), subject matter experts, and more, to deliver added value to our joint customers.
🏁 CAREER JOURNEY – Got a Master degree in IT in 2007 and started career as an IT Consultant
In 2010, had the opportunity to develop business in the early days of the new Cloud Computing era.
In 2016, started to witness the POWER of Partnerships & Alliances to fuel business growth, especially as we became the main go-to MSP partner for healthcare French projects from our hyperscaler.
Decided to double down on this approach through various partner-centric positions: as a managed service provider or as a cloud provider, for Channels or for Tech alliances.
➡️ Now happy to lead an ECOSYSTEM of AI players each bringing high value to our joint customers.